SQL
Question 1 |
Consider the relation scheme.
AUTHOR (ANAME, INSTITUTION, ACITY, AGE) PUBLISHER (PNAME, PCITY) BOOK (TITLE, ANAME, PNAME)
Express the following queries using (one or more of )SELECT, PROJECT, JOIN and DIVIDE operations.
(a) Get the names of all publishers.
(b) Get values of all attributes of all authors who have published a book for the
publisher with PNAME = ‘TECHNICAL PUBLISHERS’.
(c) Get the names of all authors who have published a book for any publisher located in Madras.
Theory Explanation. |
Question 2 |
Consider a relational database containing the following schemas.
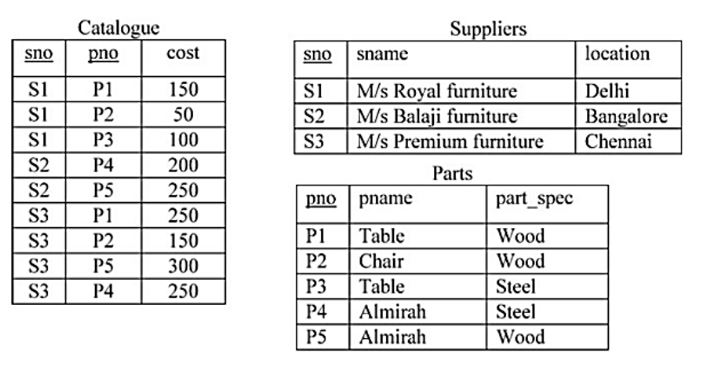
The primary key of each table is indicated by underlying the constituent fields.
SELECT s.sno, s.sname
FROM Suppliers s, Catalogue c
WHERE s.sno = c.sno AND
Cost > (SELECT AVG (cost)
FROM Catalogue
WHERE pno = ‘P4’
GROUP BY pno);
The number of rows returned by the above SQL query is
0 | |
5 | |
4 | |
2 |
AVG(COST)
------------
225
The outer query “select s.sno, s.sname from suppliers s, catalogue c where s.sno=c.sno” returns:
SNO SNAME
----------------------------------------
S1 M/s Royal furniture
S1 M/s Royal furniture
S1 M/s Royal furniture
S2 M/s Balaji furniture
S2 M/s Balaji furniture
S3 M/s Premium furniture
S3 M/s Premium furniture
S3 M/s Premium furniture
S3 M/s Premium furniture
So, the final result of the query is:
SN SNAME
----------------------------------------
S2 M/s Balaji furniture
S3 M/s Premium furniture
S3 M/s Premium furniture
S3 M/s Premium furniture
Therefore, 4 rows will be returned by the query.
Question 3 |
A library relational database system uses the following schema
USERS (User#, UserName, HomeTown) BOOKS (Book#, BookTitle, AuthorName) ISSUED (Book#, User#, Date)
Explain in one English sentence, what each of the following relational algebra queries is designed to determine
(a) σ User #=6 (11 User #, Book Title ((USERS ISSUED) BOOKS)) (b) σ Author Name (BOOKS (σ Home Town) = Delhi (USERS ISSUED)))
Theory Explanation. |
Question 4 |
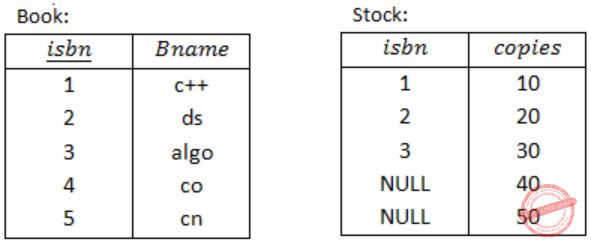
Consider the following two tables and four queries in SQL.
Book (isbn, bname), Stock (isbn, copies)Query 1: SELECT B.isbn, S.copies
FROM Book B INNER JOIN Stock S
ON B.isbn = S.isbn;
Query 2: SELECT B.isbn, S.copies
FROM Book B LEFT OUTER JOIN Stock S
ON B.isbn = S.isbn;
Query 3: SELECT B.isbn, S.copies
FROM Book B RIGHT OUTER JOIN Stock S
ON B.isbn = S.isbn;
Query 4: SELECT B.isbn, S.copies
FROM Book B FULL OUTER JOIN Stock S
ON B.isbn = S.isbn;
Which one of the queries above is certain to have an output that is a superset of the outputs of the other three queries?
