subject wise questions
| Question | ALL_ANSWERS | CORRECT_ANSWER | Explanation | subject | Topic | v_e |
|---|---|---|---|---|---|---|
| The difference between a named pipe and a regular file in Unix is that | 1. Unlike a regular file, named pipe is a special file, 2. The data in a pipe is transient, unlike the content of a regular file, 3. Pipes forbid random accessing, while regular files do allow this., 4. All of the above | 4. All of the above | → Named pipe is a special instance of a file that has no contents on the filesystem. → A FIFO special file (a named pipe) is similar to a pipe, except that it is accessed as part of the filesystem. It can be opened by multiple processes for reading or writing. When processes are exchanging data via the FIFO, the kernel passes all data internally without writing it to the filesystem. Thus, the FIFO special file has no contents on the filesystem; the filesystem entry merely serves as a reference point so that processes can access the pipe using a name in the filesystem. → The kernel maintains exactly one pipe object for each FIFO special file that is opened by at least one process. The FIFO must be opened on both ends (reading and writing) before data can be passed. Normally, opening the FIFO blocks until the other end is opened also. |
Operating-Systems | UNIX-Operating-System | https://youtu.be/7sbOzZsfzdQ |
| A class of 30 students occupy a classroom containing 5 rows of seats, with 8 seats in each row. If the students seat themselves at random, the probability that the sixth seat in the fifth row will be empty is | 1. 1/5, 2. 1/3, 3. 1/4, 4. 2/5 | 3. 1/4 | Step-1: Given, 5 rows with 8 seats in each row. Total number of seats = 5*40 = 40 seats Total number of students= 30 Step-2: Given constraint that, 6th seat in the fifth row is empty When we are deleting 6th seat, 30 students have 39 choices of seats Step-3: Total number of choices = 39C30 Total ways to choose = 40C30 Step-4: Final probability = 39C30 / 40C30 = 1/4 |
Engineering-Mathematics | Probability | https://youtu.be/uGkPacIvMKg |
| The domain of the function log( log sin(x) ) is | 1. 0 < x < π , 2. 2nπ < x < (2n+1)π , for n in N, 3. Empty set, 4. None of the above | 3. Empty set | → The range of sinx value lies between -1 and 1 and whereas log(sinx) value will be the positive value. → So the domain of log(log sin(x)) is undefined which is empty Set. |
Engineering-Mathematics | Calculus | https://youtu.be/-JHQt5Zn2x4 |
| The following paradigm can be used to find the solution of the problem in minimum time: Given a set of non-negative integer, and a value K, determine if there is a subset of the given set with the sum equal to K: | 1. Divide and Conquer, 2. Dynamic Programming, 3. Greedy Algorithm, 4. Branch and Bound | 2. Dynamic Programming | The above problem clearly specifies that sum of subset problem. The sum of the subset problem using recursion will give exponential time. Using dynamic programming we can get pseudo-polynomial time. Sum of subset problem: Given a set of non-negative integers, and a value sum, determine if there is a subset of the given set with the sum equal to the given sum. Example: Array set[ ]= {1,2,3,4,5} and sum=6 Here there are possible subsets (2,4),(1,2,3) and (5,1). |
Algorithms | Dynamic-Programming | https://youtu.be/WY1IbgmfvRw |
| ( G, *) is an abelian group. Then | 1. x = x-1, for any x belonging to G, 2. x = x2, for any x belonging to G, 3. (x * y )2 = x2 * y2, for any x, y belonging to G, 4. G is of finite order | 3. (x * y )2 = x2 * y2, for any x, y belonging to G | An abelian group is a commutative group. As per the above options, option C is the correct answer because it follows commutative property. (x * y )2 = x2 * y2, for any x, y belonging to G |
Engineering-Mathematics | Set-Theory | https://youtu.be/NTi1j1m3sT0 |
Consider the following C code segment:  For the program fragment above, which of the following statements about the variables i and j must be true after the execution of this program? [!(exclamation) sign denotes factorial in the Solution] |
1. ( j=(x-1)!) ∧ (i>=x), 2. ( j = 9!) ∧ (i =10), 3. (( j = 10!) ∧ (i = 10 )) V (( j = (x - 1)!) ∧ (i = x )), 4. (( j = 9!) ∧ (i = 10)) V (( j = (x - 1)!) ∧ (i = x )) | 4. (( j = 9!) ∧ (i = 10)) V (( j = (x - 1)!) ∧ (i = x )) | As per code segment, Step-1: The ith loop will compute from value 1 to 9. If the condition is true, then it computes j=j*i statement. Step-2: The statement j=j*i is nothing but calculating 9!. If the condition fails automatically while loop will be terminated. It means maximum we can execute 9 values. Step-3: when x becomes 10 then maximum I value will be 9. So, we can calculate up to 9! And I become 10 then it terminates the condition. |
Programming-for-Output-Problems | Control Flow | https://youtu.be/kQ3KB2pNHL0 |
| A computer uses ternary system instead of the traditional binary system. An n bit string in the binary system will occupy | 1. 3+n ternary digits, 2. 2n/3 ternary digits, 3. n(log23) ternary digits, 4. n(log32 ) ternary digits | 4. n(log32 ) ternary digits | → Binary numbers are maximum 2n-1. → But in question they are given ternary numbers, it means 3x-1. → Both will take different no. of bits to represent the same number. 3x -1 = 2n -1 3x = 2n Apply log on both side x= log3( 2n) x=n*log32 . |
Digital-Logic-Design | Number-Systems | https://youtu.be/xmbwMBZYquk |
| Which of the following is application of Breadth First Search on the graph? | 1. Finding the diameter of the graph, 2. Finding the bipartite graph, 3. Both (a) and (b), 4. None of the above | 3. Both (a) and (b) | Breadth-first search can be used to solve many problems in graph theory Examples 1. Copying garbage collection, Cheney\'s algorithm 2. Find the diameter of the graph 3. Testing bipartiteness of a graph. 4. Finding the shortest path between two nodes u and v, with path length measured by the number of edges (an advantage over depth-first search) 5. (Reverse) Cuthill–McKee mesh numbering 6. Ford–Fulkerson method for computing the maximum flow in a flow network 7. Serialization/Deserialization of a binary tree vs serialization in sorted order, allows the tree to be reconstructed in an efficient manner. 8. Construction of the failure function of the Aho-Corasick pattern matcher. |
Data-Structures | Graphs | https://youtu.be/PT2jTgy7AcM |
| Micro program is | 1. The name of a source program in microcomputers, 2. Set of micro instructions that define the individual operations in response to a machine-language instruction, 3. A primitive form of macros used in assembly language programming, 4. A very small segment of machine code | 2. Set of micro instructions that define the individual operations in response to a machine-language instruction | → The Microprogram is computing a sequence of microinstructions that controls the operation of an arithmetic and logic unit so that machine code instructions are executed. → The Microprogram is set of microinstructions that define the individual operations in response to a machine-language instruction |
Computer-Organization | Microprogram | https://youtu.be/xPz8Vc3x5fg |
| Given two sorted list of size m and n respectively. The number of comparisons needed the worst case by the merge sort algorithm will be | 1. m*n, 2. maximum of m and n, 3. minimum of m and n, 4. m+n–1 | 4. m+n–1 | Here the maximum number of comparisons is m+n-1. For example: Take 2 sub-arrays of size 3 such as 1,3,5 and another subarray 2,4,6. Then in this case number of comparisons is 5 which is m+n-1 can be taken as O(m+n). |
Algorithms | Sorting | https://youtu.be/SBKN0pjT2kQ |
| In unit testing of a module, it is found that for a set of test data, at the maximum 90% of the code alone were tested with the probability of success 0.9. The reliability of the module is | 1. Greater than 0.9, 2. Equal to 0.9, 3. At most 0.81, 4. At least 0.81 | 3. At most 0.81 | Given data Step-1: 90% of code were tested, Testing with the probability=0.9 Step-2: We can write tested data into 0.9 because it is given in percentages. Step-3: Reliability of the module = Tested data * probability = 0.9 * 0.9 = 0.81(at most) |
Software-Engineering | Software-testing | https://youtu.be/-tf6QCpN8_g |
