Nielit Scientist-B 17-12-2017
Question 1 |
Which of the following statements are not correct?
S1: 3NF decomposition is always lossless join and dependency preserving
S2: 3NF decomposition is always lossless join but may or may not be dependency preserving
S3: BCNF decomposition is always lossless join and dependency preserving
S4: BCNF decomposition is always lossless join but may or may not be dependency preserving
S1: 3NF decomposition is always lossless join and dependency preserving
S2: 3NF decomposition is always lossless join but may or may not be dependency preserving
S3: BCNF decomposition is always lossless join and dependency preserving
S4: BCNF decomposition is always lossless join but may or may not be dependency preserving
Only S1 | |
Only S4 | |
boh S1 and S4 | |
Both S2 and S3 |
Question 1 Explanation:
→ Sometimes, BCNF may not be functional dependency preserving.
→ lossless join should be compulsory in any normal form.
→ lossless join should be compulsory in any normal form.
Question 2 |
According to the given language, which among the following expression does it corresponds to?
Language L={xɛ{0,1}|x is of length 4 or less}
(0+1+0+1+0+1+0+1)4 | |
(0+1)4 | |
(01)4 | |
(0+1+ɛ)4 |
Question 2 Explanation:
The extended notation would be (0+1)4 but however, we may allow some or all the factors to be ε. Thus ε needs to be included in the given regular expression.
Question 3 |
Using bisection method, one root of X4-X-1 lies between 1 and 2. After second iteration the root may lie in interval:
(1.25,1.5) | |
(1,1.25) | |
(1,1.5) | |
None of the options |
Question 3 Explanation:
Given data.
root= X4-X-1.
Root lies Between 1 and 2,
After second iteration=?
Using bisection method.
f(1)=X4-X-1
=1-1-1
= -1
f(2)=X4-X-1
= 24 -2 -1
=13
Given constraint that “root lies between 1 and 2”
Iteration-1: x1=(a+b)/2
=(1+2)/2
= 1.5
f(1.5) = 2.5625
Iteration-2: x2=(a+b)/2
=(1+1.5)/2
=1.25
f(1.25)=0.19140625 >0
Root may lie in between (1, 1.25)
Algorithm - Bisection Scheme
Given a function f (x) continuous on an interval [a,b] and f (a) * f (b) < 0
Do
c=(a+b)/2
if f(a)*f(c)< 0 then b=c
else a=c
while (none of the convergence criteria C1, C2 or C3 is satisfied)
More info:
Bisection method is the simplest among all the numerical schemes to solve the transcendental equations. This scheme is based on the intermediate value theorem for continuous functions .
Consider a transcendental equation f(x)=0 which has a zero in the interval [a,b] and f(a)*f(b)<0. Bisection scheme computes the zero, say c, by repeatedly halving the interval [a,b]. That is, starting with
c = (a+b) / 2
The interval [a,b] is replaced either with [c,b] or with [a,c] depending on the sign of f (a) * f (c) . This process is continued until the zero is obtained. Since the zero is obtained numerically the value of c may not exactly match with all the decimal places of the analytical solution of f (x) = 0 in the interval [a,b]. Hence any one of the following mechanisms can be used to stop the bisection iterations :
C1. Fixing a priori the total number of bisection iterations N i.e., the length of the interval or the maximum error after N iterations in this case is less than | b-a | / 2N.
C2. By testing the condition | ci - c i-1| (where i are the iteration number) less than some tolerance limit, say epsilon, fixed a priori.
C3. By testing the condition | f (ci ) | less than some tolerance limit alpha again fixed a priori.
http://mat.iitm.ac.in/home/sryedida/public_html/caimna/transcendental/bracketing%20methods/bisection/bisection.html
root= X4-X-1.
Root lies Between 1 and 2,
After second iteration=?
Using bisection method.
f(1)=X4-X-1
=1-1-1
= -1
f(2)=X4-X-1
= 24 -2 -1
=13
Given constraint that “root lies between 1 and 2”
Iteration-1: x1=(a+b)/2
=(1+2)/2
= 1.5
f(1.5) = 2.5625
Iteration-2: x2=(a+b)/2
=(1+1.5)/2
=1.25
f(1.25)=0.19140625 >0
Root may lie in between (1, 1.25)
Algorithm - Bisection Scheme
Given a function f (x) continuous on an interval [a,b] and f (a) * f (b) < 0
Do
c=(a+b)/2
if f(a)*f(c)< 0 then b=c
else a=c
while (none of the convergence criteria C1, C2 or C3 is satisfied)
More info:
Bisection method is the simplest among all the numerical schemes to solve the transcendental equations. This scheme is based on the intermediate value theorem for continuous functions .