Query 1 | |
Query 2 | |
Query 3 | |
Query 4 |
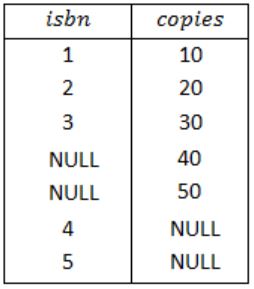
Book (isbn, bname)
Stock (isbn, copies)
isbn is a primary key of Book and isbn is a foreign key of stock referring to Book table.
For example:
Query 1:
INNER JOIN keyword selects records that have matching values in both tables (Book and Stock).
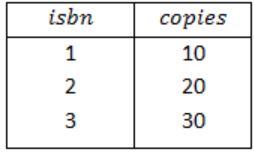
So, the result of Query 1 is,
Query 2:
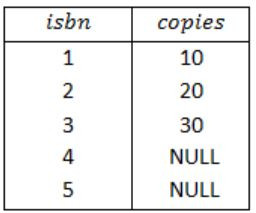
The LEFT OUTER JOIN keyword returns all records from the left table (Book) and the matched records from the right table (Stock).
The result is NULL from the right side, if there is no match.
So, the result of Query 2 is,
Query 3:
The RIGHT OUTER JOIN keyword returns all records from the right table (Stock), and the matched records from the left table(BOOK).
The result is NULL from the left side, when there is no match.
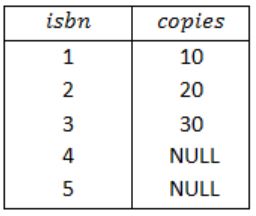
Query 4:
The FULL OUTER JOIN keyword return all records when there is a match in either left (Book) or right (Stock) table records.
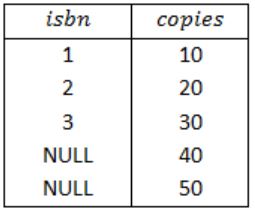
So, the result of Query 4 is,
Therefore, from the result of above four queries, a superset of the outputs of the Query 1, Query 2 and Query 3 is Query 4.
Note:
If we take isbn as a primary key in both the tables Book and Stock and foreign key, in one of the tables then also will get option (D) as the answer.
Question 5 |
(a) Suppose we have a database consisting of the following three relations.
FREQUENTS(student, parlor) giving the parlors each student visits.
SERVES(parlor, ice-cream) indicating what kind of ice-creams each parlor serves.
LIKES(student, ice-cream) indicating what ice-creams each parlor serves.
(Assuming that each student likes at least one ice-cream and frequents at least one parlor)
Express the following in SQL:
Print the students that frequent at least one parlor that serves some ice-cream that they like.
(b) In a computer system where the 'best-fit' algorithm is used for allocating 'jobs' to 'memory partitions', the following situation was encountered:

When will the 20K job complete? Note - This question was subjective type.
Theory Explanation. |
Question 6 |
Consider the following database relations containing the attributes
Book_id Subject_Category_of_book Name_of_Author Nationality_of_Author with Book_id as the Primary Key.
(a) What is the highest normal form satisfied by this relation?
(b) Suppose the attributes Book_title and Author_address are added to the relation, and the primary key is changed to (Name_of_Author, Book_Title), what will be the highest normal form satisfied by the relation?
Theory Explanation. |
Question 7 |
Consider the following relational database schemes:
COURSES(Cno, name) PRE-REQ(Cno, pre_Cno) COMPLETED(student_no, Cno)
COURSES give the number and the name of all the available courses.
PRE-REQ gives the information about which course are pre-requisites for a given course.
COMPLETED indicates what courses have been completed by students.
Express the following using relational algebra:
List all the courses for which a student with student_no 2310 has completed all the pre-requisites.
Theory Explanation. |
Question 8 |
Which of the following is/are correct?