| In a file which contains 1 million records and the order of the tree is 100, then what is the maximum number of nodes to be accessed if B+ tree index is used? | 1. 5, 2. 4, 3. 3, 4. 10 | 2. 4 | Explanation: → If there are K search-key values in the file, the path is no longer than ⌈log⌈n/2⌉(K)⌉. → A node is generally the same size as a disk block, typically 4 kilobytes, and n is typically around 100 (40 bytes per index entry). → With 1 million search key values and n = 100, at most log50(1000000)=4 nodes are accessed in a lookup. Note: Contrast this with a balanced binary free with 1 million search key values around 20 nodes are accessed in a lookup. Above difference is significant since every node access may need a disk I/O, costing around 20 milliseconds! |
Database-Management-System | B-and-B+-Trees | https://youtu.be/5MEM6Kcl1kc |
| A particular disk unit uses a bit string to record the occupancy or vacancy of its tracks, with 0 denoting vacant and 1 for occupied. A 32-bit segment of this string has hexadecimal value D4FE2003. The percentage of occupied tracks for the corresponding part of the disk, to the nearest percentage is | 1. 12, 2. 25, 3. 38, 4. 44 | 4. 44 | Computer-Organization | Secondary-Memory | https://youtu.be/fAipolg5N4A | |
| The Boolean expression Y = (A + B\' + A\'B)C\' is given by | 1. AC\', 2. BC\', 3. C\', 4. A | 3. C\' | Y = (A + B\' + A\'B)C\' Y = AC\' + B\'C\' + A\'BC\' Y = (A + A\'B)C\' + B\'C\' Y = (A + B)C\' + B\'C\' Y = AC\' + BC\' + B\'C\' Y = AC\' + C\'(B + B\') → B + B\' = 1 Y = AC\' + C\' Y = C\' |
Digital-Logic-Design | Boolean-Algebra | |
| Which of the following is a dense index? | 1. Primary index, 2. Clusters index, 3. Secondary index, 4. secondary non-key index | 3. Secondary index | → The primary index is created for the primary key of a table. So, records are usually clustered according to the primary key. It can be sparse. → In the sparse index, index records are not created for every search key. An index record here contains a search key and an actual pointer to the data on the disk. To search a record, we first proceed by index record and reach the actual location of the data. If the data we are looking for is not where we directly reach by following the index, then the system starts a sequential search until the desired data is found. → The secondary index usually dense. → In the dense index, there is an index record for every search key value in the database. This makes searching faster but requires more space to store index records itself. Index records contain search key value and a pointer to the actual record on the disk. |
Database-Management-System | B-and-B+-Trees | https://youtu.be/g0dnXaLnn6A |
| In E-R model, Y is the dominant entity and X is a subordinate entity | 1. If X is deleted, then Y is also deleted, 2. If Y is deleted, then X is also deleted, 3. If Y is deleted, then X is not deleted, 4. None of the above | 2. If Y is deleted, then X is also deleted | → It is the best example of referential integrity. In referential integrity, we are using a foreign key. → If we want to delete any entity in the dominant entity(Like primary key of a table) then subordinate entity(derived attribute) also deleted. Note: If we want to delete any subordinate entity in entity then the dominant entity is not going to delete. |
Database-Management-System | ER-Model | https://youtu.be/8D-UT7lP3d4 |
| Of the following, which best characterizes computers that use memory-mapped I/O? | 1. The computer provides special instructions for manipulating I/O ports, 2. I/O ports are placed at addresses on the bus and are accessed just like other memory locations, 3. To perform I/O operations, it is sufficient to place the data in an address register and call channel to perform the operation, 4. I/O can be performed only when memory management hardware is turned on | 2. I/O ports are placed at addresses on the bus and are accessed just like other memory locations | → Memory-mapped I/O uses the same address space to address both memory and I/O devices. → The memory and registers of the I/O devices are mapped to (associated with) address values. → So when an address is accessed by the CPU, it may refer to a portion of physical RAM, or it can instead refer to the memory of the I/O device. Thus, the CPU instructions used to access the memory can also be used for accessing devices. → Each I/O device monitors the CPU\'s address bus and responds to any CPU access of an address assigned to that device, connecting the data bus to the desired device\'s hardware register. → To accommodate the I/O devices, areas of the addresses used by the CPU must be reserved for I/O and must not be available for normal physical memory. → The reservation may be permanent, or temporary (as achieved via bank switching). |
Computer-Organization | Hardware Devices | https://youtu.be/mexy27bguw4 |
The circuit shown in the following figure realizes the function  |
1. (( A + B )’ +C ) ( D’E’ )), 2. (( A + B )’ + C ) ( DE’ )), 3. ( A + ( B + C )’ ) ( D’E ), 4. ( A + B + C’ ) ( D’E’ ) | 1. (( A + B )’ +C ) ( D’E’ )) | The given function is equivalent to the following expression: Y = (((A + B)\' + C)\' + ((D + E)\')\')\' Y = ((A + B)\' + C)\')\' . (D + E)\' Y = ((A + B)\' + C) (D\'E\') |
Digital-Logic-Design | Combinational-Circuit | |
The circuit shown in the given figure is a 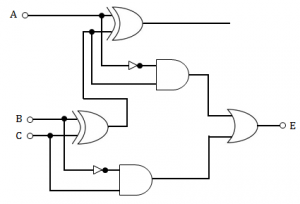 |
1. full adder, 2. full subtractor, 3. shift register, 4. decade counter | 2. full subtractor | The above diagram is full subtractor. The equation is D=X⊕Y⊕Bin and Bout=X\'Bin+X\'Y+YBin | Digital-Logic-Design | Combinational-Circuit | |
| When two numbers are added in excess-3 code and the sum is less than 9, then in order to get the correct answer it is necessary to | 1. subtract 0011 from the sum, 2. add 0011 to the sum , 3. subtract 0110 from the sum , 4. add 0110 to the sum | 1. subtract 0011 from the sum | Subtract 0011 if there is no carry otherwise add 0011. Example: x+3 y+3 ------- (x+y+6) Here, sum is excess-6. Hence, subtract 0011 to make it excess-3. |
Digital-Logic-Design | Number-Systems | |
| Of the following sorting algorithms, which has a running time that is least dependent on the initial ordering of the input? | 1. Merge Sort, 2. Insertion Sort, 3. Selection Sort, 4. Quick Sort | 1. Merge Sort | 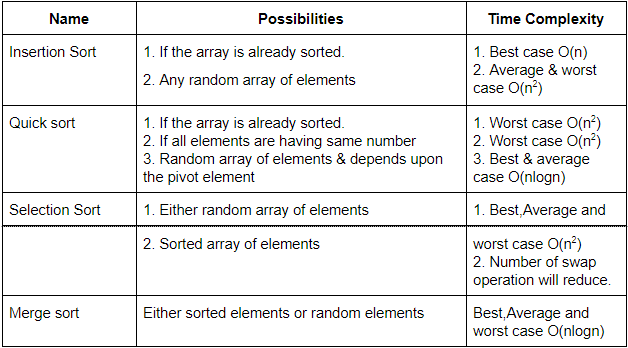 |
Algorithms | Sorting | https://youtu.be/AYiF-OXC44I |
Processes P1 and P2 have a producer-consumer relationship, communicating by the use of a set of shared buffers.  Increasing the number of buffers is likely to do which of the following? I. Increase the rate at which requests are satisfied (throughput) II. Decrease the likelihood of deadlock III. Increase the ease of achieving a correct implementation |
1. III Only, 2. II Only, 3. I Only, 4. II and III Only | 3. I Only | It only satisfied statement I. because increasing the memory size increases the rate at which requests are satisfied but can not alter the possibility of deadlock and neither does it play any role in implementation. | Operating-Systems | Deadlock | https://youtu.be/Sm2Y25wMWws |
A doubly linked list is declared as style=font-weight: 400;>Where Fwd and Bwd represent forward and a backward link to the adjacent elements of the list. Which of the following segments of code deletes the node pointed to by X from the doubly linked list, if it is assumed that X points to neither the first nor the last node of the list? |
1. X→ Bwd→ Fwd = X→ Fwd; X→ Fwd → Bwd = X→ Bwd ;, 2. X→ Bwd.Fwd = X→ Fwd ; X.Fwd→ Bwd = X→ Bwd ;, 3. X.Bwd→ Fwd = X.Bwd ; X→ Fwd.Bwd = X.Bwd ;, 4. X→ Bwd→ Fwd = X→ Bwd ; X→ Fwd→ Bwd = X→ Fwd; | 1. X→ Bwd→ Fwd = X→ Fwd; X→ Fwd → Bwd = X→ Bwd ; | Let the element just before x be y and that just after be z. In order to link y to z, we need x→ Bwd→ Fwd = x. Fwd and in order to link z to y, we need x→ Fwd→ Bwd=x→ Bwd. |
Data-Structures | Linked-List | https://youtu.be/T1XbFRYfcb0 |
If Tree-1 and Tree-2 are the trees indicated below : 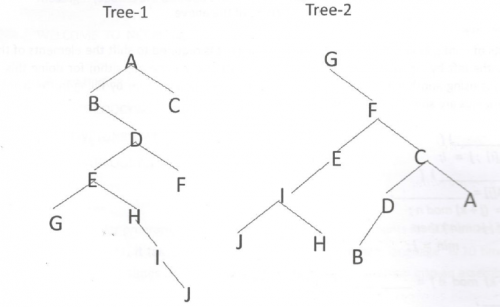 Which traversals of Tree-1 and Tree-2, respectively, will produce the same sequence? |
1. Preorder, Postorder, 2. Postorder, Inorder, 3. Postorder, Preorder, 4. Inorder, Preorder | 2. Postorder, Inorder | → Pre order traverses Root, Left, Right. → Post order traverses Left, Right, Root. → In-order traverses Left, Root, Right. Tree-1: Post order: GJIHEFBDCA Tree-2: In order: GJIHEFBDCA |
Data-Structures | Binary-Trees | https://youtu.be/oBrZxLBxQ1E |
