NTA UGC NET Dec 2023 Paper-2
Question 1 |
"CREATE TABLE T" in SQL is an example of:
Normalization | |
DML | |
DDL | |
Primary key |
Question 1 Explanation:
In SQL, the "CREATE TABLE" statement is part of the Data Definition Language (DDL). DDL is a subset of SQL that deals with the definition of database structures, including creating, modifying, and deleting tables and schemas. The "CREATE TABLE" statement specifically creates a new table in the database.
Question 2 |
Which of the following statement(s) is/are NOT CORRECT ?
(A) OSPF is based on distance-vector routing protocol.
(B) Both link-state and distance-vector routing are based on the least cost goal.
(C) BGP4 is based on the path-vector algorithm.
(D) The three-node instability can be avoided using split horizon combined with poison reverse.
(E) RIP is based on link state algorithm.
Choose the correct answer from the options given below:
(A) OSPF is based on distance-vector routing protocol.
(B) Both link-state and distance-vector routing are based on the least cost goal.
(C) BGP4 is based on the path-vector algorithm.
(D) The three-node instability can be avoided using split horizon combined with poison reverse.
(E) RIP is based on link state algorithm.
Choose the correct answer from the options given below:
(A), (D) and (E) Only | |
(A) and (B) Only | |
(B) and (C) Only | |
(B), (C) and (E) Only |
Question 2 Explanation:
(A) OSPF is based on distance-vector routing protocol. - This statement is incorrect. OSPF (Open Shortest Path First) is a link-state routing protocol, not distance-vector.
(D) The three-node instability can be avoided using split horizon combined with poison reverse. - This statement is correct. Split horizon and poison reverse are techniques used to avoid the count-to-infinity problem in distance-vector routing protocols.
(E) RIP is based on the link-state algorithm. - This statement is incorrect. RIP (Routing Information Protocol) is a distance-vector routing protocol, not a link-state.
(D) The three-node instability can be avoided using split horizon combined with poison reverse. - This statement is correct. Split horizon and poison reverse are techniques used to avoid the count-to-infinity problem in distance-vector routing protocols.
(E) RIP is based on the link-state algorithm. - This statement is incorrect. RIP (Routing Information Protocol) is a distance-vector routing protocol, not a link-state.
Question 3 |
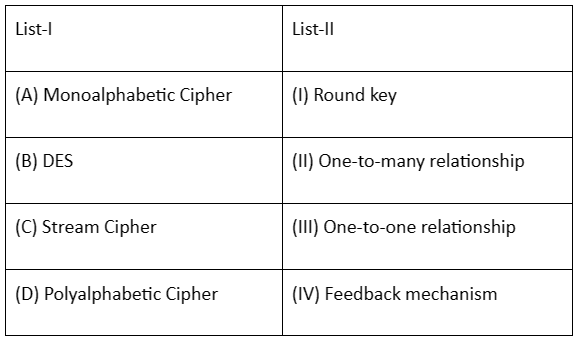
Match List - I with List II.
Choose the correct answer from the options given below:
Choose the correct answer from the options given below:
(А)-(III), (B)-(1), (C)-(IV), (D)-(II) | |
(A)-(III), (B)-(IV), (C)-(II), (D)-(I) | |
(A)-(1), (B)-(III), (C)-(IV), (D)-(II) | |
(A)-(II), (B)-(I), (C)-(IV), (D)-(III) |
Question 3 Explanation:
Monoalphabetic Cipher (A): In a monoalphabetic cipher, each letter in the plaintext is replaced with another letter, creating a one-to-one relationship. So, (A)-(III) is correct.
DES (B): DES (Data Encryption Standard) is a symmetric-key algorithm, and it uses a round key in its encryption process. So, (B)-(I) is correct.
Stream Cipher (C): Stream ciphers encrypt data one bit or byte at a time, and they often use a feedback mechanism. So, (C)-(IV) is correct.
Polyalphabetic Cipher (D): Polyalphabetic ciphers use multiple substitution alphabets, creating a more complex relationship. So, (D)-(II) is correct
DES (B): DES (Data Encryption Standard) is a symmetric-key algorithm, and it uses a round key in its encryption process. So, (B)-(I) is correct.
Stream Cipher (C): Stream ciphers encrypt data one bit or byte at a time, and they often use a feedback mechanism. So, (C)-(IV) is correct.
