Pipelining
Question 1 |
Consider the following sequence of 8 instructions:
ADD, MUL, ADD, MUL, ADD, MUL, ADD, MUL
Assume that every MUL instruction is data-dependent on the ADD instruction just before it and every ADD instruction (except the first ADD) is data- dependent on the MUL instruction just before it. The Speedup is defined as follows:
Assume that every MUL instruction is data-dependent on the ADD instruction just before it and every ADD instruction (except the first ADD) is data-dependent on the MUL instruction just before it. The Speedup is defined as follows:
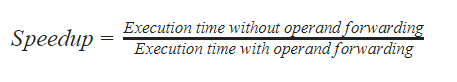
The Speedup achieved in executing the given instruction sequence on the pipelined processor (rounded to 2 decimal places) is ________.
1.875 |

Question 2 |
Consider a non-pipelined processor operating at 2.5 GHz. It takes 5 clock cycles to complete an instruction. You are going to make a 5-stage pipeline out of this processor. Overheads associated with pipelining force you to operate the pipelined processor at 2 GHz. In a given program, assume that 30% are memory instructions, 60% are ALU instructions and the rest are branch instructions. 5% of the memory instructions cause stalls of 50 clock cycles each due to cache misses and 50% of the branch instructions cause stalls of 2 cycles each. Assume that there are no stalls associated with the execution of ALU instructions. For this program, the speedup achieved by the pipelined processor over the non-pipelined processor (round off to 2 decimal places) is _____.
2.16 |
It is given that each instruction takes 5 clock cycles to execute in the non-pipelined architecture, so time taken to execute each instruction = 5 * 0.4 = 2ns
In the pipelined architecture the clock cycle time = 1/2G = 0.5 ns
In the pipelined architecture there are stalls due to memory instructions and branch instructions.
In the pipeline, the updated clocks per instruction CPI = (1 + stall frequency due to memory operations * stalls of memory instructions + stall frequency due to branch operations * stalls due to branch instructions)
Out of the total instructions , 30% are memory instructions. Out of those 30%, only 5% cause stalls of 50 cycles each.
Stalls per instruction due to memory operations = 0.3*0.05*50 = 0.75
Out of the total instructions 10% are branch instructions. Out of those 10% of instructions 50% of them cause stalls of 2 cycles each.
Stalls per instruction due to branch operations = 0.1*0.5*2 = 0.1
The updated CPI in pipeline = 1 + 0.75 + 0.1 = 1.85
The execution time in the pipeline = 1.85 * 0.5 = 0.925 ns
The speed up = Time in non-pipelined architecture / Time in pipelined architecture = 2 / 0.925 = 2.16
Question 3 |
The instruction pipeline of a RISC processor has the following stages: Instruction Fetch (IF), Instruction Decode (ID), Operand Fetch (OF), Perform Operation (PO) and Writeback (WB). The IF, ID, OF and WB stages take 1 clock cycle each for every instruction. Consider a sequence of 100 instructions. In the PO stage, 40 instructions take 3 clock cycles each, 35 instructions take 2 clock cycles each, and the remaining 25 instructions take 1 clock cycle each. Assume that there are no data hazards and no control hazards.
The number of clock cycles required for completion of execution of the sequence of instructions is ___________.
219 | |
220 | |
221 | |
222 |
Number of stages = 5
We know in a normal pipeline with k-stages time taken for n-instructions = k + n - 1 clock cycles.
So, in normal case total cycles = 100 + 5 - 1 = 104 cycles
But in this question it is given that PO stage of 40 instructions takes 3 cycles, 35 instructions takes 2 cycles and 25 instructions takes 1 cycle.
It is also given that all other stages take one clock cycle in all the 100 instructions.
PO stage of 40 instructions takes 3 cycles so these instructions will cause 2 stall cycle each, PO stage of 35 instructions takes 2 cycles so these instructions will cause 1 stall cycle each, But the 25 instruction whose PO stage takes 1 cycle, there are no stall cycles for these.
So, extra stall cycles = 40*2 + 35*1 = 80+35 = 115 cycles. So, total clock cycles = 104 + 115 = 219
Question 4 |
An instruction pipeline consists of 4 stages: Fetch(F), Decode operand field (D), Execute (E), and Result-Write (W). The five instructions in a certain instruction sequence need these stages for the different number of clock cycles as shown by the table below.