In the diagram above, the inverter (NOT gate) and the AND-gates labelled 1 and 2 have delays of 9, 10 and 12 nanoseconds(ns), respectively. Wire delays are negligible. For certain values of a and c, together with the certain transition of b, a glitch (spurious output) is generated for a short time, after which the output assumes its correct value. The duration of the glitch is 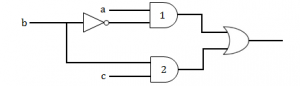 |
1. 7ns, 2. 9ns, 3. 11ns, 4. 13ns | 1. 7ns | Step-1: Inverter→ NOT gate(b’) will generate 9ns Step-2: 1st AND gate(ab’) takes 19ns because combining NOT gate(9ns)+extra(10ns) Step-3: Second AND gate(bc) takes only 12ns because we are not using inverter here. Step-4: A glitch will take 1st AND gate(ab’) - Second AND gate(bc) =19-12 =7ns |
Digital-Logic-Design | Logic-Gates | https://youtu.be/AD9RjErr3Ok |
| The characteristic equation of an SR flip-flop is given by | 1. Qn+1 = S + RQn, 2. Qn+1= RQ’n + SQn, 3. Qn+1= S’ + RQn, 4. Qn+1 = S + R’Qn | 4. Qn+1 = S + R’Qn | The characteristic table of an SR flip-flop is: 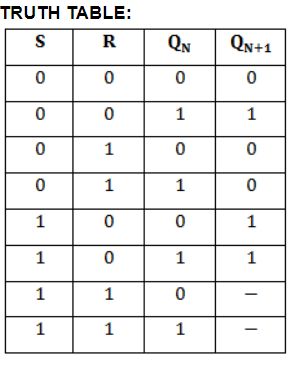 So, by simplifying using k-maps: characteristic equation of an SR flip-flop = Qn+1 = S + R’Qn |
Digital-Logic-Design | Sequential-Circuits | |
| A graph with n vertices and n-1 edges that is not a tree, is | 1. Connected, 2. Disconnected, 3. Euler, 4. A circuit | 2. Disconnected | Consider a graph with two nodes(n1&n2) and number of edges are 1, There may be chance self edge with node n1 then graph is disconnected. Consider the graph with three nodes(n1,n2&n3) and has 2 edges. n1-->n2 and n2--->n1 then the graph is disconnected. |
Engineering-Mathematics | Graph-Theory | |
| If a graph requires k different colours for its proper colouring, then the chromatic number of the graph is | 1. 1, 2. k, 3. k-1, 4. k/2 | 2. k | The chromatic number of a graph is the smallest number of colors needed to color the vertices of so that no two adjacent vertices share the same color and if a graph requires k different colours for its proper colouring, then k is the chromatic number of the graph. | Engineering-Mathematics | Graphs | |
| A read bit can be read | 1. and written by CPU, 2. and written by peripheral, 3. by peripheral and written by CPU, 4. by CPU and written by the peripheral | 4. by CPU and written by the peripheral | The read and write functionality depends on the type of microcontroller peripheral. Generally, the status bits have a read only status and can be modified by peripherals only. So, read bit can be read by CPU and written by the peripheral. | Computer-Organization | RAID | |
| Which of the following comparisons between static and dynamic type checking is incorrect? | 1. Dynamic type checking slows down the execution, 2. Dynamic type checking offers more flexibility to the programmers, 3. In contrast to Static type checking, dynamic type checking may cause failure in runtime due to type errors, 4. Unlike static type checking, dynamic type checking is done during compilation | 4. Unlike static type checking, dynamic type checking is done during compilation | → Type checking is the process of verifying and enforcing the constraints of types, and it can occur either at compile time (i.e. statically) or at runtime (i.e. dynamically). → Type checking is all about ensuring that the program is type-safe, meaning that the possibility of type errors is kept to a minimum. → A language is statically-typed if the type of a variable is known at compile time instead of at runtime. Common examples of statically-typed languages include Ada, C, C++, C#, JADE, Java, Fortran, Haskell, ML, Pascal, and Scala. → Dynamic type checking is the process of verifying the type safety of a program at runtime. Common dynamically-typed languages include Groovy, JavaScript, Lisp, Lua, Objective-C, PHP, Prolog, Python, Ruby, Smalltalk and Tcl. |
Compiler-Design | Compilers | https://youtu.be/0RqGU_02hok |
| The term ‘aging’ refers to | 1. booting up the priority of the process in multi-level of queue without feedback, 2. keeping track of the following a page has been in memory for the purpose of LRU replacement, 3. letting job reside in memory for a certain amount of time so that the number of pages required can be estimated accurately, 4. gradually increasing the priority of jobs that wait in the system for a long time to remedy infinite blocking, 5. In Operating systems, aging is a scheduling technique used to avoid starvation. In this, the priority of the jobs that have a longer waiting time is increased as compared to the newer processes, to avoid the starvation of older processes | 4. gradually increasing the priority of jobs that wait in the system for a long time to remedy infinite blocking | Operating-Systems | Memory-Management | ||
| _______ can detect burst error of length less than or equal to degree of the polynomial and detects burst errors that affect odd number of bits. | 1. Hamming Code, 2. CRC, 3. VRC, 4. None of the above | 2. CRC | → A cyclic redundancy check (CRC) is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to raw data. CRCs can be used for error correction → The design of the CRC polynomial depends on the maximum total length of the block to be protected (data + CRC bits), the desired error protection features, and the type of resources for implementing the CRC, as well as the desired performance. → A common misconception is that the \"best\" CRC polynomials are derived from either irreducible polynomials or irreducible polynomials times the factor 1 + x, which adds to the code the ability to detect all errors affecting an odd number of bits. → If we use the generator polynomial g(x)=p(x)(1+x), where p(x) is a primitive polynomial of degree r−1, then the maximal total block length is 2r−1 −1 , and the code is able to detect single, double, triple and an odd number of errors. |
Computer-Networks | CRC | https://youtu.be/1eFCbLKKj6Y |
| Station A uses 32-byte packets to transmit messages to Station B using a sliding window protocol. The round trip delay between A and B is 80 ms and the bottleneck bandwidth on the path between A and B is 128 kbps. What is the optimal window size that A should use? | 1. 20, 2. 40, 3. 160, 4. 320 | 2. 40 | Tt = L / B = 32 bytes/ 128 kbps = 32*8/128 ms = 2 ms Round trip delay = 2 * Tp = 80 ms (given) Optimal window size is = (Tt + 2*Tp) / Tt = 82 / 2 = 41 Option is not given, closest option is 40. |
Computer-Networks | Control-Flow-Methods | https://youtu.be/WAaEKAn-Xjs |
| Assuming that for a given network layer implementation, connection establishment overhead is 100 bytes and disconnection overhead is 28 bytes. What would be the minimum size of the packet the transport layer needs to keep up if it wishes to implement a datagram service above the network needs to keep its overhead to a minimum of 12.5%. (Ignore transport layer overhead) | 1. 512 bytes, 2. 768 bytes, 3. 1152 bytes, 4. 1024 bytes | 4. 1024 bytes | → Given a question is based on circuit-switching. → In circuit-switching, the total time required to send data = Setup connection time + Transfer time + Teardown the connection time → In datagram-service, the total time required to send data = N*Setup connection time + Transfer time |
Computer-Networks | Switching | https://youtu.be/EABZNEHnMkI |
| Consider a set of n tasks with known runtimes r1, r2….rn to be run on a uniprocessor machine. Which of the following processor scheduling algorithms will result in the maximum throughput? | 1. Round Robin, 2. Shortest job first, 3. Highest response ratio next, 4. first come first served | 2. Shortest job first | Throughput means total number of tasks executed per unit time i.e. sum of waiting time and burst time. Shortest job first scheduling is a scheduling policy that selects the waiting process with the smallest execution time to execute next. Thus, in shortest job first scheduling, shortest jobs are executed first. This means CPU utilization is maximum. So, maximum number of tasks are completed. |
Operating-Systems | CPU-Scheduling | |
| Consider a job scheduling problem with 4 jobs J1, J2, J3, J4 and with corresponding deadlines: ( d1, d2, d3, d4) = (4, 2, 4, 2). Which of the following is not a feasible schedule without violating any job schedule? |
1. J2, J4, J1, J3, 2. J4, J1, J2, J3., 3. J4, J2, J1, J3., 4. J4, J2, J3, J1 | 2. J4, J1, J2, J3. | → Feasible schedule is completing all the jobs within deadline. → From the dead line, we can deduce that Job J2 & J4 will complete by time “2” whereas remaining two requires time “4”. → So the order of completion of Jobs are Either J2 or J4 and followed by either J1 or J3. From the given options , Option A,C & D gives the solution because after completion of Jobs J2 and J4 then only jobs J1 and J3 is going to complete. → But option B , order of completing jobs is J4,J1,J2 ,J3 which is not possible and it is not feasible schedule |