Polyalphabetic Cipher (D): Polyalphabetic ciphers use multiple substitution alphabets, creating a more complex relationship. So, (D)-(II) is correct
Question 4 |
The prototyping model has the sequence:
(A) Customer Evaluation
(B) Quick design
(C) Requirements
(D) Implement
(E) Design
Choose the correct answer from the options given below:
(A) Customer Evaluation
(B) Quick design
(C) Requirements
(D) Implement
(E) Design
Choose the correct answer from the options given below:
(C)→(A)→(D)→(B)→(E) | |
(B)→ (C)→(A)→(D)→(E) | |
(C)→(B)→(D)→(A)→(E) | |
(E)→(B)→(C)→(D)→(A) |
Question 4 Explanation:
Requirements (C):
Gather and analyze user needs and expectations to define system requirements.
Quick Design (B):
Create a basic, working model of the system, focusing on core functionalities and user interfaces.
Implement (D):
Build the prototype using appropriate tools and technologies.
Customer Evaluation (A):
Present the prototype to users for feedback and evaluation.
Gather suggestions for improvements and refinements.
Refine Design (E):
Incorporate user feedback into the design, addressing identified issues and enhancing features.
Iterate through steps 3-5 as needed until a satisfactory prototype is achieved.
Gather and analyze user needs and expectations to define system requirements.
Quick Design (B):
Create a basic, working model of the system, focusing on core functionalities and user interfaces.
Implement (D):
Build the prototype using appropriate tools and technologies.
Customer Evaluation (A):
Present the prototype to users for feedback and evaluation.
Gather suggestions for improvements and refinements.
Refine Design (E):
Incorporate user feedback into the design, addressing identified issues and enhancing features.
Iterate through steps 3-5 as needed until a satisfactory prototype is achieved.
Question 5 |

Choose the correct answer from the options given below:
(A)-(I), (B)-(II), (C)-(III), (D)-(IV) | |
(A)-(II), (B)-(I), (C)-(III), (D)-(IV) | |
(A)-(II), (B)-(I), (C)-(IV), (D)-(III) | |
(A)-(I), (B)-(II), (C)-(IV), (D)-(III) |
Question 6 |
A program that is used by other routines to accomplish a particular task, is called:
Micro program. | |
Micro operation | |
Routine | |
Subroutine |
Question 6 Explanation:
A subroutine is a program that is designed to perform a specific task and is intended to be used by other parts of a program. It is a set of instructions designed to accomplish a particular task, and it is often used to perform common operations that may be needed at multiple points in a program.
Subroutines are reusable and can be called from different parts of a program to perform the same task, promoting code modularity and reusability. Therefore, in the context of programming, the term "subroutine" is used to describe a set of instructions designed to accomplish a specific task.
Micro program: A low-level program that controls the basic operations of a computer's hardware, often embedded in the hardware itself.
Micro operation: A single, elementary operation performed by a processor, such as fetching an instruction or adding two numbers.
Routine: A general term for a sequence of instructions that performs a specific task, but it doesn't necessarily imply reusability or being called by other routines.
Subroutines are reusable and can be called from different parts of a program to perform the same task, promoting code modularity and reusability. Therefore, in the context of programming, the term "subroutine" is used to describe a set of instructions designed to accomplish a specific task.
Micro program: A low-level program that controls the basic operations of a computer's hardware, often embedded in the hardware itself.
Micro operation: A single, elementary operation performed by a processor, such as fetching an instruction or adding two numbers.
Routine: A general term for a sequence of instructions that performs a specific task, but it doesn't necessarily imply reusability or being called by other routines.
Question 7 |
Given as 4 GB (4.3 x 109 bytes) of virtual space and typical page size of 4 KB and each page table entry is 5 bytes. How many virtual pages would this imply? What is the size of whole page table?
107500 and 20480 bytes | |
215000 and 40960 bytes | |
10750 and 10240 bytes | |
43000 and 1024 bytes |
Question 8 |
Indexed/grouped allocation is useful as:
(A) It supports both sequential and direct access.
(B) Entire block is available for data.
(C) It does not require lots of space for keeping pointers.
(D) No external fragmentation.
Choose the correct answer from the options given below:
(A) It supports both sequential and direct access.
(B) Entire block is available for data.
(C) It does not require lots of space for keeping pointers.
(D) No external fragmentation.
Choose the correct answer from the options given below:
(A) Only | |
(B) and (C) Only | |
(B) Only | |
(A), (B) and (D) Only |
Question 9 |
The Hue of a colour is related to its :
Luminance | |
Saturation | |
Incandescence | |
Wavelength |
Question 9 Explanation:
Hue refers to the attribute of color that allows it to be classified as red, blue, green, etc., and it is determined by the dominant wavelength of the light.
Question 10 |
Which of the following are commonly used parsing techniques in NLP (Natural Language Processing) for syntactic analysis,
(A) Top down parsing
(B) Bottom Up parsing
(C) Dependency parsing.