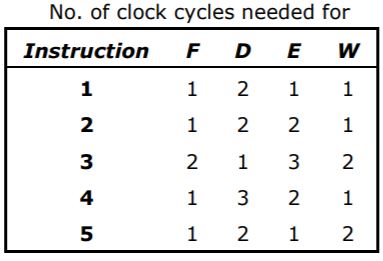
Find the number of clock cycles needed to perform the 5 instructions.
Theory Explanation. |
Question 5 |
Comparing the time T1 taken for a single instruction on a pipelined CPU with time T2 taken on a non-pipelined but identical CPU, we can say that
T1 ≤ T2 | |
T1 ≥ T2 | |
T1 < T2 | |
T1 is T2 plus the time taken for one instruction fetch cycle |
Pipelining is an implementation technique where multiple instructions are overlapped in execution. It has a high throughput (amount of instructions executed per unit time). In pipelining, many instructions are executed at the same time and execution is completed in fewer cycles. The pipeline is filled by the CPU scheduler from a pool of work which is waiting to occur. Each execution unit has a pipeline associated with it, so as to have work pre-planned. The efficiency of pipelining system depends upon the effectiveness of CPU scheduler.
NON- PIPELINING SYSTEM:
All the actions (fetching, decoding, executing of instructions and writing the results into the memory) are grouped into a single step. It has a low throughput.
Only one instruction is executed per unit time and execution process requires more number of cycles. The CPU scheduler in the case of non-pipelining system merely chooses from the pool of waiting work when an execution unit gives a signal that it is free. It is not dependent on CPU scheduler.
Question 6 |
Consider a 5-stage pipeline – IF (Instruction Fetch), ID (Instruction Decode and register read), EX (Execute), MEM (memory), and WB (Write Back). All (memory or register) reads take place in the second phase of a clock cycle and writes occur in the first phase of the clock cycle. Consider the execution of the following instruction sequence:
11: sub r2, r3, r4; /* r2 ← r3 – r4 */
12: sub r4, r2, r3; /* r4 ← r2 – r3 */
13: sw r2, 100(r1) /* M[r1+100] ← r2 */
14: sub r3, r4, r2; /* r3 ← r4 – r2 */
(a) Show all data dependencies between the four instructions.
(b) Identify the data hazards.
(c) Can all hazards be avoided by forwarding in this case?
Theory Explanation is given below. |
Question 7 |
The performance of a pipelined processor suffers if
the pipeline stages have different delays | |
consecutive instructions are dependent on each other | |
the pipeline stages share hardware resources | |
All of the above |
If pipeline stages can’t have different delays, no dependency among consecutive instructions and sharing of hardware resources should not be there.
Question 8 |
For a pipelined CPU with a single ALU, consider the following situations
I. The j + 1-st instruction uses the result of the j-th instruction as an operand II. The execution of a conditional jump instruction III. The j-th and j + 1-st instructions require the ALU at the same time
Which of the above can cause a hazard?
I and II only | |
II and III only | |
III only | |
All the three |
II is belongs to the Control hazard.
III is belongs to the Structural hazard.
→ Hazards are the problems with the instruction pipeline in CPU micro architectures.
Question 9 |
A 4-stage pipeline has the stage delays as 150, 120, 160 and 140 nanoseconds respectively. Registers that are used between the stages have a delay of 5 nanoseconds each. Assuming constant clocking rate, the total time taken to process 1000 data items on this pipeline will be
120.4 microseconds
| |
160.5 microseconds | |
165.5 microseconds
| |
590.0 microseconds |
1st instruction × 4 × clock time + 999 instruction × 1 × clock time
1 × 4 × 165ns + 999 × 1 × 165ns
= 1654.95ns
= 165.5μs
Question 10 |
17160 |
In a pipeline with k-stages, number of cycles to execute n instructions = (k+n-1) cycles
Here k = 5, n = 100
So we need a total of 5+100-1 = 104 cycles.