Operating-Systems | Deadlock | |
| In cryptography, the following uses transposition cyphers and the keyword is LAYER. Encrypt the following message. (Spaces are omitted during encryption) WELCOME TO NETWORK SECURITY! | 1. WMEKREETSILTWETCOOCYONRU!, 2. EETSICOOCYWMEKRONRU!LTWET, 3. LTWETONRU!WMEKRCOOCYEETSI, 4. ONRU!COOCYLTWETEETSIWMEKR | 2. EETSICOOCYWMEKRONRU!LTWET |  |
Computer-Networks | Network-Security | https://youtu.be/DVd8iDvi1Mo |
| By using an eight-bit optical encoder the degree of resolution that can be obtained is (approximately) | 1. 1.8o, 2. 3.4o, 3. 2.8o, 4. 1.4o | 4. 1.4o | An optical encoder is an electromechanical device which has an electrical output in digital form proportional to the angular position of the input shaft. Optical encoders enable an angular displacement to be converted directly into a digital form. Encoder resolution is often referred to in bits, which are binary units: a 16 bit resolution rotary encoder will have 65,536 (216) increments per turn, or PPR. In the given question, 8-bit optical encoder will have 28 increments Resolution = 360/2n = 360/28 = 1.4o |
Digital-Logic-Design | Combinational-Circuit | |
| The principal of the locality of reference justifies the use of | 1. virtual memory, 2. interrupts, 3. main memory , 4. cache memory | 4. cache memory | Spatial Locality of reference – this says that there is chance that element will be present in the close proximity to the reference point and next time if again searched then more close proximity to the point of reference. Temporal Locality of reference – In this Least recently used algorithm will be used. Whenever there is page fault occurs within word will not only load word in main memory but complete page fault will be loaded because spatial locality of reference rule says that if you are referring any word next word will be referred in its register that’s why we load complete page table so complete block will be loaded. Principle of locality of reference justifies the use of cache. |
Computer-Organization | Cache | |
| Consider the following pseudo-code x:=1; i:=1; while (x <= 1000) begin x:=2^x; i:=i+1; end; What is the value of i at the end of the pseudo-code? |
1. 4, 2. 5, 3. 6, 4. 7 | 2. 5 | Initialisation: x = 1, i = 1; Loop: x i 21 2 22 3 24 4 216 5 After this condition becomes false. |
Programming | Control Flow | |
| In a particular program, it is found that 1% of the code accounts for 50% of the execution time. To code a program in C++, it takes 100 man-days. Coding in assembly language is 10 times harder than coding in C++ but runs 5 times faster. Converting an existing C++ program into an assembly language program is 4 times faster. To completely write the program in C++ and rewrite the 1% code in assembly language, if a project team needs 13 days, the team consists |
1. 13 programmers, 2. 10 programmers, 3. 8 programmers, 4. 100/13 programmers | 3. 8 programmers |  |
Software-Engineering | Software-Reliability | https://youtu.be/7iSBpW7K6eE |
| The five items: A, B, C, D, and E are pushed in a stack, one after other starting from A. The stack is popped four items and each element is inserted in a queue. The two elements are deleted from the queue and pushed back on the stack. Now one item is popped from the stack. The popped item is | 1. A, 2. B, 3. C, 4. D | 4. D | When five items: A, B, C, D, and E are pushed in a stack: Order of stack becomes: A, B, C, D, and E (A at the bottom and E at the top.) stack is popped four items and each element is inserted in a queue: Order of queue: B, C, D, E (B at rear and E at the front) Order of stack after pop operations = A. Two elements deleted from the queue and pushed back stack: New order of stack = A, E, D(A at the bottom, D at the top) As D is on the top so when pop operation occurs D will be popped out. So, correct option is (D). | Data-Structures | Queues-and-Stacks | |
| Round Robin schedule is essentially the preemptive version of | 1. FIFO, 2. Shortest job first, 3. Shortest remaining time, 4. Longest remaining time | 1. FIFO | FIFO is when implemented in preemptive version, it acts like round-robin algorithm. | Operating-Systems | CPU-Scheduling | |
| Incremental Compiler is a compiler | 1. which is written in a language that is different from the source language, 2. compiles the whole source code to generate object code afresh, 3. compiles only those portion of source code that has been modified., 4. that runs on one machine but produces object code for another machine | 3. compiles only those portion of source code that has been modified. | Types of compilers 1. Incremental compiler: It rebuilds all program modules, incremental compiler re-compiles only those portions of a program that have been modified. 2. Cross-compiler: If the compiled program can run on a computer whose CPU or operating system is different from the one on which the compiler runs, the compiler is a cross-compiler. 3. A bootstrap compiler: is written in the language that it intends to compile. A program that translates from a low-level language to a higher level one is a decompiler. 4. Source-to-source compiler or transpiler: A program that translates between high-level languages is usually called a source-to-source compiler or transpiler. |
Compiler-Design | Compilers | https://youtu.be/0aRORQa3Irc |
| The number of digit 1 present in the binary representation of 3 × 512 + 7 × 64 + 5 × 8 + 3 | 1. 8, 2. 9, 3. 10, 4. 12 | 2. 9 | 3 × 512 + 7 × 64 + 5 × 8 + 3 = (2 + 1)× 512 + (4 + 2 + 1)× 64 + (4 + 1)× 8 + 2 + 1 = 1024 + 512 + 64 x 4 + 64 x 2 + 64 + 32 + 8 + 2 + 1 = 1024 + 512 + 256 + 128 + 64 + 32 + 8 + 2 + 1 As 1024 has ten 0’s followed by 1, 512 has nine 0’s followed by 1 and so on.. So, the expression will contain total nine 1’s and will be be represented as 11111101011. |
Digital-Logic-Design | Number-Systems | |
| Assume that each character code consists of 8 bits. The number of characters that can be transmitted per second through an synchronous serial line at 2400 baud rate, and with two stop bits is | 1. 109, 2. 216, 3. 300, 4. 219 | 3. 300 | Synchronous communication requires that the clocks in the transmitting and receiving devices are synchronized – running at the same rate – so the receiver can sample the signal at the same time intervals used by the transmitter. No start or stop bits are required. For this reason “synchronous communication permits more information to be passed over a circuit per unit time. 2400 baud means that the serial port is capable of transferring a maximum of 2400 bits per second. Number of 8-bit characters that can be transmitted per second = 2400/8 = 300 |
Computer-Organization | Synchronous-and-asynchronous-Communication | |
| DU-chains(Definition-Use) in compiler design | 1. Consist of a definition of a variable and all its uses, reachable from that definition, 2. Are created using a form of static code analysis, 3. Are prerequisite for many compiler optimization including constant propagation and common sub-expression elimination, 4. All of the above | 4. All of the above | → A Use-Definition Chain (UD Chain) is a data structure that consists of a use, U, of a variable, and all the definitions, D, of that variable that can reach that use without any other intervening definitions. A definition can have many forms but is generally taken to mean the assignment of some value to a variable (which is different from the use of the term that refers to the language construct involving a data type and allocating storage). → A counterpart of a UD Chain is a Definition-Use Chain (DU Chain), which consists of a definition, D, of a variable and all the uses, U, reachable from that definition without any other intervening definitions. → Both UD and DU chains are created by using a form of static code analysis known as data flow analysis. Knowing the use-def and def-use chains for a program or subprogram is a prerequisite for many compiler optimizations, including constant propagation and common subexpression elimination. |
Compiler-Design | Compilers | https://youtu.be/yIeFWlkiLig |