(D) Statistical machine translation
(E) Earley parsing
Choose the correct answer from the options given below:
(A) Top down parsing
(B) Bottom Up parsing
(C) Dependency parsing.
(D) Statistical machine translation
(E) Earley parsing
Choose the correct answer from the options given below:
(A), (C) (D),(E) Only | |
(B) (C) (D), (E) Only | |
(A) (B) (C), (E) Only | |
(A) and (B) Only |
Question 10 Explanation:
(A) Top-Down Parsing:
Starts with the root of the sentence structure and works its way down, attempting to match grammar rules to the input sentence.
Examples include recursive descent parsing and LL parsers.
(B) Bottom-Up Parsing:
Starts with individual words or phrases and builds the structure upward, combining smaller structures into larger ones based on grammar rules.
Examples include shift-reduce parsing and LR parsers. (C) Dependency Parsing:
Focuses on identifying the relationships between words in a sentence, specifically which words are dependent on others.
Represents sentence structure as a dependency tree. (E) Earley Parsing:
A type of dynamic programming algorithm that can efficiently handle ambiguity and left-recursion in grammars.
It's a chart-based parsing algorithm that can be used for both top-down and bottom-up parsing. (D) Statistical Machine Translation:
Not a parsing technique for syntactic analysis. It's a method for translating text from one language to another using statistical models.
Starts with the root of the sentence structure and works its way down, attempting to match grammar rules to the input sentence.
Examples include recursive descent parsing and LL parsers.
(B) Bottom-Up Parsing:
Starts with individual words or phrases and builds the structure upward, combining smaller structures into larger ones based on grammar rules.
Examples include shift-reduce parsing and LR parsers. (C) Dependency Parsing:
Focuses on identifying the relationships between words in a sentence, specifically which words are dependent on others.
Represents sentence structure as a dependency tree. (E) Earley Parsing:
A type of dynamic programming algorithm that can efficiently handle ambiguity and left-recursion in grammars.
It's a chart-based parsing algorithm that can be used for both top-down and bottom-up parsing. (D) Statistical Machine Translation:
Not a parsing technique for syntactic analysis. It's a method for translating text from one language to another using statistical models.
Question 11 |
Match List - I with List II.

Choose the correct answer from the options given below:
Choose the correct answer from the options given below:
(A)-(III), (B)-(II), (C)-(I), (D)-(IV) | |
(A)-(IV), (B)-(I), (C)-(II), (D)-(III) | |
(A)-(II), (B)-(III), (C)-(IV), (D)-(I) | |
(A)-(IV), (B)-(I), (C)-(III), (D)-(II) |
Question 11 Explanation:
(A) BCNF iff (II) all underlying domains contain scalar values only This is true because BCNF (Boyce-Codd Normal Form) requires that all attributes are functionally dependent on the primary key, and all domains should contain only atomic (scalar) values.
(B) 5 NF iff (III) every MVD is implied by the candidate keys This is true because 5NF (Fifth Normal Form) deals with multivalued dependencies (MVDs), and it requires that every MVD is implied by the candidate keys.
(C) 1 NF iff (IV) every FD is implied by the candidate keys This is true because 1NF (First Normal Form) deals with the elimination of repeating groups, and it ensures that every functional dependency (FD) is implied by the candidate keys.
(D) 4 NF iff (I) every ID is implied by the candidate keys This is true because 4NF (Fourth Normal Form) deals with multivalued dependencies, and it requires that every implied dependency (ID) is implied by the candidate keys.
(B) 5 NF iff (III) every MVD is implied by the candidate keys This is true because 5NF (Fifth Normal Form) deals with multivalued dependencies (MVDs), and it requires that every MVD is implied by the candidate keys.
(C) 1 NF iff (IV) every FD is implied by the candidate keys This is true because 1NF (First Normal Form) deals with the elimination of repeating groups, and it ensures that every functional dependency (FD) is implied by the candidate keys.
(D) 4 NF iff (I) every ID is implied by the candidate keys This is true because 4NF (Fourth Normal Form) deals with multivalued dependencies, and it requires that every implied dependency (ID) is implied by the candidate keys.
Question 12 |
Which data structure is typically used to implement a hash table?
Linked list | |
Array | |
Binary Tree | |
Stack |
Question 12 Explanation:
In a hash table, an array is typically used to store the key-value pairs. The keys are hashed to index locations in the array using a hash function. This allows for efficient retrieval and storage of data, as the key can be used to directly access the corresponding value in the array. Arrays provide constant-time access to elements based on their index, making them a suitable data structure for implementing hash tables.
