JNU PhD CS 2019
Question 1 |
An upper-layer packet is split into 10 frames, each of which has an 80 percent chance of arriving undamaged. If no error control is done by the data link protocol, how many times must the message be sent on average to get the entire thing through (in transmissions)?
18.6 | |
27.9 | |
9.3 | |
None of the above |
Question 1 Explanation:
Total frames=10
Each frame has a chance of 80% undamage which is 0.8 of getting through, the chance of the whole message getting through is (0.8)10, which is about 0.107. Call this value p.
The expected number of transmissions for an entire message is then

Now use a = 1-p to get E = 1/p. Thus, it takes an average of 1/0.107, or about 9.3 transmissions.
Each frame has a chance of 80% undamage which is 0.8 of getting through, the chance of the whole message getting through is (0.8)10, which is about 0.107. Call this value p.
The expected number of transmissions for an entire message is then
Now use a = 1-p to get E = 1/p. Thus, it takes an average of 1/0.107, or about 9.3 transmissions.
Question 2 |
Consider building a CSMA/CD network running at 1Gbps over a 1-km cable with no repeaters. The signal speed in the cable is 200,000 km/sec. What is the minimum frame size?
10000 bytes | |
100000 bits
| |
1250 bits | |
None of the above |
Question 2 Explanation:

Question 3 |
If two communicating stations X and Y are linked through two intermediate routers, r1 and r2; then determine the number of times each packet visits Network Layer (NL) and Data Link Layer (DLL) for single transmission from X to Y.
NL - 4, DLL - 4 | |
NL - 4, DLL - 3 | |
NL - 4, DLL - 6 | |
NL - 2, DLL - 6 |
Question 3 Explanation:
Each router will contain two DLL since it has two interfaces and one network layer. Each host or station will contain one network layer and one data link layer. So the total no. of data link layer will be 2(from stations) + 4(from routers) = 6. No. of network layers will be 2(from stations) + 2(from routers) = 4.
Question 4 |
To deliver a message to the correct application program running on a host, the address must be consulted is
port | |
physical | |
IP | |
None |
Question 4 Explanation:
IP address takes you to the correct host but not to the process in the host. And each host might contain many processes. So the address required to deliver a message to the application program or process within a host is the port address.
Question 5 |
Manchester encoding is principally designed to
ensure that the line remains unbalanced | |
have more than one symbol per bit period | |
increase the bandwidth of a signal transmitted on the medium | |
ensure that a transition occurs in the center of each bit period |
Question 5 Explanation:
In Manchester encoding a logic 0 is indicated by a 0 to 1 transition at the centre of the bit and logic 1 by 1 to 0 transition.
Question 6 |
The concept of pipelining is most effective in improving performance if the tasks being performed in different stages:
require different amount of time | |
require about the same amount of time | |
require different amount of time with time difference between any two tasks being same | |
require different amount with time difference between any two tasks being different |
Question 6 Explanation:
Case 1:
Consider 4 stages in pipeline P1, P2, P3, P4, with each stage requires 1ns.
For large no. of instructions the time taken by pipeline to execute one task is 1ns.
But for non pipeline the time taken to execute one task is,
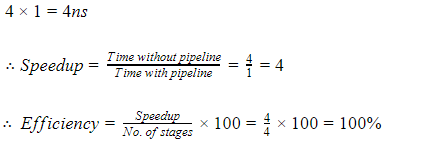
Case 2:
Now let’s consider 4 stages pipeline P1, P2, P3, P4, with each stage requiring 1ns, 2ns, 3ns, 4ns.
For large no. of instruction the time taken by pipeline to execute one task is max(1, 2, 3, 4)ns = 4ns
But for non pipeline the time taken to execute one task is,
1 + 2 + 3 + 4 = 10ns
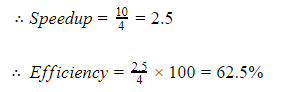
Hence from above it can be clearly seen that the concept of pipelining is most effective in improving performance if the tasks being performed in different stages require about the same amount of time.
Consider 4 stages in pipeline P1, P2, P3, P4, with each stage requires 1ns.
For large no. of instructions the time taken by pipeline to execute one task is 1ns.
But for non pipeline the time taken to execute one task is,
Case 2:
Now let’s consider 4 stages pipeline P1, P2, P3, P4, with each stage requiring 1ns, 2ns, 3ns, 4ns.
For large no. of instruction the time taken by pipeline to execute one task is max(1, 2, 3, 4)ns = 4ns
But for non pipeline the time taken to execute one task is,
1 + 2 + 3 + 4 = 10ns
Hence from above it can be clearly seen that the concept of pipelining is most effective in improving performance if the tasks being performed in different stages require about the same amount of time.
Question 7 |
Given that (292)10 = (1204)x in some number system x. The base x of that number system is
2 | |
8 | |
10 | |
None of the above |
Question 7 Explanation:

Question 8 |
Which of the following is not functionally a complete set?
AND, OR
| |
NOR | |
NAND | |
AND, OR, NOT |
Question 8 Explanation:
Functionally complete sets are NOR,NAND,(OR,NOT),(AND,NOT).
Hence Option (a) set in not functionally complete.
Hence Option (a) set in not functionally complete.
Question 9 |
Assume that for a certain processor, a read request takes 50 nanoseconds on a cache miss and 5 nanoseconds on a cache hit. Suppose while running a program, it was observed that 70% of the processor’s read requests result in a cache hit. The average read access time in nanoseconds is
10 | |
12 | |
13 | |
18.5 |
Question 9 Explanation:
ARAT = Hit rate × cache hit time + miss rate × cache miss time
= 0.7 × 5ns + 0.3 × 50ns
= 3.5ns + 15ns
= 18.5 ns
= 0.7 × 5ns + 0.3 × 50ns
= 3.5ns + 15ns
= 18.5 ns
Question 10 |
The number of min-terms after minimizing the following Boolean expression is
[D’ + AB’ + A’C + AC’D + A’C’D]’
1 | |
46 | |
56 | |
76 |
Question 10 Explanation:
(D’ + AB’ + A’C + AC’D + A’C’D)’
(D’ + A’C’D + AB’ + A’C + AC’D)’
((D’ + D) (D’ + A’C’) + AB’ + A’C + AC’D)’
(D’ + A’C’ + AB’ + A’C + AC’D)’
(D’ + AC’D + AB’ + A’(C + C’))’
(D’ + AC’ + AB’ + A’)
(D’ + AC’ + (B’ + A’) (A + A’)
(D’ + AC’ + B’ + A’)
(D’ + (A + A’) (C’ + A’) + B’)’
(D’ + C’ + A’ + B’)’ = ABCD
(D’ + A’C’D + AB’ + A’C + AC’D)’
((D’ + D) (D’ + A’C’) + AB’ + A’C + AC’D)’
(D’ + A’C’ + AB’ + A’C + AC’D)’
(D’ + AC’D + AB’ + A’(C + C’))’
(D’ + AC’ + AB’ + A’)
(D’ + AC’ + (B’ + A’) (A + A’)
(D’ + AC’ + B’ + A’)
(D’ + (A + A’) (C’ + A’) + B’)’
(D’ + C’ + A’ + B’)’ = ABCD
Question 11 |
The speed up of a pipeline processing over an equivalent non-pipeline processing is defined by the ratio:
where n→no. of tasks, Tn→time of completion of each task, k→no. of segments of pipeline, Tp→clock cycle time, S→speed up ratio.
S = n Tn/ (k + n - 1) Tp | |
S = n Tn/ (k + n + 1) Tp | |
S = n Tn/ (k - n + 1) Tp | |
S = (k + n - 1) Tp/ n Tn |
Question 11 Explanation:
Consider a ‘k’ segment pipeline with clock cycle time as ‘Tp’. Let there be ‘n’ tasks to be completed in the pipelined processor. Now, the first instruction is going to take ‘k’ cycles to come out of the pipeline but the other ‘n – 1’ instructions will take only ‘1’ cycle each, i.e, a total of ‘n – 1’ cycles. So, time taken to execute ‘n’ instructions in a pipelined processor:
ET pipeline = k + n – 1 cycles
= (k + n – 1) Tp
In the same case, for a non-pipelined processor, execution time of ‘n’ instructions will be:
ETnon-pipeline = n * k * Tp
but in question k * Tp = Tn
Hence ETnon-pipeline = n * Tn
So, speedup (S) of the pipelined processor over non-pipelined processor, when ‘n’ tasks are executed on the same processor is:
S = Performance of pipelined processor /
Performance of Non-pipelined processor
As the performance of a processor is inversely proportional to the execution time, we have,
S = ETnon-pipeline / ETpipeline
=> S = [n *Tn] / [(k + n – 1) * Tp]
ET pipeline = k + n – 1 cycles
= (k + n – 1) Tp
In the same case, for a non-pipelined processor, execution time of ‘n’ instructions will be:
ETnon-pipeline = n * k * Tp
but in question k * Tp = Tn
Hence ETnon-pipeline = n * Tn
So, speedup (S) of the pipelined processor over non-pipelined processor, when ‘n’ tasks are executed on the same processor is:
S = Performance of pipelined processor /
Performance of Non-pipelined processor
As the performance of a processor is inversely proportional to the execution time, we have,
S = ETnon-pipeline / ETpipeline
=> S = [n *Tn] / [(k + n – 1) * Tp]
Question 12 |
Consider a system running ten I/O - bound tasks and one CPU - bound task. Assume that the I/O - bound tasks issue an I/O operation once for every millisecond of CPU computing and that each I/O operation takes 10 milliseconds to complete. Also assume that the context switching overhead is 0.1 millisecond and that all processes are long-running tasks. The CPU utilization for a round-robin scheduler when the time quantum is millisecond?
78% | |
91% | |
98% | |
80% |
Question 12 Explanation:
The time quantum is 1 millisecond: Irrespective of which process is scheduled, the scheduler incurs a 0.1 millisecond context-switching cost for every context-switch. This results in a CPU utilization of 1/1.1 * 100 = 91%.
There are 12 questions to complete.