An SQL query automatically eliminates duplicates | |
An SQL query will not work if there are no indexes on the relations | |
SQL permits attribute names to be repeated in the same relation | |
None of the above |
→ If there are no indexes on the relation SQL, then also it works.
→ SQL does not permit 2 attributes to have same name in a relation.
Question 9 |
Consider the set of relations
EMP(Employee-no, Dept-no, Employee-name, Salary) DEPT(Dept-no, Dept-name, Location)
Write an SQL query to:
(a) Find all employee names who work in departments located at "Calcutta" and whose salary is greater than Rs. 50,000.
(b) Calculate, for each department number, the number of employees with a salary greater than Rs. 100,000.
Theory Explanation. |
Question 10 |
Given relations r(w, x) and s(y, z), the result of
select distinct w, x
from r, s
is guaranteed to be same as r, provided
r has no duplicates and s is non-empty | |
r and s have no duplicates | |
s has no duplicates and r is non-empty | |
r and s have the same number of tuples |
Question 11 |
In SQL, relations can contain null values, and comparisons with null values are treated as unknown. Suppose all comparisons with a null value are treated as false. Which of the following pairs is not equivalent?
x = 5 not AND (not (x = 5) | |
x = 5 AND x > 4 and x < 6, where x is an integer | |
x ≠ 5 AND not (x = 5) | |
None of the above |
Question 12 |
Consider a bank database with only one relation
transaction (transno, acctno, date, amount)
The amount attribute value is positive for deposits and negative for withdrawals.
(a) Define an SQL view TP containing the information.
(acctno, T1.date, T2.amount)
for every pair of transactions T1, T2 such that T1 and T2 are transaction on the same account and the date of T2 is ≤ the date of T1.
(b) Using only the above view TP, write a query to find for each account the minimum balance it ever reached (not including the 0 balance when the account is created). Assume there is at most one transaction per day on each account, and each account has had atleast one transaction since it was created. To simply your query, break it up into 2 steps by defining an intermediate view V.
Theory Explanation is given below. |
Question 13 |
Consider a relation geq which represents “greater than or equal to”, that is, (x,y) ∈ geq only if y >= x.
create table geq ( Ib integer not null ub integer not null primary key 1b foreign key (ub) references geq on delete cascade )
Which of the following is possible if a tuple (x,y) is deleted?
A tuple (z,w) with z > y is deleted | |
A tuple (z,w) with z > x is deleted | |
A tuple (z,w) with w < x is deleted | |
The deletion of (x,y) is prohibited |
Question 14 |
Consider the following SQL query
select distinct al, a2,........., an from rl, r2,........, rm where P
For an arbitrary predicate P, this query is equivalent to which of the following relational algebra expressions?
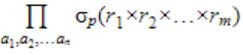 | |
 | |
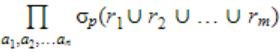 | |
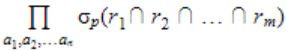 |
Question 15 |
Consider the set of relations shown below and the SQL query that follows.
Students: (Roll_number, Name, Date_of_birth)
Courses: (Course number, Course_name, Instructor)
Grades: (Roll_number, Course_number, Grade)
select distinct Name
from Students, Courses, Grades
where Students. Roll_number = Grades.Roll_number
and Courses.Instructor = Korth
and Courses.Course_number = Grades.Course_number
and Grades.grade = A
Which of the following sets is computed by the above query?
Names of students who have got an A grade in all courses taught by Korth
| |
Names of students who have got an A grade in all courses | |
Names of students who have got an A grade in at least one of the courses taught by Korth
| |
in none of the above |
Question 16 |
The employee information in a company is stored in the relation
Employee (name, sex, salary, deptName)Consider the following SQL query
Select deptName From Employee Where sex = 'M' Group by deptName Having avg (salary) > (select avg (salary) from Employee)
It returns the names of the department in which
the average salary is more than the average salary in the company
| |
the average salary of male employees is more than the average salary of all male employees in the company
| |
the average salary of male employees is more than the average salary of employees in the same department | |
the average salary of male employees is more than the average salary in the company |
This results the employees who having the salary more than the average salary.