Question 13 |
Let L-={ab, aa, baa}.
Which of the following strings are not in L.
Which of the following strings are not in L.
abaabaaabaa | |
aaaabaaaa | |
baaaaabaaaab | |
baaaaabaa |
Question 13 Explanation:
L is a language consisting of strings that can be formed by concatenating the strings "ab", "aa", and "baa".
To determine if a string is in L, we must check if it can be constructed using only those three strings.
Let's analyze each option:
abaabaaabaa: Can be formed as "ab" + "aa" + "baa" + "ab" + "aa" + "baa".
aaaabaaaa: Can be formed as "aa" + "aa" + "baa" + "aa" + "aa".
baaaaabaa: Can be formed as "baa" + "aa" + "baa" + "aa".
However, baaaaabaaaab cannot be formed using the strings in L.
To determine if a string is in L, we must check if it can be constructed using only those three strings.
Let's analyze each option:
abaabaaabaa: Can be formed as "ab" + "aa" + "baa" + "ab" + "aa" + "baa".
aaaabaaaa: Can be formed as "aa" + "aa" + "baa" + "aa" + "aa".
baaaaabaa: Can be formed as "baa" + "aa" + "baa" + "aa".
However, baaaaabaaaab cannot be formed using the strings in L.
Question 14 |
What is the probability that a positive integer selected at random from the set of positive integers not exceeding 100 is divisible by either 2 or 5?
10/5 | |
3/5 | |
2/5 | |
1/3 |
Question 14 Explanation:
The set of positive integers not exceeding 100 can be represented as {1, 2, 3, ..., 100}.
To find the probability that a randomly selected positive integer from this set is divisible by either 2 or 5, we need to find the count of numbers divisible by 2 or 5 and divide it by the total count of numbers.
Count of numbers divisible by 2: 1, 2, 3, ..., 100 Count = 100/2 = 50
Count of numbers divisible by 5: 5, 10, 15, ..., 100
Count = 100/5 = 20
However, numbers divisible by both 2 and 5 (i.e., divisible by 10) have been counted twice, so we need to subtract them once.
Count of numbers divisible by 10: 10, 20, 30, ..., 100
Count = 100/10 = 10
Now, apply the inclusion-exclusion principle:
Total count = Count of numbers divisible by 2 + Count of numbers divisible by 5 - Count of numbers divisible by 10 = 50 + 20 - 10 = 60
Probability = (Count of favorable outcomes) / (Total count) = 60 / 100
Simplify the fraction: Probability = 3/5
To find the probability that a randomly selected positive integer from this set is divisible by either 2 or 5, we need to find the count of numbers divisible by 2 or 5 and divide it by the total count of numbers.
Count of numbers divisible by 2: 1, 2, 3, ..., 100 Count = 100/2 = 50
Count of numbers divisible by 5: 5, 10, 15, ..., 100
Count = 100/5 = 20
However, numbers divisible by both 2 and 5 (i.e., divisible by 10) have been counted twice, so we need to subtract them once.
Count of numbers divisible by 10: 10, 20, 30, ..., 100
Count = 100/10 = 10
Now, apply the inclusion-exclusion principle:
Total count = Count of numbers divisible by 2 + Count of numbers divisible by 5 - Count of numbers divisible by 10 = 50 + 20 - 10 = 60
Probability = (Count of favorable outcomes) / (Total count) = 60 / 100
Simplify the fraction: Probability = 3/5
Question 15 |
Let A={a, b} and L=A*. Let x={anbn, n>0). The languages L U X and X are respectively:
(1)
(2)
(3)
(4)
Not regular, Regular | |
Regular, Regular | |
Regular, Not regular | |
Not Regular, Not Regular |
Question 15 Explanation:
L = A*: As mentioned before, this is a regular language representing all strings over alphabet A (a and b), including the empty string.
X = {a^n b^n, n>0}:This language contains strings with an equal number of a's and b's, both counts being greater than 0. The key thing to notice is that the number of a's and b's must be the same, and both must be greater than 0.
L U X: Combining L (all strings over A) with X (strings with equal and positive a's and b's) using union will still result in a regular language. L essentially adds all other strings not included in X (e.g., strings with only a's or b's, or strings with unequal counts).
X:This is where the irregularity comes in. The condition of having an equal and positive number of a's and b's requires more than just a regular expression to recognize. Regular expressions can represent repetition, concatenation, and alternation, but checking for equality of two variable-length parts (a's and b's) within the string goes beyond what they can handle.
Therefore, we have:
L U X: Regular because it's the union of two regular languages.
X: Not regular because it requires a condition that regular expressions cannot capture.
