Artificial-Intelligence
Question 1 |
Consider the statement below.
A person who is radical (R) is electable (E) if he/she is conservative (C), but otherwise is not electable.
Few probable logical assertions of the above sentence are given below.,
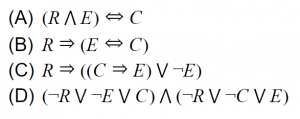
Which of the above logical assertions are true?
Choose the correct answer from the options given below:
Which of the above logical assertions are true?
Choose the correct answer from the options given below:
(B) only | |
(C) only | |
(A) and (C) only | |
(B) and (D) only |
Question 1 Explanation:
1. (R ∧E) ↔C
This is not equivalent. It says that all (and only) conservatives are radical and electable.
2. R →(E ↔C)
This one is equivalent. if a person is a radical then they are electable if and only if they are conservative.
3. R →((C →E) ∨¬E)
This one is vacuous. It’s equivalent to ¬R ∨ (¬C ∨ E ∨ ¬E), which is true in all interpretations.
4.R ⇒ (E ⇐⇒ C) ≡ R ⇒ ((E ⇒ C) ∧ (C ⇒ E))
≡ ¬R ∨ ((¬E ∨ C) ∧ (¬C ∨ E))
≡ (¬R ∨ ¬E ∨ C) ∧ (¬R ∨ ¬C ∨ E))
This is not equivalent. It says that all (and only) conservatives are radical and electable.
2. R →(E ↔C)
This one is equivalent. if a person is a radical then they are electable if and only if they are conservative.
3. R →((C →E) ∨¬E)
This one is vacuous. It’s equivalent to ¬R ∨ (¬C ∨ E ∨ ¬E), which is true in all interpretations.
4.R ⇒ (E ⇐⇒ C) ≡ R ⇒ ((E ⇒ C) ∧ (C ⇒ E))
≡ ¬R ∨ ((¬E ∨ C) ∧ (¬C ∨ E))
≡ (¬R ∨ ¬E ∨ C) ∧ (¬R ∨ ¬C ∨ E))
Question 2 |
Consider the following argument with premise

This is a valid argument. | |
Steps (C) and (E) are not correct inferences | |
Steps (D) and (F) are not correct inferences | |
Step (G) is not a correct inference |
Question 3 |
Given below are two statements:
Statement I: A genetic algorithm is a stochastic hill climbing search in which a large population of states is maintained.
Statement II: In a nondeterministic environment, agents can apply AND-OR search to generate containing plans that reach the goal regardless of which outcomes occur during execution.
In the light of the above statements, choose the correct answers from the options given below
Both Statement I and Statement II are true | |
Both Statement I and Statement II are false | |
Statement I is correct but Statement II is false
| |
Statement I is incorrect but Statement II is true |
Question 3 Explanation:
In a genetic algorithm, a population of candidate solutions (called individuals, creatures, or phenotypes) to an optimization problem is evolved toward better solutions. Each candidate solution has a set of properties (its chromosomes or genotype) which can be mutated and altered; traditionally, solutions are represented in binary as strings of 0s and 1s, but other encodings are also possible.
In nondeterministic environments, percepts tell the agent which of the possible outcomes has actually occurred.Solutions for nondeterministic problems can contain nested if-then-else statements that create a tree rather than a sequence of actions
In nondeterministic environments, percepts tell the agent which of the possible outcomes has actually occurred.Solutions for nondeterministic problems can contain nested if-then-else statements that create a tree rather than a sequence of actions
Question 4 |
Which of the following statements are true?
A) Minimax search is breadth-first; it processes all the nodes at a level before moving to a node in the next level.
B) The effectiveness of the alpha-beta pruning is highly dependent on the order in which the states are examined.
C) The alpha-beta search algorithm computes the same optimal moves as the minimax algorithm.
D) Optimal play in games of imperfect information does not require reasoning about the current and future belief states of each player.
Choose the correct answer from the options given below:
(A) and (C) only | |
(A) and (D) only | |
(B) and (C) only | |
(C) and (D) only |
Question 4 Explanation:
Minimax is a decision rule used in artificial intelligence, decision theory, game theory, statistics, and philosophy for minimizing the possible loss for a worst case (maximum loss) scenario.
Optimal decision in deterministic, perfect information games
Idea : choose the move resulting in the highest minimax value
Completeness: Yes if the tree is finite
Optimality: Yes, against an optimal opponent.
Time Complexity: O(bm)
Space Complexity: O(bm) – depth first exploration.
Hence Statement (A) is true.
Statement (B):
Alpha Bound of J:
→ The max current The max current val of all MAX ancestors of J of all MAX ancestors of J
→ Exploration of a min node, J, Exploration of a min node, J, is stopped when its value is stopped when its value equals or falls below alpha. equals or falls below alpha.
→ In a min node, we n node, we update beta update beta
Beta Bound of J:
→ The min current The min current val of all MIN ancestors of J of all MIN ancestors of J
→ Exploration of a Exploration of a max node, J ax node, J, is stopped when its stopped when its value equals or exceeds beta equals or exceeds beta
→ In a max node, we update a ax node, we update alpha
Pruning does not affect the final result
Does ordering affect the pruning process?
Best case O(bm/2)
Random (instead of best first search) - O(b3m/4)
Hence statement (B) is false.
Statement C: This statement is true.
Statement D: This statement is false because past exploration information is used from transposition tables.