Consider a transcendental equation f(x)=0 which has a zero in the interval [a,b] and f(a)*f(b)<0. Bisection scheme computes the zero, say c, by repeatedly halving the interval [a,b]. That is, starting with
c = (a+b) / 2
The interval [a,b] is replaced either with [c,b] or with [a,c] depending on the sign of f (a) * f (c) . This process is continued until the zero is obtained. Since the zero is obtained numerically the value of c may not exactly match with all the decimal places of the analytical solution of f (x) = 0 in the interval [a,b]. Hence any one of the following mechanisms can be used to stop the bisection iterations :
C1. Fixing a priori the total number of bisection iterations N i.e., the length of the interval or the maximum error after N iterations in this case is less than | b-a | / 2N.
C2. By testing the condition | ci - c i-1| (where i are the iteration number) less than some tolerance limit, say epsilon, fixed a priori.
C3. By testing the condition | f (ci ) | less than some tolerance limit alpha again fixed a priori.
http://mat.iitm.ac.in/home/sryedida/public_html/caimna/transcendental/bracketing%20methods/bisection/bisection.html
Question 4 |
In a cache memory if total number of sets are 's', then the set offset is:
28 | |
log2s | |
s2 | |
s |
Question 4 Explanation:
If S is the number of sets in our cache, then the set index has s=log2 S bits.
→ Note that in a fully-associative cache, there is only 1 set so the set index will not exist. The remaining bits are used for the tag.
→ If ℓ is the length of the address (in bits), then the number of tag bits is t = ℓ − b − s.
→ Note that in a fully-associative cache, there is only 1 set so the set index will not exist. The remaining bits are used for the tag.
→ If ℓ is the length of the address (in bits), then the number of tag bits is t = ℓ − b − s.
Question 5 |
Which of the following is machine independent optimization?
Loop optimization | |
Redundancy Elimination | |
Folding | |
All of the options |
Question 5 Explanation:

Question 6 |
A stack organized computer has which of the following instructions?
Zero address | |
one address | |
two address | |
three address |
Question 6 Explanation:
Zero-Address Instructions:
A stack-organized computer does not use an address field for the instructions ADD and MUL. The PUSH and POP instructions, however, need an address field to specify the operand that communicates with the stack. The following program shows how X=(A+B)*(C+D) will be written for a stack-organized computer. (TOS stands for top of stack).

To evaluate arithmetic expressions in a stack computer, it is necessary to convert the expression into reverse Polish notation. The name “zero-address” is given to this type of computer because of the absence of an address field in the computational instructions.
A stack-organized computer does not use an address field for the instructions ADD and MUL. The PUSH and POP instructions, however, need an address field to specify the operand that communicates with the stack. The following program shows how X=(A+B)*(C+D) will be written for a stack-organized computer. (TOS stands for top of stack).
To evaluate arithmetic expressions in a stack computer, it is necessary to convert the expression into reverse Polish notation. The name “zero-address” is given to this type of computer because of the absence of an address field in the computational instructions.
Question 7 |
Let G be a grammar in CFG and Let W 1,W2ɛ L(G) such that |W1|=|W2| then which of the following statement is TRUE?
Any derivation of W1 has exactly the same number of steps as any derivation of W2 | |
Different derivation have different length | |
Some derivation of W1 may be shorter the derivation of W2 | |
None of the options |
Question 7 Explanation:
Given data,
W1 and W2 are 2 strings,
|W1|=|W2| means same length
Example CFG grammar:
S→ Cbb | cc
C→ a
W1=cc W2=Cbb
As per the grammar, W1 require only one derivation S→ cc
W2 requires two derivations S→ Cbb→ abb
It means W1 is smaller than W2.
W1 and W2 are 2 strings,
|W1|=|W2| means same length
Example CFG grammar:
S→ Cbb | cc
C→ a
W1=cc W2=Cbb
As per the grammar, W1 require only one derivation S→ cc
W2 requires two derivations S→ Cbb→ abb
It means W1 is smaller than W2.
Question 8 |
Let A be an array of 31 numbers consisting of a sequence of 0’s followed by a sequence of 1’s. The problem is to find the smallest index i such that A[i] is 1 by probing the minimum number of locations in A. The worst case number of probes performed by an optimal algorithm is________
2 | |
4 | |
3 | |
5 |
Question 8 Explanation:
→ If we apply binary search to find the first occurrence of 1 in the list, it will give us the smallest index i where 1 is stored.
→ As in this array sequence of 0’s is followed by sequence of 1’s, the array is sorted. We can apply binary search directly without sorting it.
