Operating-Systems
Question 1 |
function OWNRESOURCE(Resource R)
Acquire lock L // a global lock
if R is available then
Acquire R
Release lock L
else
if R is owned by another process P then
Terminate P, after releasing all resources owned by P
Acquire R
Restart P
Release lock L
end if
end if
end function
Which of the following choice(s) about the above scheme is/are correct?
The scheme ensures that deadlocks will not occur. | |
The scheme may lead to live-lock. | |
The scheme violates the mutual exclusive property. | |
The scheme may lead to starvation. |
(1) True,
The scheme ensures deadlock free operation, as there is no hold-and-wait condition possible.
(2) True,
The scheme may lead to priority inversion problems, and hence livelock is possible.
(3) False,
Mutual exclusion is satisfied as only one process can acquire and release locks at a time.
(4) True,
The scheme may lead to starvation. For example, the priority process can get scheduled repeatedly and keeps on killing the lower priority processes. Hence, a low priority process may strave.
Question 2 |
int x=0; // global
Lock L1; // global
main() {
create a thread to execute foo(); // Thread T1
create a thread to execute foo(); // Thread T2
wait for the two threads to finish execution;
print (x); }
foo() {
int y=0;
Acquire L1;
x = x + 1;
y = y + 1;
Release L1;
print (y);}
Which of the following statement(s) is/are correct?
At least one of P1 and P2 will print the value of x as 4. | |
Both T1 and t2, in both the processes, will print the value of y as 1. | |
Both P1 and P2 will print the value of x as2. | |
At least one of the threads will print the value of y as 2. |
- True,
Execution order : P1->T1->T2; P2->T1->T2; P1-print(x),P2-print(x) | output is 4,4
- True,
y=y+1 can be treated as a critical section, and it is well synchronized by Acquire L1 and release L1.
- False, need not be true always.
- False,
Threads maintain their own copy of stack,and local variables (y) are stored on the stack.
Question 3 |

The page size is 4KB (1KB = 210bytes) and page table entry size at every level is 8 bytes. A process P is currently using 2GB (1GB = 230bytes) virtual memory which is mapped to 2GB of physical memory. The minimum amount of memory required for the page table of P across all levels is ________ KB.
8.01 |
A system can support upto 2^39 bytes of Virtual address space. Three level paging is used with Level 1 (9 bits), Level 2 (9 bits) and Level 3 (9 bits) and page offset of 12 bits.
Page table entry is 8 bytes at every level. Therefore,
Level 3 page table size : 2^9 * 8bytes = 2^12 bytes. (Fits in one frame)
Level 2 page table size : 2^9 * 8bytes = 2^12 bytes. (Fits in one frame)
Level 1 page table size : 2^9 * 8bytes = 2^12 bytes. (Fits in one frame).
However, the process P has a virtual address space of 2^31 bytes. Thus, it is clear that the last level page table does not occupy the frame completely. Let x be the number of bits indexed in the last level.
Therefore, we can have (2^x) * (2^9) * (2^9)* (2^12) = 2^31 => x =1. Thus, the minimum size of page table for process P would be,
Page table size at level-1 + Page table size at level-2 + Page table size at level-3 =
2^1 * 8bytes + 2^9 * 8bytes + 2^9 * 8bytes = (1026)*8 bytes = 8.01 KB
Question 4 |
Implementing preemptive scheduling needed hardware support. | |
Turnaround time includes waiting time | |
Round-robin policy can be used even when the CPU time required by each of the processes is not known apriori. | |
The goal is to only maximize CPU utilization and minimize throughput. |
- True. Preemptive scheduling needs hardware support such as a timer
- True. Turnaround time = Burst time + Waiting time
- True, RR assigns qunatume to each process equally. Hence, it is not required to know burst size apriori
- False. Maximize CPU utilization and throughput, and minimize waiting time etc.
Question 5 |
Which of the following statements is true?
ROM is a Read/Write memory | |
PC points to the last instruction that was executed | |
Stack works on the principle of LIFO | |
All instructions affect the flags |
Question 6 |
In a paged segmented scheme of memory management, the segment table itself must have a page table because
the segment table is often too large to fit in one page | |
each segment is spread over a number of pages | |
segment tables point to page table and not to the physical locations of the segment | |
the processor’s description base register points to a page table | |
Both A and B |
Segment paging is different from paged segmentation.