X = {a^n b^n, n>0}:This language contains strings with an equal number of a's and b's, both counts being greater than 0. The key thing to notice is that the number of a's and b's must be the same, and both must be greater than 0.
L U X: Combining L (all strings over A) with X (strings with equal and positive a's and b's) using union will still result in a regular language. L essentially adds all other strings not included in X (e.g., strings with only a's or b's, or strings with unequal counts).
X:This is where the irregularity comes in. The condition of having an equal and positive number of a's and b's requires more than just a regular expression to recognize. Regular expressions can represent repetition, concatenation, and alternation, but checking for equality of two variable-length parts (a's and b's) within the string goes beyond what they can handle.
Therefore, we have:
L U X: Regular because it's the union of two regular languages.
X: Not regular because it requires a condition that regular expressions cannot capture.
Question 16 |
Arrange the following in ascending order:
(A) Remainder of 4916 when divided by 17
(B) Remainder of 2446 when divided by 9
(C) Remainder of 15517 when divided by 17
(D) Last digits of the number 745
Choose the correct answer from the options given below:
(A) Remainder of 4916 when divided by 17
(B) Remainder of 2446 when divided by 9
(C) Remainder of 15517 when divided by 17
(D) Last digits of the number 745
Choose the correct answer from the options given below:
(A), (B), (C), (D) | |
(A), (B), (D), (C) | |
(A), (C), (B), (D) | |
(D), (C), (B), (A) |
Question 17 |
Which of the statement is/are CORRECT?
(A) Moore and Mealy machines are finite state machines with output capabilities
(B) Any given Moore machine has an equivalent Mealy machine.
(C) Any given Mealy machine has an equivalent Moore machine.
(D) Moore machine is not a finite state machine.
Choose the correct answer from the options given below:
(A) Moore and Mealy machines are finite state machines with output capabilities
(B) Any given Moore machine has an equivalent Mealy machine.
(C) Any given Mealy machine has an equivalent Moore machine.
(D) Moore machine is not a finite state machine.
Choose the correct answer from the options given below:
(A) and (B) Only | |
(A), (B) and (C) Only | |
(B) and (D) Only | |
(A), (B) and (D) Only |
Question 17 Explanation:
(A) Moore and Mealy machines are finite state machines with output capabilities:
True. Both Moore and Mealy machines are fundamental types of finite state machines (FSMs) that have:
A finite set of states
Transitions between states based on input The ability to produce outputs
(B) Any given Moore machine has an equivalent Mealy machine:
True. Any Moore machine can be transformed into an equivalent Mealy machine that exhibits the same behavior. The transformation involves moving the output generation from being solely dependent on the current state (as in Moore) to also considering the current input (as in Mealy).
(C) Any given Mealy machine has an equivalent Moore machine:
True. Conversely, any Mealy machine can also be converted into an equivalent Moore machine. This involves introducing additional states to model the output behavior based solely on the current state, as required in a Moore machine.
(D) Moore machine is not a finite state machine:
False. As explained in statement (A), Moore machines are indeed a type of finite state machine, characterized by their specific output behavior.
True. Both Moore and Mealy machines are fundamental types of finite state machines (FSMs) that have:
A finite set of states
Transitions between states based on input The ability to produce outputs
(B) Any given Moore machine has an equivalent Mealy machine:
True. Any Moore machine can be transformed into an equivalent Mealy machine that exhibits the same behavior. The transformation involves moving the output generation from being solely dependent on the current state (as in Moore) to also considering the current input (as in Mealy).
(C) Any given Mealy machine has an equivalent Moore machine:
True. Conversely, any Mealy machine can also be converted into an equivalent Moore machine. This involves introducing additional states to model the output behavior based solely on the current state, as required in a Moore machine.
(D) Moore machine is not a finite state machine:
False. As explained in statement (A), Moore machines are indeed a type of finite state machine, characterized by their specific output behavior.
Question 18 |
In a feed forward neural network with the following specifications
The input layer has 4 neutrons, the hidden layer has 3 neurons and the output layer has 2 neurons using the sigmoid activation function for given input values [0.5,0.8,0.2,0.6] as well as the initial weights for the connections.
Input layer to hidden layer weights
WI: [0.1, 0.3, 0.5, 0.2]
W2: [0.2, 0.4, 0.6, 0.2]
W3: [0.3, 0.5, 0.7, 0.2]
Hidden layer to output layer weights
W4:[0.4,0.1, 0.3]
WS: [0.5,0.2.0.4]
What is the output of the output layer when the given a input values are passed through neural network?