→ So number of probes = ⌈(log2 31)⌉
= ⌈4.954196310386876⌉
⇒5
→ As in this array sequence of 0’s is followed by sequence of 1’s, the array is sorted. We can apply binary search directly without sorting it.
→ So number of probes = ⌈(log2 31)⌉
= ⌈4.954196310386876⌉
⇒5
Question 9 |
Find the smallest number y such that y*162 (y multiplied by 162) is perfect cube:
24 | |
27 | |
36 | |
38 |
Question 9 Explanation:
Prime factorize: 162
⇒162 =2×3×3×3×3 = 33×(2×3)
For (2×3) to be a perfect cube, it should be multiplied by (22×32)
∴ Required number = y = 22×32 = 36
⇒162 =2×3×3×3×3 = 33×(2×3)
For (2×3) to be a perfect cube, it should be multiplied by (22×32)
∴ Required number = y = 22×32 = 36
Question 10 |
A regular expression is (a+b*c) is equivalent to :
Set of strings with either a or one or more occurences of b followed by c. | |
(b*c+a) | |
Set of strings with either a or zero or more occurence of b followed by c | |
Both (B) and (C) |
Question 10 Explanation:
Given regular expression is (a+b*c). It means either a or zero or more occurence of b followed by c. But according to option A, they given “one or more occurences of b”. So, it is false.
Question 11 |
Which of the following are undecidable?
P1: The language generated by some CFG contains any words of length less than some given number n.
P2: Let L1 be CFL and L2 be regular, to determine whether L1 and L2 have common elements
P3: Any given CFG is ambiguous or not
P4: For any given CFG G, to determine whether ɛ belongs to L(G)
P1: The language generated by some CFG contains any words of length less than some given number n.
P2: Let L1 be CFL and L2 be regular, to determine whether L1 and L2 have common elements
P3: Any given CFG is ambiguous or not
P4: For any given CFG G, to determine whether ɛ belongs to L(G)
P2 only | |
P1 and P2 only | |
P2 and P3 only | |
P3 only |
Question 11 Explanation:
Decidable Problems
A problem is decidable if we can construct a Turing machine which will halt in finite amount of time for every input and give answer as ‘yes’ or ‘no’. A decidable problem has an algorithm to determine the answer for a given input.
Examples
Equivalence of two regular languages:Given two regular languages, there is an algorithm and Turing machine to decide whether two regular languages are equal or not.
Finiteness of regular language: Given a regular language, there is an algorithm and Turing machine to decide whether regular language is finite or not.
Emptiness of context free language: Given a context free language, there is an algorithm whether CFL is empty or not.
Undecidable Problems
A problem is undecidable if there is no Turing machine which will always halt in finite amount of time to give answer as ‘yes’ or ‘no’. An undecidable problem has no algorithm to determine the answer for a given input.
Examples
Ambiguity of context-free languages: Given a context-free language, there is no Turing machine which will always halt in finite amount of time and give answer whether language is ambiguous or not.
Equivalence of two context-free languages: Given two context-free languages, there is no Turing machine which will always halt in finite amount of time and give answer whether two context free languages are equal or not.
Everything or completeness of CFG: Given a CFG and input alphabet, whether CFG will generate all possible strings of input alphabet (∑*)is undecidable.
Regularity of CFL, CSL, REC and REC: Given a CFL, CSL, REC or REC, determining whether this language is regular is undecidable.
A problem is decidable if we can construct a Turing machine which will halt in finite amount of time for every input and give answer as ‘yes’ or ‘no’. A decidable problem has an algorithm to determine the answer for a given input.
Examples
Equivalence of two regular languages:Given two regular languages, there is an algorithm and Turing machine to decide whether two regular languages are equal or not.
Finiteness of regular language: Given a regular language, there is an algorithm and Turing machine to decide whether regular language is finite or not.
Emptiness of context free language: Given a context free language, there is an algorithm whether CFL is empty or not.
Undecidable Problems
A problem is undecidable if there is no Turing machine which will always halt in finite amount of time to give answer as ‘yes’ or ‘no’. An undecidable problem has no algorithm to determine the answer for a given input.
Examples
Ambiguity of context-free languages: Given a context-free language, there is no Turing machine which will always halt in finite amount of time and give answer whether language is ambiguous or not.
Equivalence of two context-free languages: Given two context-free languages, there is no Turing machine which will always halt in finite amount of time and give answer whether two context free languages are equal or not.
Everything or completeness of CFG: Given a CFG and input alphabet, whether CFG will generate all possible strings of input alphabet (∑*)is undecidable.
Regularity of CFL, CSL, REC and REC: Given a CFL, CSL, REC or REC, determining whether this language is regular is undecidable.