Question 7 |
Which of the following page replacement algorithms suffers from Belady’s anamoly?
Optimal replacement | |
LRU | |
FIFO | |
Both (A) and (C) |
Question 8 |
Which scheduling policy is most suitable for a time shared operating system?
Shortest Job First | |
Round Robin | |
First Come First Serve | |
Elevator |
Question 9 |
The sequence …………… is an optimal non-preemptive scheduling sequence for the following jobs which leaves the CPU idle for …………… unit(s) of time.
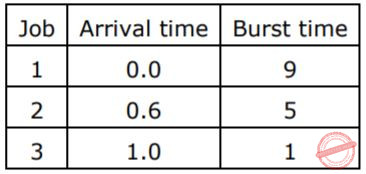
{3,2,1),1 | |
(2,1,3},0 | |
{3,2,1),0 | |
{1,2,3},5 |
So, (B) and (C) will be eliminated.
Now in (A) and (D):
For r(A),

So, idle time is between 0 to 1 which in case of option (A).
For option(D),
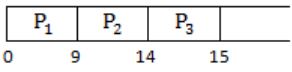
We can see there is no idle time at all, but in option given idle time is 5, which is not matching with our chart. So option (D) is eliminated.
Therefore, the correct sequence is option (A).
Question 10 |
The address sequence generated by tracing a particular program executing in a pure demand paging system with 100 records per page with 1 free main memory frame is recorded as follows. What is the number of page faults?
0100, 0200, 0430, 0499, 0510, 0530, 0560, 0120, 0220, 0240, 0260, 0320, 0370
13 | |
8 | |
7 | |
10 |
01, 02, 04, 04, 05, 05, 05, 01, 02, 02, 02, 03, 03.
Clearly 7 page faults.
Question 11 |
In a virtual memory system the address space specified by the address lines of the CUP must be __________ than the physical memory size and _______ than the secondary storage size.
smaller, smaller | |
smaller, larger | |
larger, smaller | |
larger, larger |
Question 12 |
A computer installation has 1000k of main memory. The jobs arrive and finish in the following sequences.
Job 1 requiring 200k arrives Job 2 requiring 350k arrives Job 3 requiring 300k arrives Job 1 finishes Job 4 requiring 120k arrives Job 5 requiring 150k arrives Job 6 requiring 80k arrives
(a) Draw the memory allocation table using Best Fit and First fit algorithms.
(b) Which algorithm performs better for this sequence?
Theory Explanation. |
Question 13 |
Consider the following program segment for concurrent processing using semaphore operators P and V for synchronization. Draw the precedence graph for the statements S1 to S9.
var
a, b, c, d, e, f, g, h, i, j, k : semaphore;
begin
cobegin
begin S1; V(a); V(b) end;
begin P(a); S2; V(c); V(d) end;
begin P(c); S4; V(c) end;
begin P(d); S5; V(f) end;
begin P(e); P(f); S7; V(k) end;
begin P(b); S3;V(g);V(h) end;
begin P(g); S6; V(i) end;
begin P(h); P(i); S8; V(j) end;
begin P(j); P(j); P(k); S9 end;
coend
end; Theory Explanation. |
Question 14 |
The head of a moving head disk with 100 tracks numbered 0 to 99 is currently serving a request at tract 55. If the queue of requests kept in FIFO order is
10, 70, 75, 23, 65
Which of the two disk scheduling algorithms FCFS (First Come First Served) and SSTF (Shortest Seek Time First) will require less head movement? Find the head movement for each of the algorithms.
Theory Explanation. |
Question 15 |
Consider allocation of memory to a new process. Assume that none of the existing holes in the memory will exactly fit the process’s memory requirement. Hence, a new hole of smaller size will be created if allocation is made in any of the existing holes. Which one of the following statements is TRUE?
The hole created by worst fit is always larger than the hole created by first fit. | |
The hole created by best fit is never larger than the hole created by first fit.
| |
The hole created by first fit is always larger than the hole created by next fit. | |
The hole created by next fit is never larger than the hole created by best fit. |
Question 16 |
Consider the following statements about process state transitions for a system using preemptive scheduling.
- I. A running process can move to ready state.
II. A ready process can move to running state.
III. A blocked process can move to running state.
IV. A blocked process can move to ready state.
Which of the above statements are TRUE?