Round the answer to two decimal places
The input layer has 4 neutrons, the hidden layer has 3 neurons and the output layer has 2 neurons using the sigmoid activation function for given input values [0.5,0.8,0.2,0.6] as well as the initial weights for the connections.
Input layer to hidden layer weights
WI: [0.1, 0.3, 0.5, 0.2]
W2: [0.2, 0.4, 0.6, 0.2]
W3: [0.3, 0.5, 0.7, 0.2]
Hidden layer to output layer weights
W4:[0.4,0.1, 0.3]
WS: [0.5,0.2.0.4]
What is the output of the output layer when the given a input values are passed through neural network?
Round the answer to two decimal places
[0.62, 0.68] | |
[0.72 0.78] | |
[0.82, 0.88] | |
[0.92,0.98] |
Question 18 Explanation:
Here's the step-by-step calculation:
1. Input Layer to Hidden Layer:
Calculate weighted sums for each hidden neuron:
H1 = 0.1*0.5 + 0.3*0.8 + 0.5*0.2 + 0.2*0.6 = 0.51
H2 = 0.2*0.5 + 0.4*0.8 + 0.6*0.2 + 0.2*0.6 = 0.66
H3 = 0.3*0.5 + 0.5*0.8 + 0.7*0.2 + 0.2*0.6 = 0.81
Apply sigmoid activation function to each hidden neuron:
A1 = 1 / (1 + exp(-H1)) = 0.624
A2 = 1 / (1 + exp(-H2)) = 0.658
A3 = 1 / (1 + exp(-H3)) = 0.692
2. Hidden Layer to Output Layer:
Calculate weighted sums for each output neuron:
O1 = 0.4*A1 + 0.1*A2 + 0.3*A3 = 0.523
O2 = 0.5*A1 + 0.2*A2 + 0.4*A3 = 0.72
Apply sigmoid activation function to each output neuron:
Y1 = 1 / (1 + exp(-O1)) = 0.628 ≈ 0.62
Y2 = 1 / (1 + exp(-O2)) = 0.675 ≈ 0.68
1. Input Layer to Hidden Layer:
Calculate weighted sums for each hidden neuron:
H1 = 0.1*0.5 + 0.3*0.8 + 0.5*0.2 + 0.2*0.6 = 0.51
H2 = 0.2*0.5 + 0.4*0.8 + 0.6*0.2 + 0.2*0.6 = 0.66
H3 = 0.3*0.5 + 0.5*0.8 + 0.7*0.2 + 0.2*0.6 = 0.81
Apply sigmoid activation function to each hidden neuron:
A1 = 1 / (1 + exp(-H1)) = 0.624
A2 = 1 / (1 + exp(-H2)) = 0.658
A3 = 1 / (1 + exp(-H3)) = 0.692
2. Hidden Layer to Output Layer:
Calculate weighted sums for each output neuron:
O1 = 0.4*A1 + 0.1*A2 + 0.3*A3 = 0.523
O2 = 0.5*A1 + 0.2*A2 + 0.4*A3 = 0.72
Apply sigmoid activation function to each output neuron:
Y1 = 1 / (1 + exp(-O1)) = 0.628 ≈ 0.62
Y2 = 1 / (1 + exp(-O2)) = 0.675 ≈ 0.68
Question 19 |
Which of the following are example of CSMA channel sensing methods?
(A) 1-persistent
(B) 2-persistent
(C) p-persistent
(D) o-persistent
Choose the correct answer from the options given below:
(A) 1-persistent
(B) 2-persistent
(C) p-persistent
(D) o-persistent
Choose the correct answer from the options given below:
(A), (B) and (D) Only | |
(A), (C) and (D) Only | |
(B), (C) and (D) Only | |
(A), (B) and (C) Only |
Question 19 Explanation:
A) 1-persistent:
A station with a frame to transmit immediately listens to the channel.
If the channel is idle, the station transmits immediately.
If the channel is busy, the station continues to listen until the channel becomes idle, and then transmits immediately.
(B) 2-persistent:
A station with a frame to transmit listens to the channel.
If the channel is idle, the station transmits with a probability of 2/3.
If the channel is busy, the station waits for a random amount of time and then repeats the process.
(C) p-persistent:
A station with a frame to transmit listens to the channel.
If the channel is idle, the station transmits with a probability of p (where 0 < p < 1).
If the channel is busy, the station waits for a fixed amount of time and then repeats the process.
A station with a frame to transmit immediately listens to the channel.
If the channel is idle, the station transmits immediately.
If the channel is busy, the station continues to listen until the channel becomes idle, and then transmits immediately.
(B) 2-persistent:
A station with a frame to transmit listens to the channel.