Sex = M
Selects the Male employees whose salary is more than the average salary in the company.
Question 17 |
Consider the following relational schema:
COURSES (cno, cname) STUDENTS (rollno, sname, age, year) REGISTERED FOR (cno, rollno)
(a) Write a relational algebra query to
Print the roll number of students who have registered for cno 322.
(b) Write a SQL query to
Print the age and year of the youngest student in each year.
Theory Explanation. |
Question 18 |
The following relations are used to store data about students, courses, enrollment of students in courses and teachers of courses. Attributes for primary key in each relation are marked by ‘*’.
Students (rollno*, sname, saddr) courses (cno*, cname) enroll(rollno*, cno*,grade) teach(tno*,tname,cao*)
(cno is course number, cname is course name, tno is teacher number, tname is teacher name, sname is student name, etc.)
Write a SQL query for retrieving roll number and name of students who got A grade in at least one course taught by teacher named Ramesh for the above relational database.
Theory Explanation. |
Question 19 |
The following relations are used to store data about students, courses, enrollment of students in courses and teachers of courses. Attributes for primary key in each relation are marked by ‘*’.
Students (rollno*, sname, saddr) courses (cno*, cname) enroll(rollno*, cno*,grade) teach(tno*,tname,cao*)
(cno is course number, cname is course name, tno is teacher number, tname is teacher name, sname is student name, etc.)
For the relational database given above, the following functional dependencies hold:
rollno → sname,sdaddr cno → cname tno → tname rollno, cno → grade
(a) Is the database in 3rd normal form (3NF)?
(b) If yes, prove that it is in 3 NF. If not, normalize, the relations so that they
are in 3 NF (without proving).
Theory Explanation. |
Question 20 |
(a) How is redundancy reduced in the following models?
(i) Hierarchical (ii) Network (iii) Relational
Write a one line answer in each case.
(b) Suppose we have a database consisting of the following three relations:
FREQUENTS (CUSTOMER, HOTEL) SERVES (HOTEL, SNACKS) LIKES (CUSTOMER, SNACKS)
The first indicates the hotels each customer visits, the second tells which snacks each hotel serves and the last indicates which snacks are liked by each customer. Express the following query in relational algebra: print the hotels that serve a snack that customer Rama likes.
Theory Explanation. |
Question 21 |
Student(sNo, sName, dNo) Dept(dNo, dName)
Course(cNo, cName, dNo)
Register(sNo, cNo)
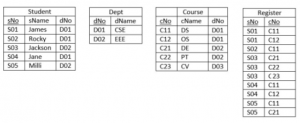
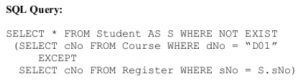
The number of rows returned by the above SQL query is___________.
2 |
-----+---------+------+
| sNo | sName | dNo |
+-----+---------+------+
| S01 | James | D01 |
| S04 | Jane | D01 |
+-----+---------+------+
Question 22 |
A relational database contains two tables student and department in which student table has columns roll_no, name and dept_id and department table has columns dept_id and dept_name. The following insert statements were executed successfully to populate the empty tables:
Insert into department values (1, 'Mathematics') Insert into department values (2, 'Physics') Insert into student values (l, 'Navin', 1) Insert into student values (2, 'Mukesh', 2) Insert into student values (3, 'Gita', 1)How many rows and columns will be retrieved by the following SQL statement?
Select * from student, department
0 row and 4 columns | |
3 rows and 4 columns | |
3 rows and 5 columns | |
6 rows and 5 columns |
rows = 3 * 2 = 6
Columns = 3 + 2 = 5
Question 23 |
A table T1 in a relational database has the following rows and columns:
roll no. marks
1 10
2 20
3 30
4 Null
The following sequence of SQL statements was successfully executed on table T1. Update T1 set marks = marks + 5 Select avg(marks) from T1What is the output of the select statement?