II and III only | |
I, II and III only
| |
I, II, III and IV
| |
I, II and IV only
|

Question 17 |
Consider the following set of processes, assumed to have arrived at time 0. Consider the CPU scheduling algorithms Shortest Job First (SJF) and Round Robin (RR). For RR, assume that the processes are scheduled in the order P1,P2,P3,P4.
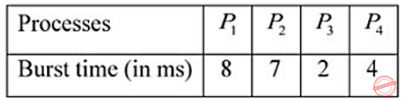
If the time quantum for RR is 4 ms, then the absolute value of the difference between the average turnaround times (in ms) of SJF and RR (round off to 2 decimal places) is _____.
5.25 |

Turn Around Time = (21 – 0) + (13 – 0) + (2 – 0) + (6 – 0), Average = 42/4 = 10.50

Turn Around Time (TAT) = (18 – 0) + (21 – 0) + (10 – 0) + (14 – 0), Average = 63/4 = 15.75
Absolute difference = |10.50-15.75| = 5.25
Question 18 |
Each of a set of n processes executes the following code using two semaphores a and b initialized to 1 and 0, respectively. Assume that count is a shared variable initialized to 0 and not used in CODE SECTION P.
wait (a); count = count+1; if (count==n) signal (b); signal (a); wait (b); signal (b);
What does the code achieve?
It ensures that all processes execute CODE SECTION P mutually exclusively. | |
It ensures that at most two processes are in CODE SECTION Q at any time. | |
It ensures that no process executes CODE SECTION Q before every process has finished CODE SECTION P.
| |
It ensures that at most n-1 processes are in CODE SECTION P at any time.
|
Question 19 |
Consider the following five disk access requests of the form (request id, cylinder number) that are present in the disk scheduler queue at a given time.
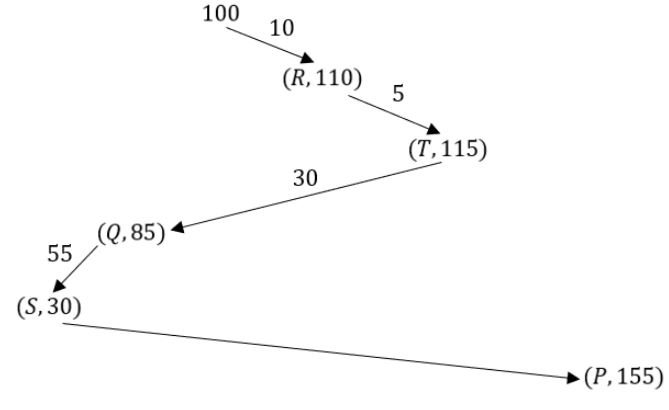
(P, 155), (Q, 85), (R, 110), (S, 30), (T, 115)
Assume the head is positioned at cylinder 100. The scheduler follows Shortest Seek Time First scheduling to service the requests.
Which one of the following statements is FALSE?
The head reverses its direction of movement between servicing of Q and P. | |
T is serviced before P. | |
R is serviced before P. | |
Q is serviced after S, but before T.
|
Question 20 |
Consider a paging system that uses a 1-level page table residing in main memory and a TLB for address translation. Each main memory access takes 100 ns and TLB lookup takes 20 ns. Each page transfer to/from the disk takes 5000 ns. Assume that the TLB hit ratio is 95%, page fault rate is 10%. Assume that for 20% of the total page faults, a dirty page has to be written back to disk before the required page is read in from disk. TLB update time is negligible. The average memory access time in ns (round off to 1 decimal places) is ______.
154.5 ns |
T=20ns
D=5000ns
h=0.95
p=0.1, 1-p=0.9
d=0.2, 1-d=0.8
EMAT = h×(T+M)+(1-h)[(1-p)×2M+p[(1-d)[D+M]+d(2D+M)]+T]
= 0.95×(20+100)+(1-0.95)[(1-0.1)×200+(0.1)[(1-0.2)[5000+100]+(0.2)(10000+100)]+20]
= 154.5 ns
Question 21 |
The process state transition diagram in below figure is representative of
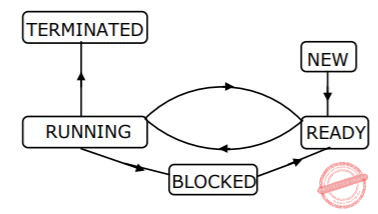
a batch operating system | |
an operating system with a preemptive scheduler | |
an operating system with a non-preemptive scheduler | |
a uni-programmed operating system |
So this is preemptive.
