Big-Data
Question 1 |
The data node and name node in HADOOP are
Worker Node and Master Node respectively | |
Master Node and Worker Node respectively | |
Both Worker Nodes | |
Both Master Nodes |
Question 1 Explanation:
Explanation: Hadoop Distributed File System(HDFS) has a master/slave architecture. An HDFS cluster consists:
1. NameNode, a master server that manages the file system namespace and regulates access to files by clients.
2. DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files.
Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
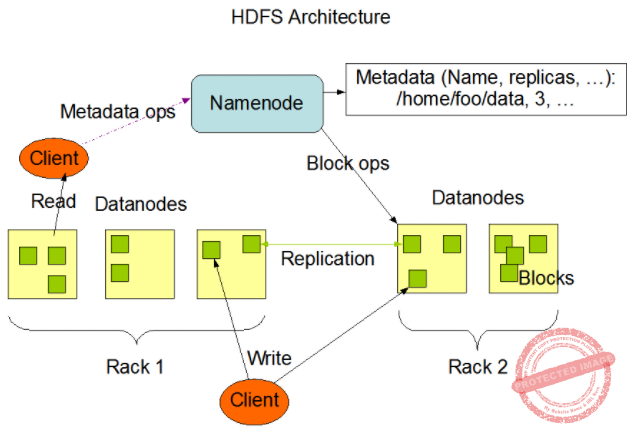
1. NameNode, a master server that manages the file system namespace and regulates access to files by clients.
2. DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files.
Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
Question 2 |
Which of the following is a component of Hadoop?
YARN | |
HDFS | |
Map reduce | |
All of the options |
Question 2 Explanation:
YARN, HDFS and Map reduce are components of Hadoop.
Question 3 |
In reference to Big data, consider the following database
(A) memcached
(B) Couch DB
(C) Infinite graph
Choose the most appropriate answer from the options given below:
(A) memcached
(B) Couch DB
(C) Infinite graph
Choose the most appropriate answer from the options given below:
(A) and (B) only
| |
(B) and (C) only
| |
(C) and (A) only
| |
(A),(B) and (C) |
Question 4 |
Hadoop(a big data tool) works with number of related tools. Choose from the following, the common tools included into Hadoop:
MySQl, Google API and Map reduce | |
Map reduce, Scala and hummer
| |
Map reduce, H base and Hive
| |
Map reduce, hummer and Heron
|
Question 4 Explanation:
The common tools included into Hadoop are mainly
Map reduce
H base
Hive
Map reduce
H base
Hive
Question 5 |
Criticism free idea generation is a factor of _____.
Decision Support System | |
Group Decision Support System | |
Enterprise Resource Support System | |
Artificial Intelligence |
Question 5 Explanation:
Criticism free idea generation is a factor of Group Decision Support System.
Question 6 |
Which of the following statement/s is/are true ?
(i) Facebook has the world’s largest Hadoop cluster.
(ii) Hadoop 2.0 allows live stream processing of real time data
(i) Facebook has the world’s largest Hadoop cluster.
(ii) Hadoop 2.0 allows live stream processing of real time data
Neither (i) nor (ii) | |
Both (i) and (ii) | |
(i) only | |
(ii) only |
Question 6 Explanation:
→ The Data warehouse Hadoop cluster at Facebook has become the largest known Hadoop storage cluster in the world.
Here are some of the details about this single HDFS cluster:
1. 21 PB of storage in a single HDFS cluster
2. 2000 machines
3. 12 TB per machine (a few machines have 24 TB each)
4. 1200 machines with 8 cores each + 800 machines with 16 cores each
5. 32 GB of RAM per machine
6. 15 map-reduce tasks per machine
That's a total of more than 21 PB of configured storage capacity! This is larger than the previously known Yahoo!'s cluster of 14 PB.
→ Hadoop 2.0 allows live stream processing of real time data
Here are some of the details about this single HDFS cluster:
1. 21 PB of storage in a single HDFS cluster
2. 2000 machines
3. 12 TB per machine (a few machines have 24 TB each)
4. 1200 machines with 8 cores each + 800 machines with 16 cores each
5. 32 GB of RAM per machine
6. 15 map-reduce tasks per machine
That's a total of more than 21 PB of configured storage capacity! This is larger than the previously known Yahoo!'s cluster of 14 PB.
→ Hadoop 2.0 allows live stream processing of real time data
There are 6 questions to complete.