| If the bandwidth of a signal is 5 kHz and the lowest frequency is 52 kHz, what is the highest frequency | 1. 5 kHz, 2. 10 kHz, 3. 47 kHz, 4. 57 kHz | 4. 57 kHz | Bandwidth = Highest frequency - Lowest frequency. Highest frequency = Bandwidth+ Lowest Frequency= 5kHz + 52kHz = 57kHz. |
Computer-Networks | Bandwidth-Frequency | |
| An Ethernet hub | 1. functions as a repeater, 2. connects to a digital PBX, 3. connects to a token-ring network, 4. functions as a gateway | 1. functions as a repeater | A Hub is a network hardware device for connecting multiple Ethernet devices together and making them act as a single network segment. A repeater is an electronic device that receives a signal and re-transmits it. Repeaters are used to extend transmissions so that the signal can cover longer distances or be received on the other side of an obstruction. An Ethernet Hub or a Repeater Hub also acts as a repeater and regenerates the signal to avoid its loss. |
Computer-Networks | Ethernet | |
| Phase transition for each bit are used in | 1. Amplitude modulation, 2. Carrier modulation, 3. Manchester encoding, 4. NRZ encoding | 3. Manchester encoding | In the Manchester encoding , a logic 0 is indicated by a 0 to 1 transition at the centre of the bit and a logic 1 is indicated by a 1 to 0 transition at the centre of the bit. Note that signal transitions do not always occur at the ‘bit boundaries’ (the division between one bit and another), but that there is always a transition at the centre of each bit. | Computer-Networks | Ethernet | |
| Which of the following comment about peephole optimization is true? | 1. It is applied to a small part of the code and applied repeatedly, 2. It can be used to optimize intermediate code, 3. It can be applied to a portion of the code that is not contiguous, 4. It is applied in the symbol table to optimize the memory requirements. | 1. It is applied to a small part of the code and applied repeatedly | → Peephole optimization is a kind of optimization performed over a very small set of instructions in a segment of generated code. The set is called a \"peephole\" or a \"window\". It works by recognizing sets of instructions that can be replaced by shorter or faster sets of instructions. Replacement Rules: 1. Null sequences – Delete useless operations. 2. Combine operations – Replace several operations with one equivalent. 3. Algebraic laws – Use algebraic laws to simplify or reorder instructions. 4. Special case instructions – Use instructions designed for special operand cases. 5. Address mode operations – Use address modes to simplify code. |
Compiler-Design | Code-Optimization | https://youtu.be/xWaeftAdkHI |
| A byte addressable computer has a memory capacity of 2m KB( kbytes ) and can perform 2n operations. An instruction involving 3 operands and one operator needs maximum of | 1. 3m bits, 2. 3m + n bits, 3. m + n bits, 4. None of the above | 4. None of the above | Step-1: Memory capacity is 2m KB = 230m Bytes Step-2: Total number of operations 2n Step-3: Every instruction involving 3 operands and 1 operator Step-4: Number of bits needed by instruction is= 3*(m+10)+n =3m+n+30 bits |
Computer-Organization | Memory-Management | https://youtu.be/wqapAUlymug |
| Any set of Boolean operators that is sufficient to represent all Boolean expressions is said to be complete. Which of the following is not complete? | 1. { AND, OR }, 2. { AND, NOT }, 3. { NOT, OR }, 4. { NOR } | 1. { AND, OR } | → NOT, AND and OR gates are basic gates → NAND and NOR gates are universal gates. → With the help of universal gates, we can construct any boolean expressions. These gates are also called functionally complete. → AND+NOT=NAND→ Functionally Complete → OR+NOT=NOR→ Functionally Complete → NOR→ Functionally Complete → AND+OR→ Not functionally complete |
Digital-Logic-Design | Boolean-Algebra | https://youtu.be/5u5UOf4F2Qw |
| Study the following program: //precondition: x>=0 public void demo(int x) { System.out.print(x % 10); if (x % 10 != 0) { demo(x/10); } System.out.print(x%10); } Which of the following is printed as a result of the call demo(1234)? | 1. 1441, 2. 3443, 3. 12344321, 4. 43211234 | 4. 43211234 | demo(1234) ---> First it will print “4” then 4!=10 condition is true again it call demo(123) demo(123)------> It will print “3” then 3!=10 condition is true again it call demo(12) demo(12)------> It will print “2” then 2!=10 condition is true again it call demo(1) demo(1)------> It will print “1” then 1!=10 condition is true again it call demo(0) It will print again 1,2,3 and 4 as there is another Print statement is in each function call. |
Programming | Functions | |
| Consider a singly linked list of the form where F is a pointer to the first element in the linked list and L is the pointer to the last element in the list. The time of which of the following operations depends on the length of the list? |
1. Delete the last element of the list, 2. Delete the first element of the list, 3. Add an element after the last element of the list, 4. Interchange the first two elements of the list | 1. Delete the last element of the list | F and L must point to the first and last elements respectively. Option B: It needs only the operation F=F→ next Option C: It needs only the operations L→ next=new node, L = new node Option D: It needs only the operations T=F, F=F→ next, T→ next =F→ next, F→ next=T → All these operations do not depend on the length of the list. → Indeed in order to delete the last element from the list, we need to first locate the element before the last (which can not be accessed from L). Thus we must parse all the list from the first and till the element just before the last after which we can delete the last element and assign L to the one before. |
Data-Structures | Linked-List | https://youtu.be/r0162sVRO_Y |
| Bit stuffing refers to | 1. inserting a 0 in user stream to differentiate it with a flag, 2. inserting a 0 in flag stream to avoid ambiguity, 3. appending a nipple to the flag sequence, 4. appending a nipple to the use data stream | 1. inserting a 0 in user stream to differentiate it with a flag | → Bit stuffing is most easily described as insertion of a 0 bit after a long run of 1 bits. → In SDLC the transmitted bit sequence \"01111110\" containing six adjacent 1 bits is the Flag byte. → Bit stuffing ensures that this pattern can never occur in normal data, so it can be used as a marker for the beginning and end of frame without any possibility of being confused with normal data. → Bit stuffing is the insertion of non information bits into data. stuffed bits should not be confused with overhead bits. Overhead bits are non-data bits that are necessary for transmission (usually as part of headers, checksums etc). |
Computer-Networks | Ethernet | |
| A particular BNF definition for a “word” is given by the following rules. <word> ::= <letter> | <letter><pairlet> | <letter><pairdig> <pairlet> ::= <letter><letter> | <pairlet><letter><letter> <pairdig> ::= <digit><digit> | <pairdig><digit><digit> <letter> ::= a | b | c | ... | y | | z <digit> ::= 0 | 1 | 2 | ... | 9 Which of the following lexical entries can be derived from < word > ? I. pick II. picks III. c44 |
1. I, II and III, 2. I and II only, 3. l and III only, 4. lI and III only | 4. lI and III only | Step-1: Both and produce only a single character Step-2: Both and produce even number of characters Step-3: produces odd number of characters. Step-4: As per the statements I, II and III. I statement having even number of characters So, a statement I is wrong. Statement II and III are having odd number of characters. |
Compiler-Design | Lexical-Analyzer | https://youtu.be/plMipZKk2tM |
| What is the name of the technique in which the operating system of a computer executes several programs concurrently by switching back and forth between them? | 1. Partitioning, 2. Multi-tasking, 3. Windowing, 4. Paging | 2. Multi-tasking | In a multitasking system, a computer executes several programs simultaneously by switching them back and forth to increase the user interactivity. Processes share the CPU and execute in an interleaving manner. This allows the user to run more than one program at a time. | Operating-Systems | Multiprogramming | |