Question 22 |
A critical section is a program segment
which should run in a certain specified amount of time | |
which avoids deadlocks | |
where shared resources are accessed | |
which must be enclosed by a pair of semaphore operations, P and V |
Question 23 |
Which of the following is an example of spooled device?
A line printer used to print the output of a number of jobs. | |
A terminal used to enter input data to a running program. | |
A secondary storage device in a virtual memory system. | |
A graphic display device. |
Question 24 |
The correct matching for the following pairs is
A. Activation record 1. Linking loader
B. Location counter 2. Garbage collection
C. Reference counts 3. Subroutine call
D. Address relocation 4. Assembler A – 3 B – 4 C – 1 D – 2 | |
A – 4 B – 3 C – 1 D – 2 | |
A – 4 B – 3 C – 2 D – 1 | |
A – 3 B – 4 C – 2 D – 1 |
An assembler uses location counter value to give address to each instruction which is needed for relative addressing as well as for jump labels.
Reference count is used by garbage collector to clear the memory whose reference count be comes 0.
Linker loader is a loader which can load several compiled codes and link them together into a single executable. Thus it needs to do relocation of the object codes.
Question 25 |
A 1000 Kbyte memory is managed using variable partitions but to compaction. It currently has two partitions of sizes 200 Kbytes and 260 Kbytes respectively. The smallest allocation request in Kbytes that could be denied is for
151 | |
181 | |
231 | |
541 |
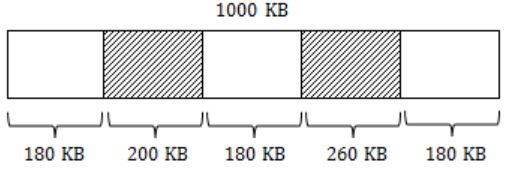
So, smallest allocation request which can be denied is 181 KB.
Question 26 |
A solution to the Dining Philosophers Problem which avoids deadlock is
ensure that all philosophers pick up the left fork before the right fork | |
ensure that all philosophers pick up the right fork before the left fork | |
ensure that one particular philosopher picks up the left fork before the right fork, and that all other philosophers pick up the right fork before the left fork | |
None of the above |
To avoid this, atleast one philosopher should choose its first chopstick in different way so that circular loop is not formed.
Question 27 |
Four jobs to be executed on a single processor system arrive at time 0+ in the order A, B, C, D. their burst CPU time requirements are 4, 1, 8, 1 time units respectively. The completion time of A under round robin scheduling with time slice of one time unit is
10 | |
4 | |
8 | |
9 |

∴ Completion time of A is 9 unit.
Question 28 |
A demand paged virtual memory system uses 16 bit virtual address, page size of 256 bytes, and has 1 Kbyte of main memory. LRU page replacement is implemented using a list whose current status (page number in decimal) is

For each hexadecimal address in the address sequence given below
00FF, 010D, 10FF, 11B0
indicate
(i) the new status of the list
(ii) page faults, if any, and
(iii) page replacements, if any
Theory Explanation. |
Question 29 |
The concurrent programming constructs fork and join are as below:
fork
N = 2 M = 2 fork L3 fork L4 S1 L1:join N S3 L2:join M S5 L3:S2 goto L1 L4:S4 goto L2 next:
Theory Explanation. |
Question 30 |
A computer system uses the Banker’s Algorithm to deal with deadlocks. Its current state is shown in the table below, where P0, P1, P2 are processes, and R0, R1, R2 are resources types.
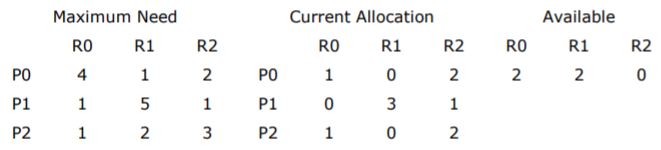
(a) Show that the system can be in this state.
(b) What will the system do on a request by process P0 for one unit of resource type R1?
Theory Explanation. |
Question 31 |
A file system with a one-level directory structure is implemented on a disk with disk block size of 4K bytes. The disk is used as follows:
Disk-block 0: File Allocation Table, consisting of one 8-bit entry per date block,
representing the data block address of the next date block in the file
Disk block 1: Directory, with one 32 bit entry per file:
Disk block 2: Data block 1;
Disk block 3: Data block 2; etc.