Question 12 |
Consider the following four processes with their corresponding arrival time and burst time :
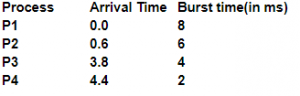
What is the average turnaround time (in ms) for these processes using FCFS scheduling algorithm ?
What is the average turnaround time (in ms) for these processes using FCFS scheduling algorithm ?
15 | |
12.8 | |
13 | |
none of the options |
Question 12 Explanation:
Given, FCFS it means first come first serve. And also it is pure preemptive scheduling.
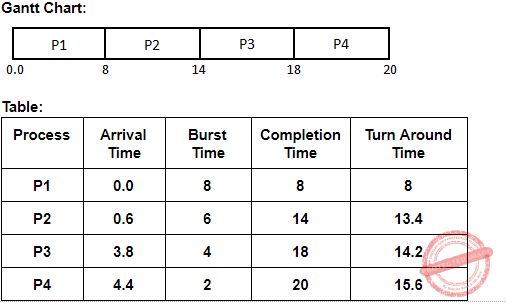
Average Turnaround Time =(8+13.4+14.2+15.6)/4=(51.2)/4=12.8
Average Turnaround Time =(8+13.4+14.2+15.6)/4=(51.2)/4=12.8
Question 13 |
Consider a non pipelined machine with 6 stages. the length of each stage are 20ns, 10ns, 30ns, 25ns, 40ns, and 15ns respectively. Suppose for implementing the pipelining the machine adds 5ns of overhead to each stage for clock skew and set up. What is the speed up factor of the pipelining system (ignoring any hazard impact) ?
7 | |
14
| |
3.11 | |
6.22 |
Question 13 Explanation:
Given data,
Non pipelined machine with 6 stages,
Length of each stage=20,10,30,25,40,15 ns.
Implementing the pipelining the machine adds each stage=5ns overhead.
Speed up factor of the pipelining system=?
Step-1: Non pipeline for 1 instruction to all stages=20+10+30+25+40+15 ns
=140 ns
Step-2: Per cycle adds 5ns overhead to each stage =25,15,35,30,45,20 ns
= 45 ns
Step-3: Speedup factor= Time non pipelining / Time with pipeline
= 140/45
= 3.11 ns
Non pipelined machine with 6 stages,
Length of each stage=20,10,30,25,40,15 ns.
Implementing the pipelining the machine adds each stage=5ns overhead.
Speed up factor of the pipelining system=?
Step-1: Non pipeline for 1 instruction to all stages=20+10+30+25+40+15 ns
=140 ns
Step-2: Per cycle adds 5ns overhead to each stage =25,15,35,30,45,20 ns
= 45 ns
Step-3: Speedup factor= Time non pipelining / Time with pipeline
= 140/45
= 3.11 ns
Question 14 |
In how many ways 8 girl and 8 boys can sit around a circular table so that no two boys sit together?
(7!)2 | |
(8!)2 | |
7!8! | |
15! |
Question 14 Explanation:
→ First fix one boy and place other 7 in alternative seats so total ways is 7! Because they are seated in circular table. (n-1)!.
→ Now place each girl between a pair of boys. So, total ways of seating arrangement of girls is 8!
→ Finally, 7!8! Possible ways are possible.
→ Now place each girl between a pair of boys. So, total ways of seating arrangement of girls is 8!
→ Finally, 7!8! Possible ways are possible.
Question 15 |
Which of the following is added to page table in order to track whether a page of cache has been modified since it was read from the memory?
Reference bit | |
Dirty bit | |
Tag Bit | |
Valid Bit |
Question 15 Explanation:
A dirty bit (or) modified bit is a bit that is associated with a block of computer memory and indicates whether or not the corresponding block of memory has been modified. The dirty bit is set when the processor writes to (modifies) this memory.
→ The bit indicates that its associated block of memory has been modified and has not been saved to storage yet. When a block of memory is to be replaced, its corresponding dirty bit is checked to see if the block needs to be written back to secondary memory before being replaced or if it can simply be removed.
→ Dirty bits are used by the CPU cache and in the page replacement algorithms of an operating system.
→ Dirty bits can also be used in Incremental computing by marking segments of data that need to be processed or have yet to be processed.
→ The bit indicates that its associated block of memory has been modified and has not been saved to storage yet. When a block of memory is to be replaced, its corresponding dirty bit is checked to see if the block needs to be written back to secondary memory before being replaced or if it can simply be removed.
→ Dirty bits are used by the CPU cache and in the page replacement algorithms of an operating system.
→ Dirty bits can also be used in Incremental computing by marking segments of data that need to be processed or have yet to be processed.
There are 15 questions to complete.