| If there are five routers and six networks in intranet using link state routing, how many routing tables are there? | 1. 1, 2. 5, 3. 6, 4. 11 | 2. 5 | Routers have routing tables to transmit packets selectively to other networks. These routers apply shortest path algorithms to choose the links on which, a packet is to be forwarded, so that it can reach the destination in covering minimum number of hops. If there are 5 routers, then there should be 5 routing tables as well. |
Computer-Networks | Routing | |
| Avalanche effect in cryptography | 1. Is desirable property of the cryptographic algorithm, 2. Is undesirable property of the cryptographic algorithm, 3. Has no effect on the encryption algorithm, 4. None of the above | 1. Is desirable property of the cryptographic algorithm | → In cryptography, the avalanche effect is the desirable property of cryptographic algorithms, typically block cyphers and cryptographic hash functions, wherein if input is changed slightly (for example, flipping a single bit), the output changes significantly (e.g., half the output bits flip). → In the case of high-quality block cyphers, such a small change in either the key or the plaintext should cause a drastic change in the ciphertext. |
Computer-Networks | Network-Security | https://youtu.be/2YI4fZd-Bdg |
| Virtual memory is | 1. Part of Main Memory only used for swapping, 2. A technique to allow a program, of size more than the size of main memory, to run, 3. Part of secondary storage used in program execution, 4. None of these | 2. A technique to allow a program, of size more than the size of main memory, to run | A computer can address more memory than the amount physically installed on the system. This extra memory is actually called virtual memory and it is a section of a hard disk that\'s set up to emulate the computer\'s RAM. The main visible advantage of this scheme is that programs can be larger than physical memory. Virtual memory serves two purposes. First, it allows us to extend the use of physical memory by using disk. Second, it allows us to have memory protection, because each virtual address is translated to a physical address |
Operating-Systems | Virtual Memory | |
| In neural network, the network capacity is defined as | 1. The traffic carry capacity of the network, 2. The total number of nodes in the network, 3. The number of patterns that can be stored and recalled in a network, 4. None of the above | 3. The number of patterns that can be stored and recalled in a network | In neural network, the network capacity is defined as the number of patterns that can be stored and recalled in a network | Artificial-intelligence | Neural-Networks | https://youtu.be/PvTOlbxpcrY |
| Cloaking is a search engine optimization (SEO) technique. During cloaking | 1. Content presented to search engine spider is different from that presented to the user’s browser, 2. Content present to search engine spider and browser is the same, 3. Contents of the user’s requested website are changed, 4. None of the above | 1. Content presented to search engine spider is different from that presented to the user’s browser | → Cloaking takes a user to other sites than he or she expects by disguising those sites\' true content. → During cloaking, the search engine spider and the browser are presented with different content for the same Web page. → HTTP header information or IP addresses assist in sending the wrong Web pages. → Searchers will then access websites that contain information they simply were not seeking, including pornographic sites. → Website directories also offer up their share of cloaking techniques. |
Latest-Technologies | Search-Engine-Optimization | https://youtu.be/eWEFm01CDmY |
| The level of aggregation of information required for operational control is | 1. Detailed, 2. Aggregate, 3. Qualitative, 4. None of the above | 1. Detailed | 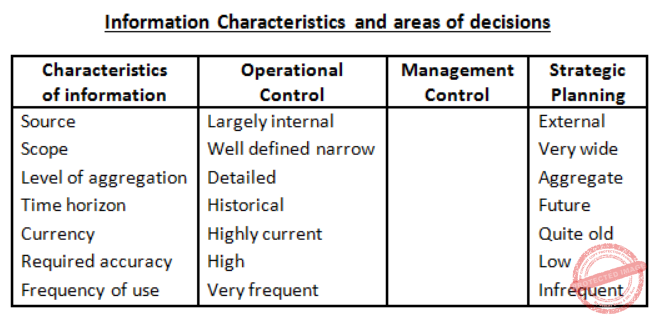 |
Algorithms | Aggregation | |
| 0.75 decimal system is equivalent to ____ in octal system | 1. 0.60, 2. 0.52, 3. 0.54, 4. 0.50 | 1. 0.60 | 0.75 = (0.110)2 = (0.6)8 Option (A) is correct. |
Digital-Logic-Design | Number-Systems | |
| What is one advantage of setting up a DMZ(Demilitarized Zone) with two firewalls? | 1. You can control where traffic goes in the three networks, 2. You can do stateful packet filtering, 3. You can do load balancing, 4. Improve network performance | 1. You can control where traffic goes in the three networks | → The most secure approach is to use two firewalls to create a DMZ. 1. The first firewall (also called the \"front-end\" or \"perimeter\" firewall) must be configured to allow traffic destined to the DMZ only. 2. The second firewall (also called \"back-end\" or \"internal\" firewall) only allows traffic from the DMZ to the internal network. This setup is considered more secure since two devices would need to be compromised. There is even more protection if the two firewalls are provided by two different vendors because it makes it less likely that both devices suffer from the same security vulnerabilities. |
Computer-Networks | Network-Security | https://youtu.be/ba7pyNU2uWM |
| In an SR latch made by cross-coupling two NAND gates, if both S and R inputs are set to 0, then it will result in | 1. Q = 0, Q’ = 1, 2. Q = 1, Q’ = 0, 3. Q = 1, Q’ = 1, 4. Indeterminate states | 4. Indeterminate states | 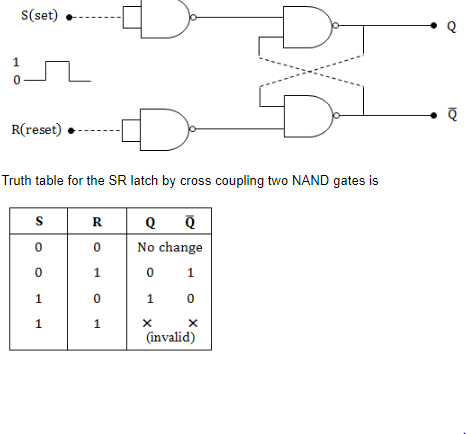 |
Digital-Logic-Design | Sequential-Circuits | |
| Which one of the following algorithm is not used in asymmetric key cryptography? | 1. RSA Algorithm, 2. Diffie-Hellman Algorithm, 3. Electronic Code Book Algorithm, 4. None of the above | 3. Electronic Code Book Algorithm | 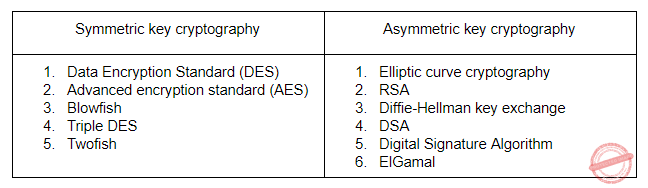 |
Computer-Networks | Network-Security | https://youtu.be/c0Q0ZBjR1HA |
| Identify the correct translation into logical notation of the following assertion. Some boys in the class are taller than all the girls Note: taller (x, y) is true if x is taller than y. | 1. (∃x)(boy(x) → (∀y)(girl(y) ∧ taller(x, y))), 2. (∃x)(boy(x) ∧ (∀y)(girl(y) ∧ taller(x, y))), 3. (∃x)(boy(x) → (∀y)(girl(y) → taller(x, y))), 4. (∃x)(boy(x) ∧ (∀y)(girl(y) → taller(x, y))) | 4. (∃x)(boy(x) ∧ (∀y)(girl(y) → taller(x, y))) | Don\'t confuse with \'∧\' and \'→\' \'∧\' → predicts statements are always true, no matter the value of x. \'→\' → predicts there is no need of left predicate to be true always, but whenever it becomes true, then right predicate must be true. Option D: There exists a some boys who are taller than of all girls y. |
Engineering-Mathematics | Propositional-Logic | |
Consider the following table in a relational database 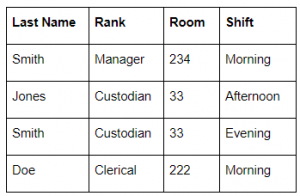 |
1. {Last Name}, 2. {Room}, 3. {Shift}, 4. {Room, Shift} | 4. {Room, Shift} | → Candidate means uniquely identified key. → In the above table, Room having duplicate values. So, we can’t say room is candidate key → The last name also having duplicates. So, we can’t say the last name is candidate key. → Shift also having duplicate keys, so we can’t say shift also a candidate key. → Combining Room and Shift we can say that candidate key. |
Database-Management-System | Relational-databases | https://youtu.be/QAT7KyF-KhE |
| Ring counter is analogous to | 1. Toggle Switch, 2. Latch, 3. Stepping Switch, 4. S-R flip flop | 3. Stepping Switch | → A ring counter is a type of counter composed of flip-flops connected into a shift register, with the output of the last flip-flop fed to the input of the first, making a \"circular\" or \"ring\" structure. There are two types of ring counters: 1. A straight ring counter, also known as a one-hot counter, connects the output of the last shift register to the first shift register input and circulates a single one (or zero) bit around the ring. 2. A twisted ring counter, also called switch-tail ring counter, walking ring counter, Johnson counter, or Möbius counter, connects the complement of the output of the last shift register to the input of the first register and circulates a stream of ones followed by zeros around the ring. Note: Ring counter is analogous to Stepping Switch |
Digital-Logic-Design | Sequential-Circuits | |
| Digital-Logic-Design | 1. 0.1 and 5V, 2. 0.6 and 3.5 V, 3. 0.9 and 1.75 V, 4. -1.75 and 0.9 V | 2. 0.6 and 3.5 V | → TTL high signal would be 5.00 volts exactly, and a TTL low signal 0.00 volts exactly. → However, real TTL gate circuits cannot output such perfect voltage levels, and are designed to accept “high” and “low” signals deviating substantially from these ideal values. |
Digital-Logic-Design | TTL | |