Optimal decision in deterministic, perfect information games
Idea : choose the move resulting in the highest minimax value
Completeness: Yes if the tree is finite
Optimality: Yes, against an optimal opponent.
Time Complexity: O(bm)
Space Complexity: O(bm) – depth first exploration.
Hence Statement (A) is true.
Statement (B):
Alpha Bound of J:
→ The max current The max current val of all MAX ancestors of J of all MAX ancestors of J
→ Exploration of a min node, J, Exploration of a min node, J, is stopped when its value is stopped when its value equals or falls below alpha. equals or falls below alpha.
→ In a min node, we n node, we update beta update beta
Beta Bound of J:
→ The min current The min current val of all MIN ancestors of J of all MIN ancestors of J
→ Exploration of a Exploration of a max node, J ax node, J, is stopped when its stopped when its value equals or exceeds beta equals or exceeds beta
→ In a max node, we update a ax node, we update alpha
Pruning does not affect the final result
Does ordering affect the pruning process?
Best case O(bm/2)
Random (instead of best first search) - O(b3m/4)
Hence statement (B) is false.
Statement C: This statement is true.
Statement D: This statement is false because past exploration information is used from transposition tables.
Question 5 |
Given below are two statements:
If two variables V1and V2 are used for clustering, then consider the following statements for k means clustering with k=3:-
Statement I: If V1and V2 have correlation of 1 the cluster centroid will be in straight line.
Statement II: If V1and V2 have correlation of 0 the cluster centroid will be in straight line.
In the light of the above statements, choose the correct answer from the options given below
Both Statement I and Statement II are true | |
Both Statement I and Statement II are false | |
Statement I is correct but Statement II is false | |
Statement I is incorrect but Statement II is true |
Question 5 Explanation:
If the correlation between the variables V1 and V2 is 1, then all the data points will be in a straight line. So, all the three cluster centroids will form a straight line as well.
Question 6 |
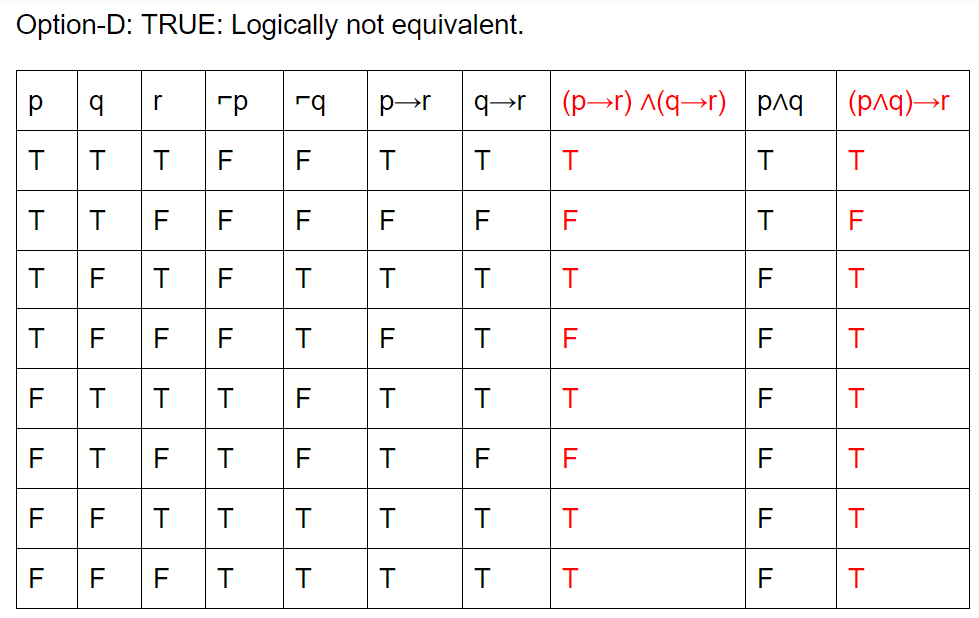
Which of the following pairs of propositions are not logically equivalent?