(a) What is the maximum possible number of files?
(b) What is the maximum possible file size in blocks?
Theory Explanation. |
Question 32 |
Locality of reference implies that the page reference being made by a process
will always be to the page used in the previous page reference | |
is likely to be to one of the pages used in the last few page references | |
will always be to one of the pages existing in memory | |
will always lead to a page fault |
(1) Temporal locality
(2) Spatial locality
(3) Sequential locality
→ In programs related data are stored in consecutive locations and loops in same locations are used repeatedly.
Question 33 |
The correct matching for the following pairs is
(A) Disk Scheduling (1) Round robin (B) Batch Processing (2) SCAN (C) Time sharing (3) LIFO (D) Interrupt processing (4) FIFO
A – 3 B – 4 C – 2 D – 1 | |
A – 4 B – 3 C – 2 D – 1 | |
A – 2 B – 4 C – 1 D – 3 | |
A – 3 B – 4 C – 3 D – 2 |
Batch processing - FIFO
Time sharing - Round Robin
Interrupt processing - LIFO
Question 34 |
I/O redirection
implies changing the name of a file | |
can be employed to use an existing file as input file for a program | |
implies connection 2 programs through a pipe | |
None of the above
|
Question 35 |
Thrashing
reduces page I/O | |
decreases the degree of multiprogramming | |
implies excessive page I/O | |
improve the system performance |
Question 36 |
Dirty bit for a page in a page table
helps avoid unnecessary writes on a paging device | |
helps maintain LRU information | |
allows only read on a page | |
None of the above |
Question 37 |
An operating system contains 3 user processes each requiring 2 units of resource R. The minimum number of units of r such that no deadlocks will ever arise is
3 | |
5 | |
4 | |
6 |
Question 38 |
Each Process Pi, i = 1.......9 is coded as follows
repeat
P(mutex)
{Critical section}
V(mutex)
forever
The code for P10 is identical except it uses V(mutex) in place of P(mutex). What is the largest number of processes that can be inside the critical section at any moment?
1 | |
2 | |
3 | |
None of the above |
repeat
{
V(mutex)
C.S.
V(mutex)
}
forever
Now, let me say P1 is in CS then P1 is in CS
then P10 comes and executes CS (upon mutex).
Now, P2 comes (down on mutex).
Now P10 moves out of CS (again binary semaphore will be 1).
Now P3 comes (down on mutex).
Now P10 comes (upon mutex).
Now P4 comes (down mutex).
⁞
So, if we take P10 'in' and 'out' of CS recursively, all 10 processes can be in CS at same time using binary semaphore only.
Question 39 |
Consider a process executing on an operating system that uses demand paging. The average time for a memory access in the system is M units if the corresponding memory page is available in memory and D units if the memory access causes a page fault. It has been experimentally measured that the average time taken for a memory access in the process is X units.
Which one of the following is the correct expression for the page fault rate experienced by the process?
(D-M)/(X-M) | |
(X-M)/(D-M) | |
(D-X)/(D-M) | |
(X-M)/(D-X) |
X = (1 - P)M + D × P
X = M ∙ PM + DP
(X - M) = P(D - M)
⇒ P = (X - M) / (D - M)
Question 40 |
Consider a system with 3 processes that share 4 instances of the same resource type. Each process can request a maximum of K instances. Resource instances can be requested and released only one at a time. The largest value of K that will always avoid deadlock is _________.
2 | |
3 | |
4 | |
5 |
No. of resources = 4
Let’s distribute each process one less than maximum demands i.e., (k-1) resources.
So, for three processes, 3(k – 1) resources.
For deadlock avoidance provide an additional resource to any one of the process.
∴ Total resources required to avoid deadlock in any case is 3(k – 1) + 1 = 3k – 2
Now this 3k – 2 should be less than equal to available no. of resources, i.e.,
3k – 2 ≤ 4
k ≤ 2
So maximum value of k = 2
Question 41 |
Consider the following solution to the producer-consumer synchronization problem. The shared buffer size is N. Three semaphores empty, full and mutex are defined with respective initial values of 0, N and 1. Semaphore empty denotes the number of available slots in the buffer, for the consumer to read from. Semaphore full denotes the number of available slots in the buffer, for the producer to write to. The placeholder variables, denoted by P, Q, R and S, in the code below can be assigned either empty or full. The valid semaphore operations are: wait() and signal().