| Consider a computer system that stores a floating-point numbers with 16-bit mantissa and an 8-bit exponent, each in two’s complement. The smallest and largest positive values which can be stored are | 1. 1 × 10-128 and 215× 1015 , 2. 1 × 10-256 and 215× 10255, 3. 1 × 10-128 and 215× 10127, 4. 1 × 10-128and 215– 1 × 10127 | 4. 1 × 10-128and 215– 1 × 10127 | 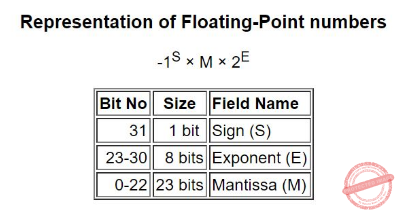 According to question 16 bit mantissa and 8 bit Exponent. Since the mantissa is always 1.xxxxxxxxx in the normalised form, no need to represent the leading 1. Single Precision: mantissa ===> 1 bit + 15 bits The largest mantissa value value is 215-1 (one bit meant for sign) The largest exponent value is 27-1=127 The smallest mantissa value is 0000 0000 0000 0000(one bit is always 1) =1 The Smallest (largest negative) exponent value is 1111 1111 (which is 2’s complement form) 2-8=-128 |
Digital-Logic-Design | Number-Systems | |
| In comparison with static RAM memory, the dynamic RAM memory has | 1. lower bit density and higher power consumption, 2. higher bit density and higher power consumption, 3. lower bit density and lower power consumption, 4. higher bit density and lower power consumption | 2. higher bit density and higher power consumption | DRAM (Dynamic Random Access Memory) → DRAM stands for Dynamic Random Access Memory. It is used in most of the computers. It is the least expensive kind of RAM. It requires an electric current to maintain its electrical state. The electrical charge of DRAM decreases with time that may result in loss of DATA. → DRAM is recharged or refreshed again and again to maintain its data. The processor cannot access the data of DRAM when it is being refreshed. That is why it is slow. SRAM (Static Random Access Memory) → SRAM stands for Static Random Access Memory. It can store data without any need of frequent recharging. CPU does not need to wait to access data from SRAM during processing. That is why it is faster than DRAM. It utilizes less power than DRAM. → SRAM is more expensive as compared to DRAM. It is normally used to build a very fast memory known as cache memory |
Digital-Logic-Design | RAM | |
| A data driven machine is one that executes an instruction if the needed data is available. The physical ordering of the code listing does not dictate the course of execution. Consider the following pseudo-code: (A) Multiply E by 0.5 to get F (B) Add A and B to get E (C) Add B with 0.5 to get D (D) Add E and F to get G (E) Add A with 10.5 to get C Assume A, B, C are already assigned values and the desired output is G. Which of the following sequence of execution is valid? |
1. B, C, D, A, E, 2. C, B, E, A, D, 3. A, B, C, D, E, 4. E, D, C, B, A | 2. C, B, E, A, D | Given data, A) F= E * 0.5 B) E=A+B C) D=B+0.5 D) G=E+F E) C=A+10.5 It is given A, B, C are already assigned values, so we can perform any of B or C or E first but not A. so option(c) is incorrect . Option(a) is incorrect because we can\'t perform operation D before operation A. Option(d) is incorrect because we can\'t perform operation D before operation A. Hence option(b) is only correct. |
Computer-Organization | Machine-Instructions | https://youtu.be/jwHd7V1GvGs |
Assume A and B are non zero positive integers. The following code segment  |
1. Computes the LCM of two numbers, 2. Divides the larger number by the smaller number, 3. Computes the GCD of two numbers, 4. Finds the smaller of two numbers | 3. Computes the GCD of two numbers | → The above iterative code is computes the GCD of two numbers using euclidean algorithm. → The procedure is to subtract smaller number from larger. So that we can reduce larger number then doesn’t change the value of GCD. → if we performing number of iterations based on condition the larger of two numbers will end up with GCD. |
Programming-for-Output-Problems | Control Flow | https://youtu.be/kp5ruC6e18I |
| The Hexadecimal equivalent of 01111100110111100011 is | 1. CD73E, 2. ABD3F, 3. 7CDE3, 4. FA4CD | 3. 7CDE3 | Binary number = 0111 1100 1101 1110 0011 7 C D E 3 (7CDE3)16 |
Digital-Logic-Design | Number-Systems | |
| Disk requests are received by a disk drive for cylinder 5, 25, 18, 3, 39, 8 and 35 in that order. A seek takes 5 msec per cylinder moved. How much seek time is needed to serve these requests for a Shortest Seek First (SSF) algorithm? Assume that the arm is at cylinder 20 when the last of these requests is made with none of the requests yet served | 1. 125 msec, 2. 295 msec, 3. 575 msec, 4. 750 msec | 2. 295 msec | The arm is at cylinder 20, so the service order = 18, 25, 35, 39, 8, 5, 3. Seek time = (20−18) + (25−18) + (35−25) + (39−35) + (39−8) + (8−5) + (5−3) = 2 + 7 + 10 + 4 + 31 + 3 + 2 = 59 Total seek time = 59 * 5 = 29 |
Operating-Systems | Disk-Scheduling | |
| Consider a system having ‘m’ resources of the same type. The resources are shared by 3 processes A, B, C, which have peak time demands of 3, 4, 6 respectively. The minimum value of ‘m’ that ensures that deadlock will never occur is | 1. 11, 2. 12, 3. 13, 4. 14 | 1. 11 | Minimum resources required to avoid deadlock = (m1 – 1) + (m2 – 1) +..+ (my – 1) + 1 where m = resource required by process y = number of processes so, Number of resources that ensures that deadlock will never occur is = (3-1) + (4-1) + (6-1) + 1 = 11 Option (A) is correct. |
Operating-Systems | Deadlock | |
| A task in a blocked state | 1. is executable, 2. is running, 3. must still be placed in the run queues, 4. is waiting for some temporarily unavailable resources | 4. is waiting for some temporarily unavailable resources | Waiting or Blocked state is when a process has requested some input/output and is waiting for the resource. | Operating-Systems | Peocess-state-transition-diagram | |
| Semaphores | 1. synchronize critical resources to prevent deadlock, 2. synchronize critical resources to prevent contention, 3. are used to do I/O, 4. are used for memory management | 2. synchronize critical resources to prevent contention | Semaphore is a variable and is used to solve critical section problem and to achieve process synchronization in the multi processing environment. | Operating-Systems | Process-Synchronization | |
| On a system using non-preemptive scheduling, processes with expected run times of 5, 18, 9 and 12 are in the ready queue. In what order should they be run to minimize wait time? | 1. 5, 12, 9, 18, 2. 5, 9, 12, 18, 3. 12, 18, 9, 5, 4. 9, 12, 18, 5 | 2. 5, 9, 12, 18 | The processes should execute in SJF manner to get the lowest waiting time. So, the order should be 5, 9, 12, 18. | Operating-Systems | CPU-Scheduling | |
| The number of page frames that must be allocated to a running process in a virtual memory environment is determined by | 1. the instruction set architecture, 2. page size, 3. number of processes in memory, 4. physical memory size | 1. the instruction set architecture | There are two important tasks in virtual memory management: a page-replacement strategy and a frame-allocation strategy. Frame allocation strategy says gives the idea of minimum number of frames which should be allocated. The absolute minimum number of frames that a process must be allocated is dependent on system architecture, and corresponds to the number of pages that could be touched by a single (machine) instruction.So, it is instruction set architecture | Operating-Systems | Virtual Memory | |
| Consider a small 2-way set-associative cache memory, consisting of four blocks. For choosing the block to be replaced, use the least recently (LRU) scheme. The number of cache misses for the following sequence of block addresses is 8, 12, 0, 12, 8 | 1. 2, 2. 3, 3. 4, 4. 5 | 3. 4 | It is given that the cache is 2-way set associative, so there will be 2 blocks within each cache set. It is also given that there are 4 blocks in the cache. So, no of sets = no. of blocks in the cache / no. of blocks in a set = 4 / 2 = 2 In set associative cache mapping, the given main memory block is mapped to a cache set which is obtained by: (block number) mod (number of sets). Here there are 2 sets and all the given main memory blocks are even numbers so all of them are mapped to set-0, as 8 mod 2 = 0, 12 mod 2 = 0 and 0 mod 2 = 0. The given block pattern 8, 12, 0, 12, 8 are mapped to the cache blocks as shown in the image attached with this email. From this the first access of 8, 12, 0 are all 3 misses. And the second access of 12 is a hit, but the second access of 8 is a miss. So total we have 4 misses. 