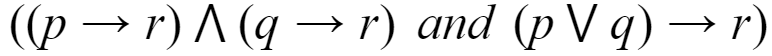 | |
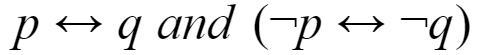 | |
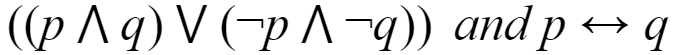 | |
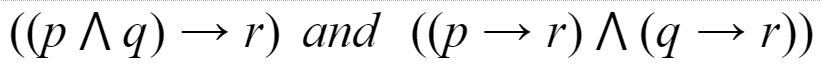 |
Question 6 Explanation:
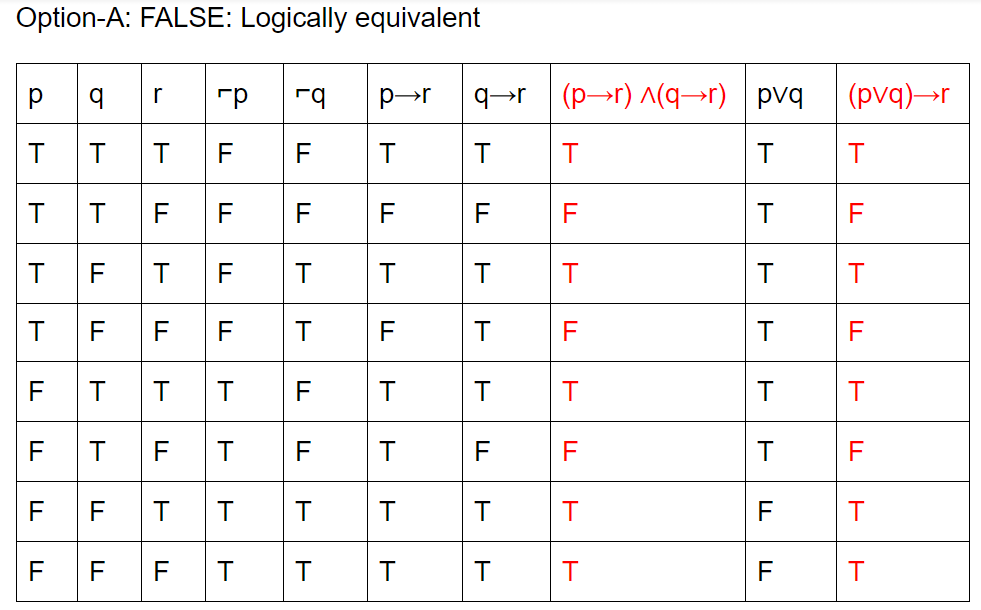
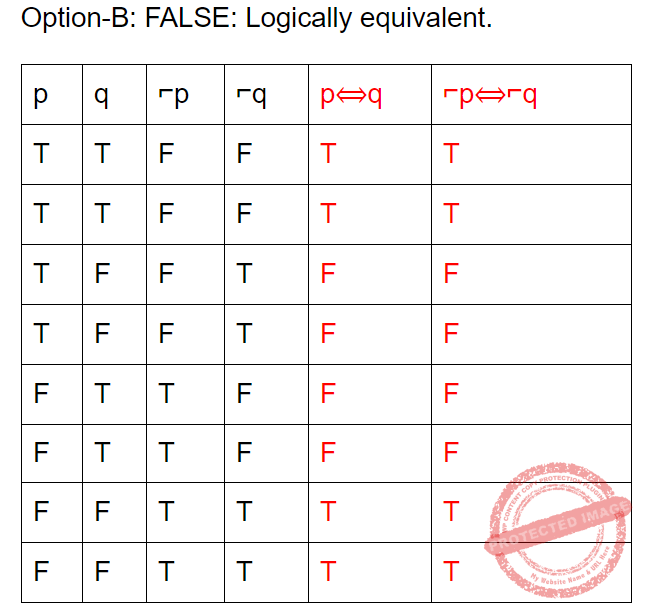
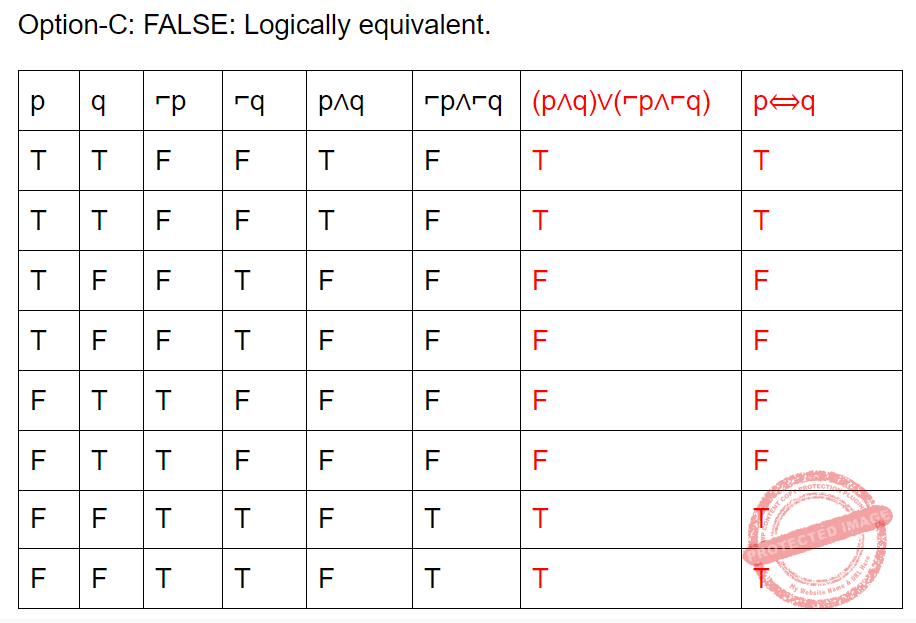
Question 7 |
Match List I with List II

Choose the correct answer from the options given below
Choose the correct answer from the options given below
A-II, B-IV, C-I, D-III
| |
A-II, B-III, C-I, D-IV | |
A-III, B-II, C-IV, D-I | |
A-III, B-IV, C-II, D-I |
Question 7 Explanation:
Greedy best-first search algorithm always selects the path which appears best at that moment. It is the combination of depth-first search and breadth-first search algorithms.
Time Complexity: The worst case time complexity of Greedy best first search is O(bm).
Space Complexity: The worst case space complexity of Greedy best first search is O(bm). Where, m is the maximum depth of the search space.
Complete: Greedy best-first search is also incomplete, even if the given state space is finite.
Optimal: Greedy best first search algorithm is not optimal.
Note:Refer the corresponding algorithms from standard sources.
Time Complexity: The worst case time complexity of Greedy best first search is O(bm).