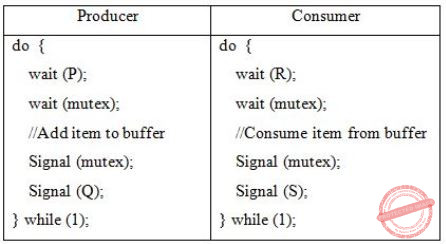
Which one of the following assignments to P, Q, R and S will yield the correct solution?
P: full, Q: full, R: empty, S: empty | |
P: empty, Q: empty, R: full, S: full
| |
P: full, Q: empty, R: empty, S: full | |
P: empty, Q: full, R: full, S: empty |
Initial: mutex = 1
empty = 0
full = N

Question 42 |
Consider a storage disk with 4 platters (numbered as 0, 1, 2 and 3), 200 cylinders (numbered as 0, 1, … , 199), and 256 sectors per track (numbered as 0, 1, … 255). The following 6 disk requests of the form [sector number, cylinder number, platter number] are received by the disk controller at the same time:
- [120, 72, 2], [180, 134, 1], [60, 20, 0], [212, 86, 3], [56, 116, 2], [118, 16, 1]
Currently head is positioned at sector number 100 of cylinder 80, and is moving towards higher cylinder numbers. The average power dissipation in moving the head over 100 cylinders is 20 milliwatts and for reversing the direction of the head movement once is 15 milliwatts. Power dissipation associated with rotational latency and switching of head between different platters is negligible.
The total power consumption in milliwatts to satisfy all of the above disk requests using the Shortest Seek Time First disk scheduling algorithm is ______ .
85 | |
86 | |
87 | |
88 |
→ A storage disk - 4 platters(0, 1, 2 & 3), Cylinder - 200 (0, 1, …, 199) , 256 sector per track.
In the above question the disk requests are given in the form of 〈sector no, cylinder no, platter no〉.
In SSTF (Shortest Seek Time First) Disk Scheduling algorithm, requests having shortest seek time are executed first.
So, the seek time of every request is calculated in advance in queue and then they are scheduled according to their calculated seek time. Head is positioned at 80 and moving towards higher cylinder no.
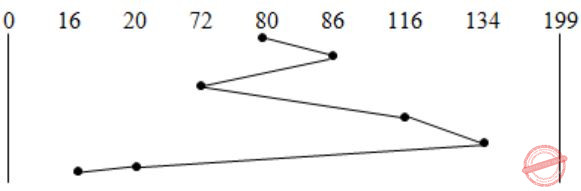
Head Movement in SSTF = (86 – 80) + (86 – 72) + (134 – 72) + (134 – 16) = 200
P1: Power dissipated by 200 movements = 0.2 * 200 = 40 mW
Power dissipated in reversing Head direction once = 15 mW
No. of times Head changes its direction = 3 P2: Power dissipated in reversing Head direction = 3 * 15 = 45 mW
Total power consumption is P1 + P2 = 85 mW
Question 43 |
In a system, there are three types of resources: E, F and G. Four processes P0, P1, P2 and P3 execute concurrently. At the outset, the processes have declared their maximum resource requirements using a matrix named Max as given below. For example, Max[P2, F] is the maximum number of instances of F that P2 would require. The number of instances of the resources allocated to the various processes at any given state is given by a matrix named Allocation.
Consider a state of the system with the Allocation matrix as shown below, and in which 3 instances of E and 3 instances of F are the only resources available.

From the perspective of deadlock avoidance, which one of the following is true?
The system is in safe state. | |
The system is not in safe state, but would be safe if one more instance of E were available. | |
The system is not in safe state, but would be safe if one more instance of F were available.
| |
The system is not in safe state, but would be safe if one more instance of G were available. |
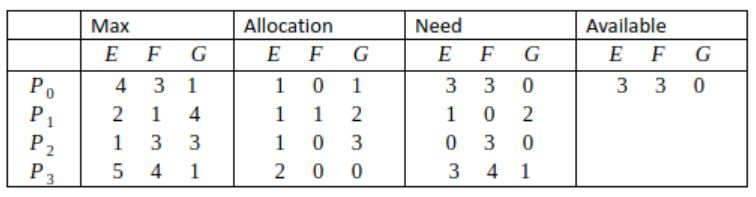
Safe sequence:
〈P0, P2, P1, P3〉
P0: P0 can be allotted 〈3,3,0〉.