|
Operating-Systems | Page-Replacement-algorithm | |
| Which commands are used to control access over objects in relational database? | 1. CASCADE & MVD, 2. GRANT & REVOKE, 3. QUE & QUIST, 4. None of these | 2. GRANT & REVOKE | DCL(Data Control Language) includes commands such as GRANT and REVOKE which mainly deals with the rights, permissions and other controls of the database system. Examples of DCL commands: GRANT-gives user’s access privileges to database. REVOKE-withdraw user’s access privileges given by using the GRANT command. |
Database-Management-System | Relational-databases | |
| Which of the following is aggregate function in SQL? | 1. Avg, 2. Select, 3. Ordered by, 4. distinct | 1. Avg | Avg is one of the aggregate functions. It returns average value after calculating from values in a numeric column. Syntax: SELECT AVG(column_name) FROM table_name; |
Database-Management-System | SQL | |
| One approach to handling fuzzy logic data might be to design a computer using ternary (base-3) logic so that data could be stored as “true,” “false,” and “unknown.” If each ternary logic element is called a flit, how many blits are required to represent at least 256 different values? | 1. 4, 2. 5, 3. 6, 4. 7 | 3. 6 | In binary representation, to represent 256 different values, you need log_2 (256) = 8 bits. Similarly in ternary representation, you would require log_3 (256) which is 5.something. Now rounding off to the upper integer (since number of bits is an integer) and we get 6 | Digital-Logic-Design | Number-Systems | |
| A view of database that appears to an application program is known as | 1. Schema, 2. Subschema, 3. Virtual table, 4. None of these | 3. Virtual table | A view of database that appears to an application program is known as Virtual table | Database-Management-System | Schema | |
| Armstrong’s inference rule does not determine | 1. Reflexivity, 2. Augmentation, 3. Transitivity, 4. Mutual dependency | 4. Mutual dependency | Armstrong inference rules refers to a set of inference rules used to infer all the functional dependencies on a relational database. It consists of the following axioms: Axiom of Reflexivity: This axiom states: if Y is a subset of X, then X determines Y Axiom of Augmentation: The axiom of augmentation, also known as a partial dependency, states if X determines Y, then XZ determines YZ, for any Z Axiom of Transitivity: The axiom of transitivity says if X determines Y, and Y determines Z, then X must also determine Z. |
Database-Management-System | Armstrong’s-inference-rule | |
| Which operation is used to extract specific columns from a table? | 1. Project, 2. Join, 3. Extract, 4. Substitute | 1. Project | Projection (π) Projection is used to project required column data from a relation. By Default projection removes duplicate data. Example : R(A B C) ---------- 1 2 4 2 2 3 3 2 3 4 3 4 π (BC) B C ----- 2 4 2 3 3 4 |
Database-Management-System | Relational-Algebra | |
| In the Big-Endian system, the computer stores | 1. MSB of data in the lowest memory address of data unit, 2. LSB of data in the lowest memory address of data unit, 3. MSB of data in the highest memory address of data unit, 4. LSB of data in the highest memory address of data uni | 1. MSB of data in the lowest memory address of data unit | Big-endian is an order in which the “big end” i.e. the most significant value in the sequence is stored first at the lowest storage address. | Computer-Organization | MSB-LSB | |
| BCNF is not used for cases where a relation has | 1. Two (or more) candidate keys, 2. Two candidate keys and composite, 3. The candidate key overlap, 4. Two mutually exclusive foreign keys | 4. Two mutually exclusive foreign keys | A relation is in Boyce-Codd normal form if all attributes which are determinants are also candidate keys. Transformation into Boyce-Codd normal form deals with the problem of overlapping keys. |
Database-Management-System | Normalization | |
| Selection sort algorithm design technique is an example of | 1. Greedy method, 2. Divide-and-conquer, 3. Dynamic Programming, 4. Backtracking | 1. Greedy method | The selection sort algorithm sorts an array by repeatedly finding the minimum element (considering ascending order) from unsorted part and putting it at the beginning. The algorithm maintains two subarrays in a given array. 1) The subarray which is already sorted. 2) Remaining subarray which is unsorted. In every iteration of selection sort, the minimum element (considering ascending order) from the unsorted subarray is picked and moved to the sorted subarray. Clearly, it is a greedy approach to sort the array. |
Algorithms | Sorting | |
| Which of the following RAID level provides the highest Data Transfer Rate (Read/Write) | 1. RAID 1, 2. RAID 3, 3. RAID 4, 4. RAID 5 | 1. RAID 1 | Disk mirroring, also known as RAID 1, is the replication of data to two or more disks. Disk mirroring is a good choice for applications that require high performance and high availability, such as transactional applications, email and operating systems. | Operating-Systems | RAID | |
| Which of the following programming language(s) provides garbage collection automatically | 1. Lisp, 2. C++, 3. Fortran, 4. C | 1. Lisp | Lisp is the first high-level programming language to introduce automatic garbage collection to simplify the concept of manual garbage collection. Rest of these languages- C, C++, FORTRAN do not perform automatic garbage collection but are capable of doing it manually. | Programming | Garbage-Collection | |
| The average case and worst case complexities for Merge sort algorithm are | 1. O(n2), O(n2), 2. O(n2), O(nlog2n), 3. O(n log2n), O(n2), 4. O(n log2n), O(n log2n) | 4. O(n log2n), O(n log2n) | The best case, average case and worst case complexities for Merge sort algorithm are O( nlog2n ). | Algorithms | Sorting | |
| The time taken by binary search algorithm to search a key in a sorted array of n elements is | 1. O ( log2n ), 2. O ( n ), 3. O ( n log2n ), 4. O ( n2 ) | 1. O ( log2n ) | Search a sorted array by repeatedly dividing the search interval in half. Begin with an interval covering the whole array. If the value of the search key is less than the item in the middle of the interval, narrow the interval to the lower half. Otherwise narrow it to the upper half. Repeatedly check until the value is found or the interval is empty. It takes a maximum of log(n) searches to search an element from the sorted array. | Algorithms | Searching | |
| Which of the following is correct with respect to Two phase commit protocol? | 1. Ensures serializability, 2. Prevents Deadlock, 3. Detects Deadlock, 4. Recover from Deadlock | 1. Ensures serializability | The two phase commit protocol is a distributed algorithm which lets all sites in a distributed system agree to commit or rollback a transaction based upon consensus of all participating sites.If any database server is unable to commit its portion of the transaction, all database servers participating in the transaction must be prevented from committing their work. It ensures serializability but does not ensures freedom from deadlock. |
Database-Management-System | Transactions | |
| The Fibonacci sequence is the sequence of integers | 1. 1, 3, 5, 7, 9, 11, 13, 2. 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 3. 0, 1, 3, 4, 7, 11, 18, 29, 47, 4. 0, 1, 3, 7, 15 | 2. 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55 | In mathematical terms, the sequence Fn of Fibonacci numbers is defined by the recurrence relation Fn = Fn-1 + Fn-2 with seed values F0 = 0 and F1 = 1. The Fibonacci numbers are the numbers in the following integer sequence. 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144.. |
Algorithms | Fibbonacci-Series | |
| Let X be the adjacency matrix of a graph G with no self loops. The entries along the principal diagonal of X are | 1. all zeros, 2. all ones, 3. both zeros and ones, 4. different | 1. all zeros | In an adjacency matrix of a graph G the entries along the principal diagonal are reflexive, i.e. elements showing connectivity with themselves. Since the GrapH G has no self loops so all these entries should be 0. | Data-Structures | Graph-Theory | |
| Question | ALL_ANSWERS | CORRECT_ANSWER | Explanation | subject | Topic | v_e |