Clock cycle time = maximum of all stage delays + register delay
= max(150, 120, 150, 160, 140) + 5 = 160+5 = 165 ns
Time in ns = 104*165 = 17160ns
Question 11 |
If we use internal data forwarding to speed up the performance of a CPU (R1, R2 and R3 are registers and M[100] is a memory reference), then the sequence of operations
R1 → M[100] M[100] → R2 M[100] → R3can be replaced by
R1 → R3 R2 → M[100] | |
M[100] → R2 R1 → R2 R1 → R3 | |
R1 → M[100] R2 → R3 | |
R1 → R2 R1 → R3 R1 → M[100] |
Question 12 |
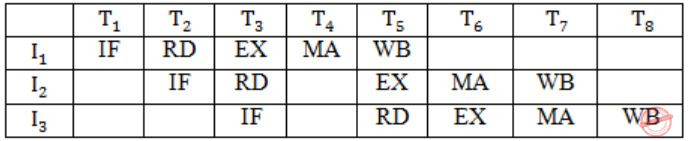
A CPU has only three instructions I1, I2 and I3, which use the following signals in time steps T1-T5:
I1 : T1 : Ain, Bout, Cin T2 : PCout, Bin T3 : Zout, Ain T4 : Bin, Cout T5 : End I2 : T1 : Cin, Bout, Din T2 : Aout, Bin T3 : Zout, Ain T4 : Bin, Cout T5 : End I3 : T1 : Din, Aout T2 : Ain, Bout T3 : Zout, Ain T4 : Dout, Ain T5 : EndWhich of the following logic functions will generate the hardwired control for the signal Ain ?
T1.I1 + T2.I3 + T4.I3 + T3 | |
(T1 + T2 + T3).I3 + T1.I1 | |
(T1 + T2 ).I1 + (T2 + T4).I3 + T3 | |
(T1 + T2 ).I2 + (T1 + T3).I1 + T3 |
So, Ain is 1 in T3 of I1, I2 and I3. Also during T1, and T2 and T4 of I3. So, answer will be
T1.I1 + T2.I3 + T4.I3 + T3.I1 + T3.I2 + T3.I3
Since, CPU is having only 3 instructions, T3.I1 + T3.I2 + T3.I3 can be replaced by T3.
So, T1.I1 + T2.I3 + T4.I3 + T3
Question 13 |
In an enhancement of a design of a CPU, the speed of a floating point unit has been increased by 20% and the speed of a fixed point unit has been increased by 10%. What is the overall speedup achieved if the ratio of the number of floating point operations to the number of fixed point operations is 2:3 and the floating point operation used to take twice the time taken by the fixed point operation in the original design?
1.155 | |
1.185 | |
1.255 | |
1.285 |
Let n be the time for a fixed point operation,
Original time taken = 3x+2×2n/5 = 7x/5
New time taken = (3x/1.1 + 4x/1.2)/5 = 8x/1.32×5
So, speedup = 7×1.32/8 = 1.155
Question 14 |
We have two designs D1 and D2 for a synchronous pipeline processor. D1 has 5 pipeline stages with execution times of 3 nsec, 2 nsec, 4 nsec, 2 nsec and 3 nsec while the design D2 has 8 pipeline stages each with 2 nsec execution time How much time can be saved using design D2 over design D1 for executing 100 instructions?
214 nsec | |
202 nsec | |
86 nsec | |
-200 nsec |
n = no. of instructions
Total execution time = (k+n-1) * maximum clock cycle
In case of D1:
k = 5
n = 100
Maximum clock cycle = 4 ns
Total execution time = (5+100-1) * 4 = 416
In case of D2:
k = 8
n = 100
Maximum clock cycle = 2 ns
Total execution time = (8+100-1) * 2 = 214
Starved time D2 over D1 = 416 - 214 = 202
Question 15 |
A pipelined processor uses a 4-stage instruction pipeline with the following stages: Instruction fetch (IF), Instruction decode (ID), Execute (EX) and Writeback (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S - R * (P + Q))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R1, R2, R3 and R4 respectively, before the execution of the instruction sequence.