Space Complexity: The worst case space complexity of Greedy best first search is O(bm). Where, m is the maximum depth of the search space.
Complete: Greedy best-first search is also incomplete, even if the given state space is finite.
Optimal: Greedy best first search algorithm is not optimal.
Note:Refer the corresponding algorithms from standard sources.
Question 8 |
If f(x)=x is my friend, and p(x) = x is perfect, then the correct logical translation of the statement "some of my friends are not perfect" is _____.
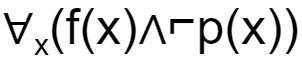 | |
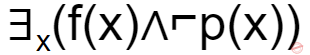 | |
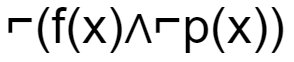 | |
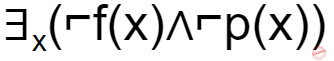 |
Question 8 Explanation:
Input:
f(x)=x is my friend
p(x) = x is perfect
So, they are asking about SOME. Finally, outer most parentheses will get SOME.
So, based on this we will eliminate 2 options.
They are given conditions like NOT perfect. So, we get ⌐p(x).
The final condition is ∃x(f(x)∧⌐p(x))
f(x)=x is my friend
p(x) = x is perfect
So, they are asking about SOME. Finally, outer most parentheses will get SOME.
So, based on this we will eliminate 2 options.
They are given conditions like NOT perfect. So, we get ⌐p(x).
The final condition is ∃x(f(x)∧⌐p(x))
Question 9 |
Match List I with List II
List I List II
A) Branch-and-bound (I) Keeps track of all partial paths which can be can be a candidate for further exploration.
B) Steepest-ascent hill climbing (II) Detects difference between current state and goal state.
C) Constraint satisfaction (III) Discovers problem state(s) that satisfy a set of constraints.
D) Means-end-analysis (IV) Considers all moves from current state and selects the best move.
Choose the correct answer from the options given below:
A-I, B-IV, C-III, D-II | |
A-I, B-II, C-III, D-IV
| |
A-II, B-I, C-III, D-IV | |
A-II, B-IV, C-III, D-I |
Question 9 Explanation:
Branch-and-bound→ Keep track of all partial paths which can be a candidate for further exploration.
Steepest-ascent hill climbing → Considers all moves from current state and selects the best move.
Constraint satisfaction → Discovers problem state(s) that satisfy a set of constraints.
Means-end-analysis → Detects difference between current state and goal state.
Steepest-ascent hill climbing → Considers all moves from current state and selects the best move.
Constraint satisfaction → Discovers problem state(s) that satisfy a set of constraints.
Means-end-analysis → Detects difference between current state and goal state.
Question 10 |
Which of the following is NOT true in problem solving in artificial intelligence?
Implements heuristic search techniques | |
Solution steps are not explicit | |
Knowledge is imprecise | |
it works on or implements repetition mechanism |
Question 11 |
Let R and S be two fuzzy relations defined as:

Then, the resulting relation, T, which relates elements of universe X to elements of universe Z using max-min composition is given by
Then, the resulting relation, T, which relates elements of universe X to elements of universe Z using max-min composition is given by
 | |
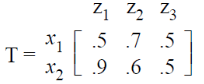 | |
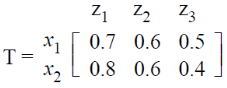 | |
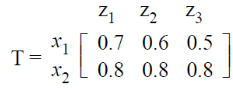 |
Question 11 Explanation:

Question 12 |
Compute the value of adding the following two fuzzy integers :
A = {(0.3, 1), (0.6, 2), (1, 3), (0.7, 4), (0.2, 5)}
B = {(0.5, 11), (1, 12), (0.5, 13)}
Where fuzzy addition is defined as μA+B (z)= maxx + y = z(min (μA(x), μB(x)))
Then, f (A + B) is equal to
A = {(0.3, 1), (0.6, 2), (1, 3), (0.7, 4), (0.2, 5)}
B = {(0.5, 11), (1, 12), (0.5, 13)}
Where fuzzy addition is defined as μA+B (z)= maxx + y = z(min (μA(x), μB(x)))
Then, f (A + B) is equal to
{(0.5, 12), (0.6, 13), (1, 14), (0.7, 15), (0.7, 16), (1, 17), (1, 18)} | |
{(0.5, 12), (0.6, 13), (1, 14), (1, 15), (1, 16), (1, 17), (1, 18)} | |
{(0.3, 12), (0.5, 13), (0.5, 14), (1, 15), (0.7, 16), (0.5, 17), (0.2, 18)} | |
{(0.3, 12), (0.5, 13), (0.6, 14), (1, 15), (0.7, 16), (0.5, 17), (0.2, 18)} |
Question 12 Explanation:

Question 13 |
A perceptron has input weights W1 = – 3.9 and W2 = 1.1 with threshold value T = 0.3. What output does it give for the input x1 = 1.3 and x2 = 2.2 ?
– 2.65 | |
– 2.30 | |
0 | |
1 |
Question 13 Explanation:

Question 14 |
How does randomized hill-climbing choose the next move each time?
It generates a random move from the moveset, and accepts this move. | |
It generates a random move from the whole state space, and accepts this move. | |
It generates a random move from the moveset, and accepts this move only if this move improves the evaluation function. | |
It generates a random move from the whole state space, and accepts this move only if this move improves the evaluation function. |
Question 14 Explanation:
Randomized hill-climbing generates a random move from the moveset, and accepts this move only if this move improves the evaluation function.