18.75 | |
20 | |
25 | |
NULL |
(15+25+35)/3 = 25
Question 24 |
A company maintains records of sales made by its salespersons and pays them commission based on each individual's total sales made in a year. This data is maintained in a table with following schema:
salesinfo = (salespersonid, totalsales, commission)
In a certain year, due to better business results, the company decides to further reward its salespersons by enhancing the commission paid to them as per the following formula:
If commission < = 50000, enhance it by 2% If 50000 < commission < = 100000, enhance it by 4% If commission > 100000, enhance it by 6%
The IT staff has written three different SQL scripts to calculate enhancement for each slab, each of these scripts is to run as a separate transaction as follows:
T1: Update salesinfo Set commission = commission * 1.02 Where commission < = 50000; T2: Update salesinfo Set commission = commission * 1.04 Where commission > 50000 and commission is < = 100000; T3: Update salesinfo Set commission = commission * 1.06 Where commission > 100000;Which of the following options of running these transactions will update the commission of all salespersons correctly
Execute T1 followed by T2 followed by T3 | |
Execute T2, followed by T3; T1 running concurrently throughout | |
Execute T3 followed by T2; T1 running concurrently throughout | |
Execute T3 followed by T2 followed by T1
|
In other cases some people will get two times increment, for example,
if we have T1 followed by T2 and if initial commission is 49500, then he is belonging to <50000.
Hence, 49500 * 1.02 = 50490.
Now again he is eligible for second category. So, he will get again increment as,
50490 * 1.04 = 52509.6
So he will get increment two times, but he is eligible for only one slab of commission.
Question 25 |
A table 'student' with schema (roll, name, hostel, marks), and another table 'hobby' with schema (roll, hobbyname) contains records as shown below:
Table: Student ROLL NAME HOSTEL MARKS 1798 Manoj Rathod 7 95 2154 Soumic Banerjee 5 68 2369 Gumma Reddy 7 86 2581 Pradeep Pendse 6 92 2643 Suhas Kulkarni 5 78 2711 Nitin Kadam 8 72 2872 Kiran Vora 5 92 2926 Manoj Kunkalikar 5 94 2959 Hemant Karkhanis 7 88 3125 Rajesh Doshi 5 82 Table: hobby ROLL HOBBYNAME 1798 chess 1798 music 2154 music 2369 swimming 2581 cricket 2643 chess 2643 hockey 2711 volleyball 2872 football 2926 cricket 2959 photography 3125 music 3125 chess
The following SQL query is executed on the above tables:
select hostel from student natural join hobby where marks >= 75 and roll between 2000 and 3000;
Relations S and H with the same schema as those of these two tables respectively contain the same information as tuples. A new relation S’ is obtained by the following relational algebra operation:
S’ = ∏hostel ((σs.roll = H.roll(σmarks > 75 and roll > 2000 and roll < 3000 (S)) X (H))
The difference between the number of rows output by the SQL statement and the number of tuples in S’ is
6 | |
4 | |
2 | |
0 |
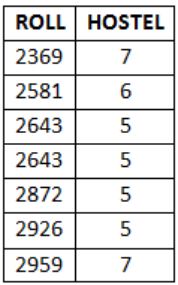
Total 7 rows are selected.
Where in relational algebra only distinct values of hostels are selected,i.e., 5, 6, 7 (3 rows).
∴ Answer is 7 - 3 = 4
Question 26 |
In an inventory management system implemented at a trading corporation, there are several tables designed to hold all the information. Amongst these, the following two tables hold information on which items are supplied by which suppliers, and which warehouse keeps which items along with the stock-level of these items.
Supply = (supplierid, itemcode)
Inventory = (itemcode, warehouse, stocklevel)
For a specific information required by the management, following SQL query has been written
Select distinct STMP.supplierid
From Supply as STMP
Where not unique (Select ITMP.supplierid
From Inventory, Supply as ITMP
Where STMP.supplierid = ITMP.supplierid
And ITMP.itemcode = Inventory.itemcode
And Inventory.warehouse = 'Nagpur');
For the warehouse at Nagpur, this query will find all suppliers who do not supply any item | |
supply exactly one item | |
supply one or more items | |
supply two or more items |
Question 27 |
Consider a database with three relation instances shown below. The primary keys for the Drivers and Cars relation are did and cid respectively and the records are stored in ascending order of these primary keys as given in the tables. No indexing is available
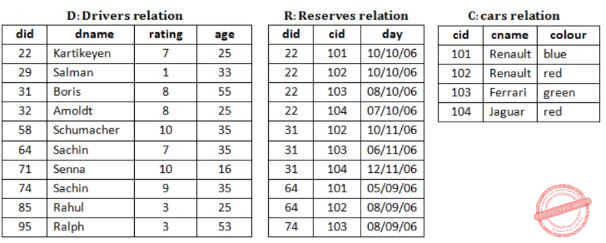
What is the output of the following SQL query?