If the channel is idle, the station transmits with a probability of 2/3.
If the channel is busy, the station waits for a random amount of time and then repeats the process.
(C) p-persistent:
A station with a frame to transmit listens to the channel.
If the channel is idle, the station transmits with a probability of p (where 0 < p < 1).
If the channel is busy, the station waits for a fixed amount of time and then repeats the process.
Question 20 |
In the content of Alpha Beta pruning i in game trees which of the following statements are correct regarding cut off procedures
(A) Alpha Beta pruning can eliminate with certainly when the value of a node exceeds both the alpha and beta bonds.
(B) The primarily purpose of Alpha-pruning is to save computation time by searching fewer nodes in the same tree.
(C) Alpha Beta pruning the optimal solution in all cases by exploring the entire game tree.
(D) Alpha and Beta bonds are initialized to negative and positive infinity respectively at the root node.
Choose the correct answer from the options given below :
(A) Alpha Beta pruning can eliminate with certainly when the value of a node exceeds both the alpha and beta bonds.
(B) The primarily purpose of Alpha-pruning is to save computation time by searching fewer nodes in the same tree.
(C) Alpha Beta pruning the optimal solution in all cases by exploring the entire game tree.
(D) Alpha and Beta bonds are initialized to negative and positive infinity respectively at the root node.
Choose the correct answer from the options given below :
(A), (C), (D) only | |
(B), (C), (D) only | |
(A), (B), (D) only | |
(C ), (B) only |
Question 20 Explanation:
(A) Alpha Beta pruning can eliminate with certainty when the value of a node exceeds both the alpha and beta bounds.
This statement is correct. When the value of a node exceeds both the alpha and beta bounds, it means that the subtree rooted at that node does not need to be explored further because it cannot affect the final result due to pruning.
(B) The primary purpose of Alpha-Beta pruning is to save computation time by searching fewer nodes in the same tree.
This statement is correct. Alpha-Beta pruning aims to reduce the number of nodes evaluated during the search process, thus saving computational time by eliminating the need to explore certain branches of the game tree.
(C) Alpha Beta pruning finds the optimal solution in all cases by exploring the entire game tree.
This statement is incorrect. Alpha-Beta pruning does not guarantee finding the optimal solution in all cases. It may still miss the optimal solution if the optimal path is pruned early in the search. However, it does guarantee finding the optimal solution in certain cases, particularly in game trees with specific properties.
(D) Alpha and Beta bounds are initialized to negative and positive infinity, respectively, at the root node. This statement is correct. Typically, in Alpha-Beta pruning, the alpha and beta bounds are initialized to negative and positive infinity, respectively, at the root node before the search begins.
This statement is correct. When the value of a node exceeds both the alpha and beta bounds, it means that the subtree rooted at that node does not need to be explored further because it cannot affect the final result due to pruning.
(B) The primary purpose of Alpha-Beta pruning is to save computation time by searching fewer nodes in the same tree.
This statement is correct. Alpha-Beta pruning aims to reduce the number of nodes evaluated during the search process, thus saving computational time by eliminating the need to explore certain branches of the game tree.
(C) Alpha Beta pruning finds the optimal solution in all cases by exploring the entire game tree.
This statement is incorrect. Alpha-Beta pruning does not guarantee finding the optimal solution in all cases. It may still miss the optimal solution if the optimal path is pruned early in the search. However, it does guarantee finding the optimal solution in certain cases, particularly in game trees with specific properties.
(D) Alpha and Beta bounds are initialized to negative and positive infinity, respectively, at the root node. This statement is correct. Typically, in Alpha-Beta pruning, the alpha and beta bounds are initialized to negative and positive infinity, respectively, at the root node before the search begins.
Question 21 |
What is the output of the following program?
#include
# define SQR(x) (x*x)
int main () {
int a, b=3;
a = SQR(b+2);
printf("%d",a);
return 0;
}
#include
# define SQR(x) (x*x)
int main () {
int a, b=3;
a = SQR(b+2);
printf("%d",a);
return 0;
}
25 | |
11 | |
Garbage value | |
24 |
Question 21 Explanation:
1) 3 + 2 * 3 + 2
2) Perform multiplication: 3 + (2 * 3) + 2
3) Perform multiplication: 3 + 6 + 2
4) Perform addition: 11
2) Perform multiplication: 3 + (2 * 3) + 2
3) Perform multiplication: 3 + 6 + 2
4) Perform addition: 11
Question 22 |

(A), (B) and (C) Only | |
(B) and (C) Only | |
(C) (D) and (E) Only | |
(C) and (E) Only | |
∀n∃m |
Question 22 Explanation:
(A) ∀(n) ∃(m) (n^2 < m): This statement is false. It claims that for any integer n, there exists an integer m such that n^2 is less than m. However, this is not true for negative integers. For example, if n = -2, then n^2 = 4, and there is no integer m greater than 4.