Question 15 |
Consider the following game tree in which root is a maximizing node and children are visited left to right. What nodes will be pruned by the alpha-beta pruning ?
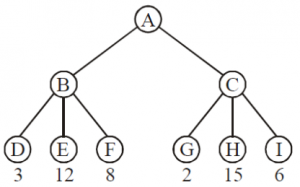
I | |
HI | |
CHI | |
GHI |
Question 16 |
Consider a 3-puzzle where, like in the usual 8-puzzle game, a tile can only move to an adjacent empty space. Given the initial state
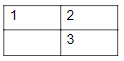
which of the following state cannot be reached?
which of the following state cannot be reached?
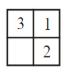 | |
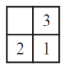 | |
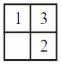 | |
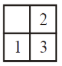 |
Question 16 Explanation:
This problem, we can solve it by presence of mind.
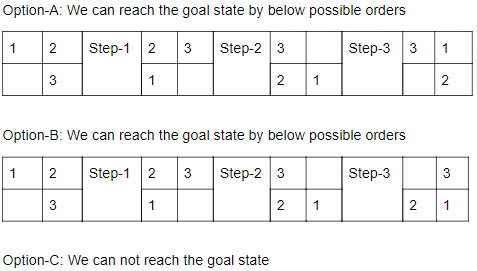
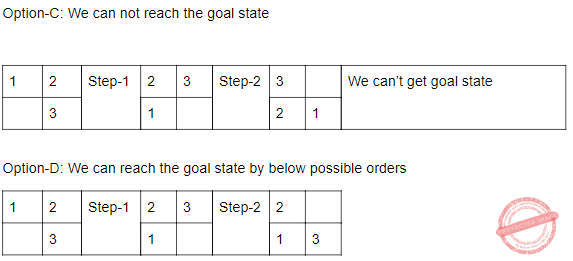
Question 17 |
A software program that infers and manipulates existing knowledge in order to generate new knowledge is known as
Data dictionary | |
Reference mechanism | |
Inference engine | |
Control strategy |
Question 17 Explanation:
→ A software program that infers and manipulates existing knowledge in order to generate new knowledge is known as inference engine.
→ Inference engines work primarily in one of two modes either special rule or facts: forward chaining and backward chaining.
→ Forward chaining starts with the known facts and asserts new facts.
→ Backward chaining starts with goals, and works backward to determine what facts must be asserted so that the goals can be achieved
→ Inference engines work primarily in one of two modes either special rule or facts: forward chaining and backward chaining.
→ Forward chaining starts with the known facts and asserts new facts.
→ Backward chaining starts with goals, and works backward to determine what facts must be asserted so that the goals can be achieved
Question 18 |

1 | |
2 | |
3 | |
4 |
Question 19 |
Which of the following is not a parent selection technique used in genetic algorithm implementations?
Radial | |
Tournament | |
Boltzmann | |
Rank |
Question 20 |
Given that η refers to the learning rate and xᵢ refers to the iᵗʰ input to the neuron, which of the following most suitably describes the weight updation rule of a Kohonen Self-Organizing Map (SOM)? (where j refers to the jᵗʰ neuron in the lattice)

1 | |
2 | |
3 | |
4 |
Question 21 |
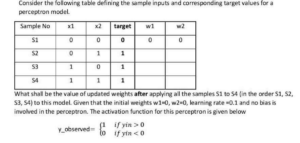
w₁ = 0.1, w₂ = 0.1
| |
w₁ = 0.0, w₂ = 0.2 | |
w₁ = 0.0, w₂ = 0.1 | |
w₁ = 0.2, w₂ = 0.2 |
Question 22 |
Consider the following steps used by a knowledge base designer to represent a world:
A. Selects atoms to represent propositions
B. Ask questions about intended interpretation
C. Choose a task domain
D. Axiomatizing the domain
Choose the correct answer from the options given below:
A. Selects atoms to represent propositions
B. Ask questions about intended interpretation
C. Choose a task domain
D. Axiomatizing the domain
Choose the correct answer from the options given below:
C → A → D → B
| |
C → A → B → D
| |
B → C → A → D
| |
A → C → B → D
|
Question 23 |
Consider the following steps involved in the application of a Genetic Algorithm for a problem:
A. Select a pair of parents from the population
B. Apply mutation at each locus with probability Pm
C. Calculate fitness of each member of the population
D. Apply crossover with probability Pc to form offsprings
Choose the correct answer from the options given below describing the correct order of the above steps:
A. Select a pair of parents from the population
B. Apply mutation at each locus with probability Pm
C. Calculate fitness of each member of the population
D. Apply crossover with probability Pc to form offsprings
Choose the correct answer from the options given below describing the correct order of the above steps:
A → C → B → D
| |
C → A → D → B
| |
C → A → B → D | |
A → D → B → C
|
Question 24 |
Consider the following statements regarding Agent systems
A. Agent system comprises of an agent and an environment on which it acts
B. The controller part of an agent receives percepts from its body and sends commands to the environment
C. Agents act in the world through actuators which are non-noisy and always reliable.
D. The actuators of an agent convert stimuli into percepts
Choose the correct answer from the options given below:
A. Agent system comprises of an agent and an environment on which it acts
B. The controller part of an agent receives percepts from its body and sends commands to the environment
C. Agents act in the world through actuators which are non-noisy and always reliable.
D. The actuators of an agent convert stimuli into percepts
Choose the correct answer from the options given below:
A, B Only
| |
B, D Only
| |
C, D Only | |
B, C, D Only |
Question 25 |
Consider the following statements regarding STRIPS representation of a Planning problem
A. STRIPS is a Feature-centric representation
B. The features describing state of the world are divided into Primitive and Derived
C. The STRIPS representation of the action comprises of Precondition and Effect
D. STRIPS can directly define conditional effects.
Choose the correct answer from the options given below:
A. STRIPS is a Feature-centric representation
B. The features describing state of the world are divided into Primitive and Derived
C. The STRIPS representation of the action comprises of Precondition and Effect
D. STRIPS can directly define conditional effects.
Choose the correct answer from the options given below:
A, C Only
| |
B, C Only | |
A, D Only
| |
B, C, D Only
|
Question 26 |
Which of the following is not a component of the classic Planning Definition?
Init
| |
Domain
arti | |
Action | |
Goal |
Question 27 |
Which of the following are correct for the neural network?
A. The training time depends upon the size of network.
B. Neural network can be simulated on the conventional computer.
C. Neural network mimic the same way as that of the humans brain.
D. A neural network include feedback.
Choose the correct answer from the options given below:
A. The training time depends upon the size of network.
B. Neural network can be simulated on the conventional computer.
C. Neural network mimic the same way as that of the humans brain.
D. A neural network include feedback.
Choose the correct answer from the options given below:
A and B only | |
A, C and D only | |
A, B and C only | |
A and C only |
Question 28 |
Match the LIST-I with LIST-II
Choose the correct answer from the options given below:
| LIST-I | LIST-II | ||
| A | Decision Tree | I | Delta Learning Rule |
| B | Supervised Learning | II | Self Organizing Map |
| C | Artificial Neural Network | III | C4.5 Algorithm |
| D | Instance base Learning | IV | Non-linear Regression Algorithm |
Choose the correct answer from the options given below:
A-I,B-II, C-III, D-IV
| |
A-II, B-III, C-IV, D-I | |
A-III, B-IV, C-I, D-II | |
A-IV, B-I, C-II, D-III |
Question 29 |
Which one of the following is not related to the feed forward networks on the Backpropagation
Algorithm ?
Boolean function | |
Continuous function | |
Arbitrary function | |
Greedy function |
Question 30 |
Definition's of ____ organized into following four categories namely, Thinking Humanly, Thinking Rationally, Acting Humanly, Acting Rationally
Machine Learning | |
Deep Learning | |
Artificial Intelligence | |
Neural Network |
Question 31 |
Match List -I with List - II
List - I List - II
(A) The activation function (I)is called the delta rule.
(B) The learning method of perceptron (II)is one of the key components of the perceptron as in the most common neural network architecture.
(C) Areas of application of artificial neural network include (III)is always boolean like a switch.
(D) The output of the perceptron (IV)system identification and control.
Choose the correct answer from the options given below :
List - I List - II
(A) The activation function (I)is called the delta rule.
(B) The learning method of perceptron (II)is one of the key components of the perceptron as in the most common neural network architecture.
(C) Areas of application of artificial neural network include (III)is always boolean like a switch.
(D) The output of the perceptron (IV)system identification and control.
Choose the correct answer from the options given below :
(A)-(II),(B)-(IV),(C)-(III),(D)-(I)
| |
(A)-(IV),(B)-(III),(C)-(II),(D)-(I) | |
(A)-(II),(B)-(I),(C)-(IV),(D)-(III)
| |
(A)-(III),(B)-(IV),(C)-(II),(D)-(I)
|
Question 32 |
Match List - I with List - II
List - I
(A)Natural language processing
(B)Reinforcement learning
(C)Support vector machine
(D)Expert system
List - II
I) A method of training algorithm by rewarding desired behaviour and/or punishing undesired one.
II)System designed to emulate the making abilities of a human expert.
III) A branch of AI focused on understanding and generating human language.
IV) A machine learning technique that finds the hyper plane that best separates different class in a feature space.
Choose the correct answer from the options given below :
List - I
(A)Natural language processing
(B)Reinforcement learning
(C)Support vector machine
(D)Expert system
List - II
I) A method of training algorithm by rewarding desired behaviour and/or punishing undesired one.
II)System designed to emulate the making abilities of a human expert.
III) A branch of AI focused on understanding and generating human language.
IV) A machine learning technique that finds the hyper plane that best separates different class in a feature space.
Choose the correct answer from the options given below :
(A)-(I),(B)-(II),(C)-(IV),(D)-(III)
| |
(A)-(III),(B)-(II),(C)-(I),(D)-(IV)
| |
(A)-(III),(B)-(I),(C)-(IV),(D)-(II) | |
(A)-(II),(B)-(IV),(C)-(III),(D)-(I)
|
Question 33 |
Arrange the following steps in a proper sequence for the process of training a neural network.