select D.dname
from Drivers D
where D.did in (
select R.did
from Cars C, Reserves R
where R.cid = C.cid and C.colour = 'red'
intersect
select R.did
from Cars C, Reserves R
where R.cid = C.cid and C.colour = 'green'
)Karthikeyan, Boris | |
Sachin, Salman | |
Karthikeyan, Boris, Sachin | |
Schumacher, Senna
|
did = {22, 22, 31, 31, 64}
For colour = "Green"
did = {22, 31, 74}
Intersection of Red and Green will be = {22, 31}, which is Karthikeyan and Boris.
Question 28 |
Consider a database with three relation instances shown below. The primary keys for the Drivers and Cars relation are did and cid respectively and the records are stored in ascending order of these primary keys as given in the tables. No indexing is available
Let n be the number of comparisons performed when the above SQL query is optimally executed. If linear search is used to locate a tuple in a relation using primary key, then n lies in the range
36 - 40 | |
44 - 48 | |
60 - 64 | |
100 - 104 |
red did : 22, 31, 64
green did : 22, 31, 74
(6) for intersection
(1) for searching 22 in driver relation, and (3) for searching 31.
Total: 38 + 6 + 4 = 48
Question 29 |
Consider the following relational schema:
Student (school-id, sch-roll-no, sname, saddress) School (school-id, sch-name, sch-address, sch-phone) Enrolment(school-id, sch-roll-no, erollno, examname) ExamResult(erollno, examname, marks)
What does the following SQL query output?
SELECT sch-name, COUNT (*)
FROM School C, Enrolment E, ExamResult R
WHERE E.school-id = C.school-id
AND
E.examname = R.examname AND E.erollno = R.erollno
AND
R.marks = 100 AND S.school-id IN (SELECT school-id
FROM student
GROUP BY school-id
HAVING COUNT (*) > 200)
GROUP By school-idfor each school with more than 200 students appearing in exams, the name of the school and the number of 100s scored by its students | |
for each school with more than 200 students in it, the name of the school and the number of 100s scored by its students | |
for each school with more than 200 students in it, the name of the school and the number of its students scoring 100 in at least one exam | |
nothing; the query has a syntax error
|
Question 30 |
Suppose, a database consists of the following relations:
SUPPLIER (SCODE, SNAME, CITY)
PART (PCODE, PNAME, PDESC, CITY)
PROJECTS (PRCODE, PRNAME, CITY)
SPRR (SCODE, PCODE, PRCODE, QJY)
(a) Write SQL programs corresponding to the following queries:
(i) Print PCODE value for parts supplied to any project in DELHI by a supplier in DELHI.
(ii) Print all triples (CITY, PCODE, CITY), such that a supplier in the first city supplies the specified part to a project in the second city, but do not print triples in which the two CITY values are the same.
(b) Write algebraic solutions to the following:
(i) Get SCODE values for suppliers who supply to both projects PR1 and PR2.
(ii) Get PRCODE values for projects supplied by at least one supplier not in the same city.
Theory Explanation. |
Question 31 |
select title
from book as B
where (select count(*)
from book as T
where T.price > B.price) < 5 Titles of the four most expensive books
| |
Title of the fifth most inexpensive book | |
Title of the fifth most expensive book
| |
Titles of the five most expensive books |
The where clause of outer query will be true for 5 most expensive books.
Question 32 |
Consider the following database table named top_scorer.