(B) ∃(n) ∀(m) (n < m^2): This statement is also false. It claims that there exists an integer n such that for all integers m, n is less than m^2. However, this is not possible because for any integer n, there will always be an integer m such that m^2 is less than or equal to n.
(C) ∃(n) ∀(m) (nm = m): This statement is true. It claims that there exists an integer n such that for all integers m, the product of n and m is equal to m. This is true for the integer n = 1, as 1 multiplied by any integer m equals m.
(D) ∃(n) ∃(m) (n^2 + m^2 = 6): This statement is false. It claims that there exist integers n and m such that the sum of their squares is 6. However, the only way to get a sum of 6 from two squares is 1^2 + 1^2 = 2 or 2^2 + 2^2 = 8, neither of which equals 6.
(E) ∃(n) ∃(m) (n + m=4 AND n-m=1): This statement is true. It claims that there exist integers n and m such that their sum is 4 and their difference is 1. This is true for the integers n = 2.5 and m = 1.5, as 2.5 + 1.5 = 4 and 2.5 - 1.5 = 1.
(B) ∃(n) ∀(m) (n < m^2): This statement is also false. It claims that there exists an integer n such that for all integers m, n is less than m^2. However, this is not possible because for any integer n, there will always be an integer m such that m^2 is less than or equal to n.
(C) ∃(n) ∀(m) (nm = m): This statement is true. It claims that there exists an integer n such that for all integers m, the product of n and m is equal to m. This is true for the integer n = 1, as 1 multiplied by any integer m equals m.
(D) ∃(n) ∃(m) (n^2 + m^2 = 6): This statement is false. It claims that there exist integers n and m such that the sum of their squares is 6. However, the only way to get a sum of 6 from two squares is 1^2 + 1^2 = 2 or 2^2 + 2^2 = 8, neither of which equals 6.
(E) ∃(n) ∃(m) (n + m=4 AND n-m=1): This statement is true. It claims that there exist integers n and m such that their sum is 4 and their difference is 1. This is true for the integers n = 2.5 and m = 1.5, as 2.5 + 1.5 = 4 and 2.5 - 1.5 = 1.
Question 23 |
2-3-4 trees are B-trees of order 4. They are isometric of _____ trees
AVL | |
AA | |
2-3 | |
Red-Black |
Question 23 Explanation:
2-3-4 trees and Red-Black trees are known to be isometric, meaning they can be transformed into each other while preserving their key properties and order. While both are balanced search trees, they achieve balance in different ways.
Question 24 |
The statement P(x): “x=x^2” .If the universe of disclosure consists of integers, which of the following have truth values
(A) P(0)
(B) P(1)
(C) P(2)
(D) ∃x P(x)
(E) ∀x P(X)
Choose the correct answer from the options given below
(A) P(0)
(B) P(1)
(C) P(2)
(D) ∃x P(x)
(E) ∀x P(X)
Choose the correct answer from the options given below
(A), (B) and (E) Only | |
(A), (B) and (C) Only | |
(A), (B) and (D) Only | |
(B), (C) and (D) Only |
Question 24 Explanation:
(A) P(0): True, because 0 = 0^2.
(B) P(1): True, because 1 = 1^2.
(C) P(2): False, because 2 ≠ 2^2.
(D) ∃x P(x): True, because there exists at least one integer x (namely, 0 and 1) for which P(x) is true. (E) ∀x P(x): False, because not all integers satisfy the condition x = x^2.
Therefore, only statements (A), (B), and (D) have truth values in the given universe of discourse, making the answer
(B) P(1): True, because 1 = 1^2.
(C) P(2): False, because 2 ≠ 2^2.
(D) ∃x P(x): True, because there exists at least one integer x (namely, 0 and 1) for which P(x) is true. (E) ∀x P(x): False, because not all integers satisfy the condition x = x^2.
Therefore, only statements (A), (B), and (D) have truth values in the given universe of discourse, making the answer
Question 25 |
Match List-I with List-II.

Choose the correct answer the options given below :
Choose the correct answer the options given below :
(II),(B)-(IV),(C)-(I),(D)-(III) | |
(II),(B)-(III),(C)-(I),(D)-(IV) | |
(III),(B)-(II),(C)-(IV),(D)-(I) | |
(III),(B)-(IV),(C)-(II),(D)-(I) |
There are 25 questions to complete.