A)Weight initialization
B)Feed forward
C)Back Propagation
D)Loss Calculation
E)Weight Update
Choose the correct answer from the options given below:
A)Weight initialization
B)Feed forward
C)Back Propagation
D)Loss Calculation
E)Weight Update
Choose the correct answer from the options given below:
(A),(B),(D),(C),(E)
| |
(D),(B),(A),(C),(E)
| |
(A),(C),(D),(B),(E)
| |
(E),(C),(B),(D),(A) |
Question 34 |
Arrange the following steps in the proper sequence involved in a Genetic Algorithm :
A)Selection
B)Initialization
C)Crossover
D)Mutation
E)Evaluation
Choose the correct answer from the options given below :
A)Selection
B)Initialization
C)Crossover
D)Mutation
E)Evaluation
Choose the correct answer from the options given below :
(A),(B),(C),(D),(E)
| |
(E),(A),(B),(D),(C)
| |
(B),(E),(C),(A),(D)
| |
(A),(C),(B),(D),(E) |
Question 35 |
Read the below passage and answer the question.
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Artificial Neutral Networks (ANNs) are inspired by :
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Artificial Neutral Networks (ANNs) are inspired by :
Quantum mechanics
| |
Human brain’s neural network
| |
Computer Hardware architecture | |
Genetic algorithm
|
Question 36 |
Read the below passage and answer the question.
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Which of the following layers may be more than one in numbers ?
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Which of the following layers may be more than one in numbers ?
Input layer | |
Hidden layer | |
Output layer | |
Physical layer
|
Question 37 |
Read the below passage and answer the question.
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Which of the following is/are the application area(s) of ANN ?
A)Natural Language Processing
B)Image Processing
C)Pattern Recognition
D)Speech Recognition
Choose the correct answer from the options given below
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
Which of the following is/are the application area(s) of ANN ?
A)Natural Language Processing
B)Image Processing
C)Pattern Recognition
D)Speech Recognition
Choose the correct answer from the options given below
(A) and (B) only | |
(B) and (C) only
| |
(A),(B) and (C) only | |
(A),(B),(C) and (D)
|
Question 38 |
Read the below passage and answer the question.
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
What is the role of weights in an ANN ?
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
What is the role of weights in an ANN ?
To store data | |
To adjust and improve network performance | |
To control the speed | |
To secure the network |
Question 39 |
Read the below passage and answer the question.
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
What is the role of Back Propagation Algorithm ?
Artificial Neutral Networks (ANNs) are computational models inspired by the human brain’s neural networks. They consist of inter-connected nodes, or neurons, organized into layers : an input layers, one or more hidden layers and an output layers. Each connection between neurons has a weight that adjusts as learning progress allowing the network to adopt and improve its performance. ANNs are particularly effective in recognizing patterns making them valuable for tasks such as image and speech recognition, Natural language processing and predictive analytics. Learning in ANNs typically involves training algorithms like back propagation, which minimize the error by adjusting the weights. As a subset of machine learning, ANNs have revolutionized the field of artificial intelligence by providing solutions to complex problems that traditional algorithms struggle with.
What is the role of Back Propagation Algorithm ?
To reduce error
| |
To secure network | |
To control speed of data
| |
To add different layers |
Question 40 |
Which of the following is not a solution representation in a genetic algorithm?
Binary valued
| |
Real valued
| |
Permutation
| |
Combinations |
Question 40 Explanation:
"Combinations" is not typically a direct solution representation in a genetic algorithm. In genetic algorithms, the common solution representations include:
Binary Valued: Where each gene in an individual is represented as a binary value (0 or 1).
Real Valued: Where each gene in an individual is represented as a real number, often within a specific range.
Permutation: Where the genes represent a permutation or ordering of elements. This is often used for problems like the Traveling Salesman Problem.
"Combinations" as a direct representation is not commonly used in genetic algorithms. Instead, it might be implemented using other representations like binary, real-valued, or permutation depending on the specific problem being solved.
Question 41 |
Consider the following statements
A. C-fuzzy means cluster is supervised method of learning
B. PCA is used for dimension reduction
C. Apriori is not a supervised technique
D. When a machine learning model becomes so specially tuned to its exact input data that it fails to generalize to other similar data it is called underfitting
Choose the correct answer from the options given below
A. C-fuzzy means cluster is supervised method of learning
B. PCA is used for dimension reduction
C. Apriori is not a supervised technique
D. When a machine learning model becomes so specially tuned to its exact input data that it fails to generalize to other similar data it is called underfitting
Choose the correct answer from the options given below
A and B
| |
B and C
| |
C and D
| |
D and A
|
Question 41 Explanation:
Statement B is correct. PCA (Principal Component Analysis) is indeed used for dimension reduction in machine learning and data analysis.
Statement C is also correct. Apriori is a frequent itemset mining algorithm used in association rule learning and is not a supervised technique in machine learning.
Statements A and D are not correct:
Statement A is incorrect. "C-fuzzy" is not a standard term in machine learning, and the statement doesn't accurately describe a supervised method of learning.
Statement D is also incorrect. "Underfitting" is when a model is too simple and fails to capture the underlying patterns in data. It is the opposite of overfitting, which is when a model becomes too specialized to its training data.
Question 42 |
Given below are two statements:
Statement I: Fuzzifier is a part of a fuzzy system
Statement Ii: Inference engine is a part of fuzzy system
In the ligt of the above statements, choose the most appropriate answer from the options given below
Statement I: Fuzzifier is a part of a fuzzy system
Statement Ii: Inference engine is a part of fuzzy system
In the ligt of the above statements, choose the most appropriate answer from the options given below
Both statement I and Statement II are correct
| |
Both statement I and Statement II are incorrect
| |
Statement I is correct but Statement II is incorrect
| |
Statement I is incorrect but Statement II is correct |
Question 42 Explanation:
Statement I correctly identifies that a "fuzzifier" is a component of a fuzzy system. A fuzzifier is responsible for converting crisp (non-fuzzy) inputs into fuzzy sets.