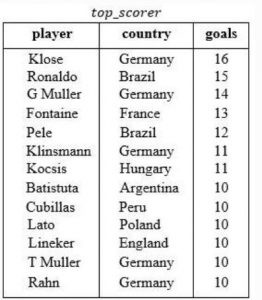
SELECT ta.player FROM top_scorer AS ta
WHERE ta.goals > ALL (SELECT tb.goals
FROM top_scorer AS tb
WHERE tb.country = 'Spain')
AND ta.goals > ANY (SELECT tc.goals
FROM top_scorer AS tc
WHERE tc.country = 'Germany')
The number of tuples returned by the above SQL query is _____.
7 | |
8 | |
9 | |
10 |

In the given database table top_scorer no players are there from ‘Spain’.
So, the query (1) results 0 and ALL (empty) is always TRUE.
The query (2) selects the goals of the players those who are belongs to ‘Germany’.
So, it results in ANY (16, 14, 11, 10).
So, the outer most query results the player names from top_scorer, who have more goals.
Since, the minimum goal by the ‘Germany’ player is 10, it returns the following 7 rows.

Question 33 |

The SQL query below is executed on this database.
SELECT *
FROM Student
WHERE gender = ‘F’ AND
marks > 65;
The number of rows returned by the query is ____?
2 |
There are a total 5 rows present in the student table. Among 5 rows , three rows belong to gender “F” and from that three rows also, only two rows consist of marks greater than 65.So Given query returns only two rows.
Question 34 |
SELECT operation in SQL is equivalent to
the selection operation in relational algebra | |
the selection operation in relational algebra, except that SELECT in SQL retains duplicates
| |
the projection operation in relational algebra | |
the projection operation in relational algebra, except that SELECT in SQL retains duplicates
|
Question 35 |
Consider the following relations:
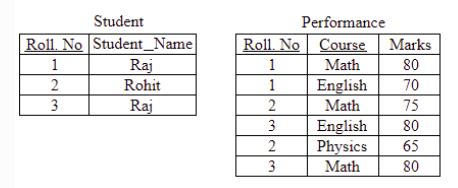
Consider the following SQL query.
SELECT S. Student_Name, sum(P.Marks)
FROM Student S, Performance P
WHERE S.Roll_No = P.Roll_No
GROUP BY S.Student_Name
The number of rows that will be returned by the SQL query is _________.
2 | |
3 | |
4 | |
5 |

Question 36 |
Consider the following database table named water_schemes :
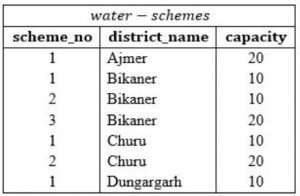
The number of tuples returned by the following SQL query is _________.
with total(name, capacity) as select district_name, sum(capacity) from water_schemes group by district_name with total_avg(capacity) as select avg(capacity) from total select name from total, total_avg where total.capacity ≥ total_avg.capacity
2 | |
3 | |
4 | |
5 |
The name assigned to the sub-query is treated as though it was an inline view or table.
• First group by district name is performed and total capacities are obtained as following:
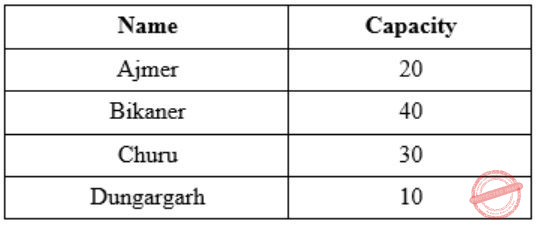
• Then average capacity is computed,
Average Capacity = (20 + 40 + 30 + 10)/4
= 100/4
= 25
• Finally, 3rd query will be executed and it's tuples will be considered as output, where name of district and its total capacity should be more than or equal to 25.
• Then average capacity is computed,
Average Capacity = (20 + 40 + 30 + 10)/4
= 100/4
= 25
• Finally, 3rd query will be executed and it's tuples will be considered as output, where name of district and its total capacity should be more than or equal to 25.