After completion Available = 〈4,3,1〉
P2: P2 can be allotted 〈0,3,0〉.
After completion: Available = 〈5,3,4〉
P1: P1 can be allotted 〈1,0,2〉.
After completion: Available = 〈6,4,6〉
P3: P3 can be allotted 〈3,4,1〉.
After completion: Available = 〈8,4,6〉
Question 44 |
A linker reads four modules whose lengths are 200, 800, 600 and 500 words, respectively. If they are loaded in that order, what are the relocation constants?
0, 200, 500, 600 | |
0, 200, 1000, 1600 | |
200, 500, 600, 800 | |
200, 700, 1300, 2100 |
Now 2nd will start loading at 200, since size is 800, so last address is 999.
Now 3rd module will start loading at 1000, since size is 600. So last address is 1599.
Now 4th module will start loading at 1600 and go till 2099.
Question 45 |
Which of the following is an example of a spooled device?
The terminal used to enter the input data for the C program being executed | |
An output device used to print the output of a number of jobs | |
The secondary memory device in a virtual storage system | |
The swapping area on a disk used by the swapper |
For example in printer if a process attempt to print a document but printer is busy printing another document, the process, instead of waiting for printer to become available, write its output to disk. When the printer becomes available the data on disk is printed.
Spooling allows process to request operation from peripheral device without requiring that the device is ready to service the request.
Question 46 |
When the result of a computation depends on the speed of the processes involved there is said to be
cycle stealing | |
rare condition | |
a time lock | |
a deadlock |
Speed of processes corresponds to ordering of processes.
Question 47 |
A counting semaphore was initialized to 10. Then 6P (wait) operations and 4V (signal) operations were completed on this semaphore. The resulting value of the semaphore is
0 | |
8 | |
10 | |
12 |
S = 10
Now 6P operations and uv operations were completed on this semaphore. So final value of S will be
S = 10 - 6 + 4 = 8
Question 48 |
A computer has six tape drives, with n processes competing for them. Each process may need two drives. What is the maximum value of n for the system to be deadlock free?
6 | |
5 | |
4 | |
3 |
So maximum no. of process for the system to be deadlock free is 5.
Question 49 |
The overlay tree for a program is as shown below:
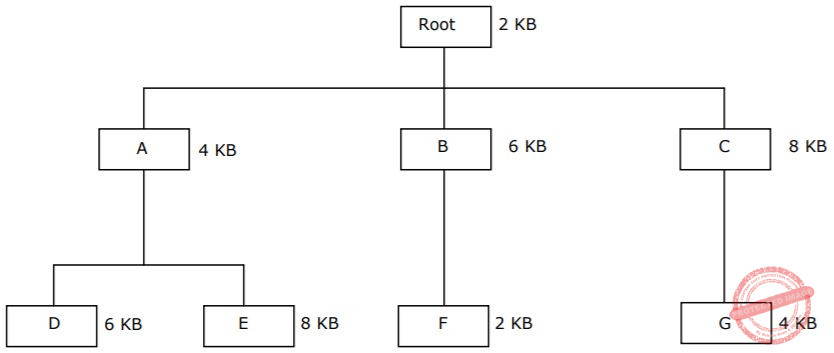
What will be the size of the partition (in physical memory) required to load (and run) this program?
12 KB | |
14 KB | |
10 KB | |
8 KB |
For the above program, maximum memory will be required when running code portion present at leaves.
Maximum requirement
= MAX(12, 14, 10, 14)
= 14
Question 50 |
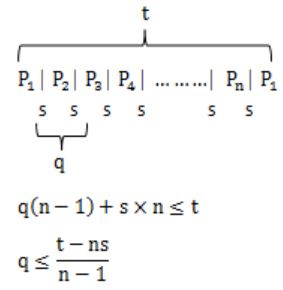
Consider n processes sharing the CPU in a round-robin fashion. Assuming that each process switch takes s seconds, what must be the quantum size q such that the overhead resulting from process switching is minimized but at the same time each process is guaranteed to get its turn at the CPU at least every t seconds?
q ≤ t-ns/n-1 | |
q ≥ t-ns/n-1 | |
q ≤ t-ns/n+1 | |
q ≥ t-ns/n+1 |