Statement II is also correct because an "inference engine" is a crucial component of a fuzzy system. It's responsible for making decisions and performing reasoning based on fuzzy logic rules and inputs.
Both statements are accurate, and there is no conflict between them.
Question 43 |
Which of the following is not a mutation operator in a genetic algorithm?
A.Random resetting
B.Scramble
C.Inversion
D.Difference
Choose the correct answer from the options given below
A.Random resetting
B.Scramble
C.Inversion
D.Difference
Choose the correct answer from the options given below
A and B only
| |
B and D only
| |
C and D only
| |
D only |
Question 43 Explanation:
A genetic algorithm typically uses various mutation operators to introduce diversity into the population. Here's an explanation of each of the options:
A. Random Resetting: Random resetting is a mutation operator where one or more genes in an individual's chromosome are randomly changed or reset to new random values. It is a valid mutation operator in genetic algorithms.
B. Scramble: The scramble operator involves shuffling or permuting a subset of genes within a chromosome. It is a valid mutation operator in genetic algorithms.
C. Inversion: The inversion operator reverses the order of a subset of genes within a chromosome. It is a valid mutation operator in genetic algorithms.
D. Difference: "Difference" is not a standard mutation operator in genetic algorithms. While operators like "random resetting," "scramble," and "inversion" are commonly used, "difference" is not a recognized mutation operator in this context.
So, the correct answer is D only because "Difference" is not a mutation operator commonly used in genetic algorithms.
Question 44 |
Which of the following is not a property of a good system for representation of knowledge in a particular domain?
Presentation adequacy
| |
Inferential adequacy
| |
Inferential efficiency
| |
Acquisitional efficiency |
Question 44 Explanation:
The property that is not typically considered a property of a good system for the representation of knowledge in a particular domain is "Presentation adequacy."
Presentation adequacy refers to how well the system's knowledge representation can be presented and understood by humans. While it's important to have a representation that can be comprehended by humans, the primary properties often associated with a good knowledge representation system are:
Inferential Adequacy: The system's ability to support reasoning and inference within the domain. It should be able to draw meaningful conclusions and make inferences based on the represented knowledge.
Inferential Efficiency: How efficiently the system can perform reasoning and inference. A good system should allow for efficient processing and deduction of new knowledge from the existing representation.
Acquisitional Efficiency: How efficiently the system can acquire or learn new knowledge and integrate it into the existing representation. This relates to the ease of updating and expanding the knowledge base.
While presentation adequacy is important for human understanding, it's not traditionally considered one of the core properties of a knowledge representation system. Instead, it's often viewed as an interface or display issue, focusing on how well the representation can be communicated to users.
Question 45 |
Which is not a component of the natural language understanding process?
Morphological analysis
| |
Semantic analysis
| |
Pragmatic analysis
| |
Meaning analysis |
Question 45 Explanation:
Meaning analysis is not typically considered a distinct component of the natural language understanding (NLU) process. Instead, it is often encompassed within the broader category of semantic analysis.
The key components of the NLU process include:
Morphological Analysis: This component deals with the analysis of word structure, including breaking words into meaningful units (morphemes), inflections, and word forms.
Semantic Analysis: This is the component responsible for understanding the meaning of words, phrases, and sentences. It involves determining the relationships between words and extracting the intended meaning.
Pragmatic Analysis: Pragmatics focuses on the interpretation of language in context, including factors like speech acts, implicatures, and understanding the intentions and presuppositions of the speaker.
So, "Meaning analysis" is usually encompassed within "Semantic analysis," and all the other components listed are integral parts of the natural language understanding process.
Question 46 |
Given below are two statements: one is labelled as Assertion A and the other is labelled as Reason R.
Assertion A: Dendral is an expert system
Reason R: The rationality of an agent is not related to its reaction to the environment.
In the light of the above statements. choose the correct answer from the options given below.
Assertion A: Dendral is an expert system
Reason R: The rationality of an agent is not related to its reaction to the environment.
In the light of the above statements. choose the correct answer from the options given below.
Both A and R are true and R is the correct explanation of A
| |
Both A and R are true, but R is NOT the correct explanation of A
| |
A is true but R is false
| |
A is false but R is true |
Question 47 |
Overfitting is expected when we observe that?
With training iterations error on training set as well as test set decreases | |
With training iterations error on training set decreases but test set increases | |
With training iterations error on training set as well as test set increases | |
With training iterations training set as well as test error remains constant |
Question 48 |
The A* algorithm is optimal when,
It always finds the solution with the lowest total cost if the heuristic 'h' is admissible. | |
Always finds the solution with the highest total cost if the heuristic 'h' is admissible. | |
Finds the solution with the lowest total cost if the heuristic 'h' is not admissible. | |
It always finds the solution with the highest total cost if the heuristic 'h' is not admissible. |
Question 49 |
Which Artificial intelligence technique enables the computers to understand the associations and relationships between objects & Events?
Heuristic Processing | |
Cognitive Science | |
Relative Symbolism | |
Pattern matching |
Question 50 |
What does the values of alpha-beta search get updated?
Along the path of search | |
Initial state itself | |
At the end | |
None of these |
There are 50 questions to complete.