Question 37 |
A relational database contains two tables Student and Performance as shown below:
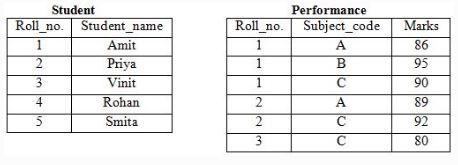
The primary key of the Student table is Roll_no. For the Performance table, the columns Roll_no. and Subject_code together from the primary key. Consider the SQL query given below:
SELECT S.Student_name, sum (P.Marks)
FROM Student S, Performance P
WHERE P.Marks > 84
GROUP BY S.Student_name;
The number of rows returned by the above SQL query is _____.
0 | |
9 | |
7 | |
5 |
SQL> SELECT S.Student_name,sum(P.Marks)
2 FROM Student S,Performance P
3 WHERE P.Marks>84
4 GROUP BY S.Student_name;
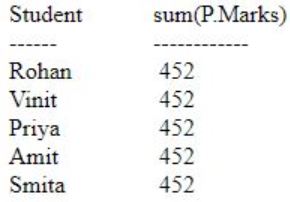
Question 38 |
Consider a database that has the relation schema EMP (EmpId, EmpName, and DeptName). An instance of the schema EMP and a SQL query on it are given below.
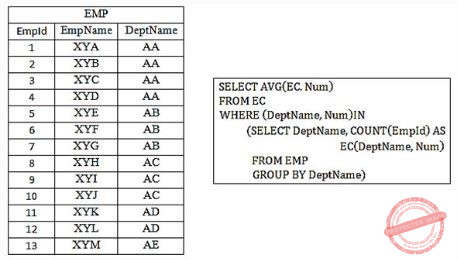
The output of executing the SQL query is ___________.
2.6 | |
2.7 | |
2.8 | |
2.9 |

⇾ We start evaluating from the inner query.
The inner query forms DeptName wise groups and counts the DeptName wise EmpIds.
⇾ In inner query DeptName, Count(EmpId) is the alias name DeptName, Num.
So, the output of the inner query is,
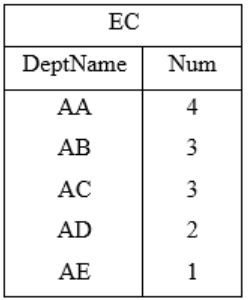
The outer query will find the
Avg(Num) = (4+3+3+2+1)/5 = 2.6
Question 39 |
Consider the following relation
Cinema (theater, address, capacity)
Which of the following options will be needed at the end of the SQL query
SELECT P1. address FROM Cinema P1
Such that it always finds the addresses of theaters with maximum capacity?
WHERE P1.capacity >= All (select P2.capacity from Cinema P2) | |
WHERE P1.capacity >= Any (select P2.capacity from Cinema P2) | |
WHERE P1.capacity > All (select max(P2.capacity) from Cinema P2) | |
WHERE P1.capacity > Any (select max(P2.capacity) from Cinema P2) |
So the theaters which are having maximum capacity will satisfy the condition.
Question 40 |
A relational schema for a train reservation database is given below. Passenger (pid, pname, age) Reservation (pid, class, tid)
Table: Passenger pid pname age ----------------- 0 Sachin 65 1 Rahul 66 2 Sourav 67 3 Anil 69 Table : Reservation pid class tid --------------- 0 AC 8200 1 AC 8201 2 SC 8201 5 AC 8203 1 SC 8204 3 AC 8202
What pids are returned by the following SQL query for the above instance of the tables?
SELECT pid
FROM Reservation ,
WHERE class ‘AC’ AND
EXISTS (SELECT *
FROM Passenger
WHERE age > 65 AND
Passenger. pid = Reservation.pid)1, 0 | |
1, 2 | |
1, 3 | |
1, 5 |
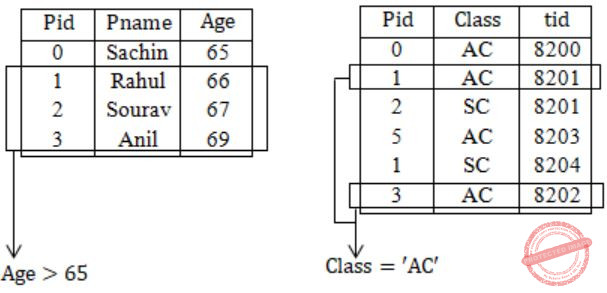
― 1, 3 Pids are returned