The number of Read-After-Write (RAW) dependencies, Write-After-Read( WAR) dependencies, and Write-After-Write (WAW) dependencies in the sequence of instructions are, respectively,
2, 2, 4 | |
3, 2, 3 | |
4, 2, 2 | |
3, 3, 2 |
I1 - I2 (R5)
I2 - I3 (R6)
I3 - I4 (R5)
I4 - I5 (R6)
WAR:
I2 - I3 (R5)
I3 - I4 (R6)
WAW:
I1 - I3 (R5)
I3 - I4 (R6)
Question 16 |
A pipelined processor uses a 4-stage instruction pipeline with the following stages: Instruction fetch (IF), Instruction decode (ID), Execute (EX) and Writeback (WB). The arithmetic operations as well as the load and store operations are carried out in the EX stage. The sequence of instructions corresponding to the statement X = (S - R * (P + Q))/T is given below. The values of variables P, Q, R, S and T are available in the registers R0, R1, R2, R3 and R4 respectively, before the execution of the instruction

The IF, ID and WB stages take 1 clock cycle each. The EX stage takes 1 clock cycle each for the ADD, SUB and STORE operations, and 3 clock cycles each for MUL and DIV operations. Operand forwarding from the EX stage to the ID stage is used. The number of clock cycles required to complete the sequence of instructions is
10 | |
12 | |
14 | |
16 |
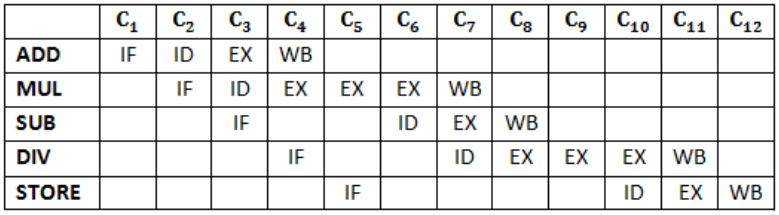
Question 17 |
A processor takes 12 cycles to complete an instruction I. The corresponding pipelined processor uses 6 stages with the execution times of 3, 2, 5, 4, 6 and 2 cycles respectively. What is the asymptotic speedup assuming that a very large number of instructions are to be executed?
1.83 | |
2 | |
3 | |
6 |
For a non-pipelined processor each instruction takes 12 cycles.
So for n instructions total execution time be 12 × n = 12n
For a pipelined processor each instruction takes
max (3, 2, 5, 4, 6, 2) = 6
So for n instructions total execution time be,
(1×6 + (n-1) × 1) × 6
= (6 + n - 1) × 6
= (5 + n) × 6
= 30 + 6n
∴ Speedup = time without pipeline/time with pipeline = 12n/30+6n
So, if n is very large,
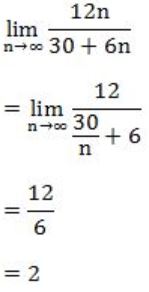
Question 18 |
A non pipelined single cycle processor operating at 100 MHz is converted into a synchronous pipelined processor with five stages requiring 2.5 nsec, 1.5 nsec, 2 nsec, 1.5 nsec and 2.5 nsec, respectively. The delay of the latches is 0.5 nsec. The speedup of the pipeline processor for a large number of instructions is
4.5 | |
4.0 | |
3.33 | |
3.0 |
For pipelined system = Max(stage delay) + Max(latch delay) = 2.5 + 0.5 = 3.0
Speedup = Time in non-pipelined system/Time in pipelined system = 10/3 = 3.33
Question 19 |
A 5 stage pipelined CPU has the following sequence of stages:
IF — Instruction fetch from instruction memory. RD — Instruction decode and register read. EX — Execute: ALU operation for data and address computation. MA — Data memory access - for write access, the register read at RD stage is used. WB — Register write back.
Consider the following sequence of instructions:
I1 : L R0, 1oc1; R0 <= M[1oc1] I2 : A R0, R0 1; R0 <= R0 + R0 I3 : S R2, R0 1; R2 <= R2 - R0 Let each stage take one clock cycle.
What is the number of clock cycles taken to complete the above sequence of instructions starting from the fetch of I1?
8 | |
10 | |
12 | |
15 |
If we don't use operator forwarding:

Total clock cycles = 8/11
There is no '11' in option.
Then no. of cycles = 8