Relational-databases
Question 1 |
Consider the following three relations in a relational database.
Employee ( eId , Name ), Brand ( bId , bName ), Own ( eId , bId )
Which of the following relational algebra expressions return the set of elds who own all the brands?
Employee ( eId , Name ), Brand ( bId , bName ), Own ( eId , bId )
Which of the following relational algebra expressions return the set of elds who own all the brands?
 | |
| |
| |
|
Question 1 Explanation:
Option (A) returns eid’s which owns every brand of the relation Brand.
In relational algebra, divide (/) is not a basic operator and it can be derived from the basic operators. In option (B), the divide operator is derived using basic operators and which is equivalent to option (A)
In relational algebra, divide (/) is not a basic operator and it can be derived from the basic operators. In option (B), the divide operator is derived using basic operators and which is equivalent to option (A)
Question 2 |
A relation r(A, B) in a relational database has 1200 tuples. The attribute A has integer values ranging from 6 to 20, and the attribute B has integer values ranging from 1 to 20. Assume that the attributes A and B are independently distributed.
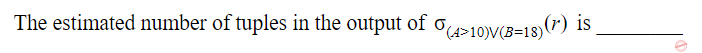
820 |
Question 2 Explanation:
Explanation :
Probability of 1st condition being satisfied(say P(A)) = 10/15 = 2/3
Probability of 2nd condition being satisfied(say P(B)) = 1/20
Probability of both conditions being satisfied(say P(A intersection B)) = 2/3*1/20 = 1/30
Probability of any one condition being satisfied = P(A union B) = P(A)+P(B)-P(A intersection B) = 2/3 + 1/20 - 1/30 = 41/60
therefore, expected number of tuples = (41/60)*1200 = 820
Question 3 |
Which one of the options given below refers to the degree (or arity) of a relation in relational database systems?
Number of attributes of its relation schema. | |
Number of tuples stored in the relation. | |
Number of entries in the relation. | |
Number of distinct domains of its relation schema. |
Question 4 |
What is SQL primarily used for in the context of relational databases ?
To design user interfaces
| |
To create and manipulate databases | |
To display data on web pages | |
To format printed reports |
Question 5 |
Which Of the following best describes the structure of a relational database ?
Data organized into tables with rows and columns
| |
Data organized into files and folders
| |
Data organized into a hierarchical tree structure
| |
Data organized into a network of interconnected nodes
|
Question 6 |
How does a relational database ensure data integrity ?
By encrypting all data stored
| |
By enforcing rules defined in the schema
| |
By compressing data for efficient storage
| |
By allowing unrestricted access to all users |
Question 7 |
Relational database schema normalization is NOT for:
reducing the number of joins required to satisfy a query. | |
eliminating uncontrolled redundancy of data stored in the database. | |
eliminating number of anomalies that could otherwise occur with inserts and deletes. | |
ensuring that functional dependencies are enforced. |
Question 7 Explanation:
→ There are many small Relational database schema in the database system. If we want to execute a query then it may require multiple relation access.
→ So to avoid this one solution is to have only one big relation so that number of relation access can be reduced.
→ This solution leads to redundancy of data stored in database and various inert, delete, update anomalies. So the solution of these problems is Normalisation using functional dependency. So option B,C,D are clearly correct according to above explanation.
→ Option A is not correct because normalisation does not reduce the number of joins required to satisfy a query it only tries to eliminate redundancy and anomalous using functional dependency.
→ So to avoid this one solution is to have only one big relation so that number of relation access can be reduced.
→ This solution leads to redundancy of data stored in database and various inert, delete, update anomalies. So the solution of these problems is Normalisation using functional dependency. So option B,C,D are clearly correct according to above explanation.
→ Option A is not correct because normalisation does not reduce the number of joins required to satisfy a query it only tries to eliminate redundancy and anomalous using functional dependency.
Question 8 |
Consider the following statements regarding relational database model:
(a) NULL values can be used to opt a tuple out of enforcement of a foreign key.
(b) Suppose that table T has only one candidate key. If Q is in 3NF, then it is also in BCNF.
(c) The difference between the project operator (Π) in relational algebra and the SELECT keyword in SQL is that if the resulting table/set has more than one occurrences of the same tuple, then Π will return only one of them, while SQL SELECT will return all.
One can determine that:
(a) NULL values can be used to opt a tuple out of enforcement of a foreign key.
(b) Suppose that table T has only one candidate key. If Q is in 3NF, then it is also in BCNF.
(c) The difference between the project operator (Π) in relational algebra and the SELECT keyword in SQL is that if the resulting table/set has more than one occurrences of the same tuple, then Π will return only one of them, while SQL SELECT will return all.
One can determine that:
(a) and (b) are true. | |
(a) and (b) are true | |
(b) and (c) are true | |
(a), (b) and (c) are true |
Question 8 Explanation:
Option(A) is correct. NULL values can be used to opt a tuple out of enforcement of a foreign key.
Option(B) is correct. Suppose that table T has only one candidate key. If Q is in 3NF, then it is also in BCNF.
Option (C) is correct because the main difference between Project operator and SELECT keyword is that SELECT keyword will return Duplicate values if the exist in the result of a query but Project Operator Do not return Duplicate values if the exist in the result of the query.
Option(B) is correct. Suppose that table T has only one candidate key. If Q is in 3NF, then it is also in BCNF.
Option (C) is correct because the main difference between Project operator and SELECT keyword is that SELECT keyword will return Duplicate values if the exist in the result of a query but Project Operator Do not return Duplicate values if the exist in the result of the query.
There are 8 questions to complete.