Compiler-Design
Question 1 |
USE(S) : the set of variables used in S
IN(S) : the set of variables that are live at the entry of S
OUT(S) : the set of variables that are live at the exit of S
Consider a basic block that consists of two statements, S1followed by S2. Which one of the following statements is correct?
OUT(S1) =IN(S2) U OUT(S2) | |
OUT(S1) =IN(S1) U USE(S1) | |
OUT(S1) =USE(S1) U IN(S2) | |
OUT(S1) =IN(S2) |

Question 2 |
z = x + 3 + y -> f1 + y -> f2;
for (i = 0; i < 200; i = i+2) {
if (z > i) {
p = p + x + 3;
q = q + y -> f1;
} else {
p = p + y -> f2;
q = q + x + 3;
}
}
Assume that the variable y points to a struct (allocated on the head) containing two fields f1 and f2, and the local variables x, y, z, p, q, and i are allotted registers. Common subexpression elimination (CSE) optimization is applied on the code. The number of addition and dereference operations (of the form y->f1 or y->f2) in the optimized code, respectively, are:
303 and 2 | |
303 and 102 | |
403 and 102 | |
203 and 2 |
In compiler theory, common subexpression elimination is a compiler optimization that searches for instances for identical expressions (i.e, they all evaluate to the same value), and analyzes whether it is worthwhile replacing them with a single variable holding the computed value.
For example: Consider the following block of code
a=x+y+z;
r=p+q;
b=x+y+r;
The code after common subexpression elimination.
t=x+y;
a=t+z;
r=p+q;
b=t+r;
In the given code
z = x + 3 + y -> f1 + y -> f2;
for (i = 0; i < 200; i = i+2) {
if (z > i) {
p = p + x + 3;
q = q + y -> f1;
} else {
p = p + y -> f2;
q = q + x + 3;
}
}
X+3 is common subexpression, also y -> f1 & y -> f2 is found in first line itself so they are also like common subexpression.
Hence the code after common subexpression
t1=x+3; t2=y -> f1 ; t3= y -> f2;
z = t1 + t2 + t3;
for (i = 0; i < 200; i = i+2) {
if (z > i) {
p = p + t1;
q = q + t2;
} else {
p = p + t3;
q = q + t1;
}
}
Hence two dereference operations (of the form y->f1 or y->f2) in the optimized code.
The number of addition in the optimized code are:
Loop will execute for 100 times and in loop one addition (i+2)
So 100 additions.
Inside loop we have two additions (either in if block or in else block) so 200 additions inside loop
Hence 300 additions in loop (loop body as well as inside)
First 2 lines contains 3 additions
t1=x+3;
z = t1 + t2 + t3;
Hence total 303 additions.
So 303 and 2 are the answer.
Question 3 |
Three address code | |
Abstract Syntax Tree (AST) | |
Symbol table | |
Control Flow Graph (CFG) |
-
An intermediate representation is a representation of a program “between” the source and target languages. A good IR is one that is fairly independent of the source and target languages, so that it maximizes its ability to be used in a retargetable compiler.
Types of intermediate representation:
- Structured (Tree such as abstract syntax tree or Graph such as CFG, single static assignment)
- tuple-based, generally three-address code (quadruples)
Symbol table is not an intermediate representation of a source program. Symbol table is created in the first phase (lexical analysis phase and subsequently updated in later phases) and it stores the information about the occurrence of various entities such as variable names, function names, objects, classes, interfaces, etc.
Abstract syntax tree and three address code are well known representations of intermediate code.
CFG i.e., control flow graph is also a representation of intermediate code which represents the flow of control of the program. In CFG we break sequences of three address codes into basic blocks hence CFG is also a representation of intermediate code as it contains three address codes along with control flow representation with help of blocks and edges (arrows).
Question 4 |
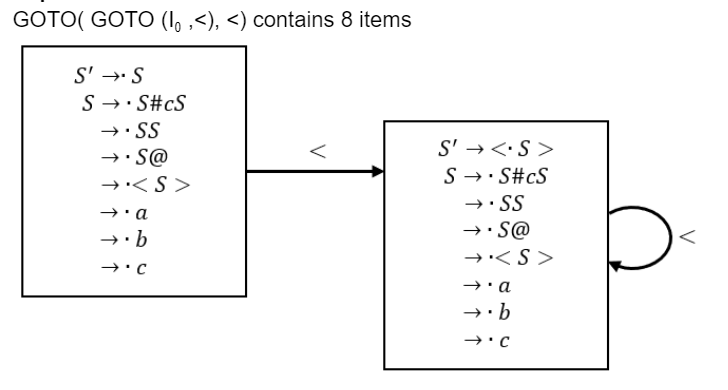
S’ ⟶ S
S ⟶ S#cS
S ⟶ SS
S ⟶ S@
S ⟶ < S >
S ⟶ a
S ⟶ b
S ⟶ c
Let I0=CLOSURE({S' ⟶.S}). The number of items in the set GOTO(GOTO(I0, <), <) is ____________.
8 |
Question 5 |
int main() {
Integer x;
return 0;
}
Which one of the following phases in a seven-phase C compiler will throw an error?
Syntax analyzer | |
Lexical analyzer | |
Semantic analyzer | |
Machine dependent optimizer |
Question 6 |
A linker is given object modules for a set of programs that were compiled separately. What information need to be included in an object module?
Object code | |
Relocation bits | |
Names and locations of all external symbols defined in the object module
| |
Absolute addresses of internal symbols |
To link to external symbols it must know the location of external symbols.
Question 7 |
A shift reduce parser carries out the actions specified within braces immediately after reducing with the corresponding rule of grammar
S → xxW {print "1"}
S → y {print "2"}
W → Sz {print "3"}
What is the translation of xxxxyzz using the syntax directed translation scheme described by the above rules?
23131 | |
11233 | |
11231 | |
33211 |
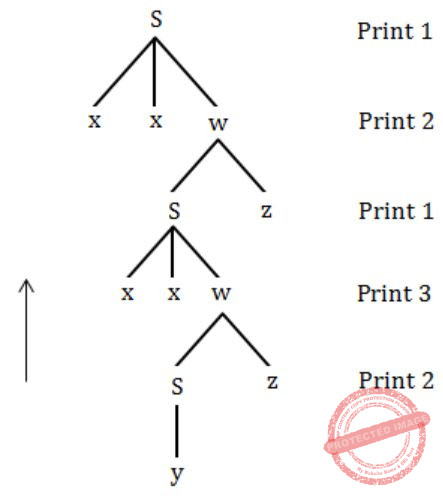
⇒ 23131
Note SR is bottom up parser.
Question 8 |
Construct the LL(1) table for the following grammar.
1. Expr → _Expr 2. Expr → (Expr) 3. Expr → Var Expr Tail 4. ExprTail → _Expr 5. ExprTail → λ 6. Var → Id Var Tail 7. VarTail → (Expr) 8. VarTail → λ 9. Goal → Expr$
Theory Explanation. |
Question 9 |
(a) Translate the arithmetic expression a*-(b+c) into syntax tree.
(b) A grammar is said to have cycles if it is the case that
A ⇒ +A
Show that no grammar that has cycles can be LL(I).
Theory Explanation. |
Question 10 |
Consider the following grammar.
S → aSB|d
B → b
The number of reduction steps taken by a bottom-up parser while accepting the string aaadbbb is _______.
7 |
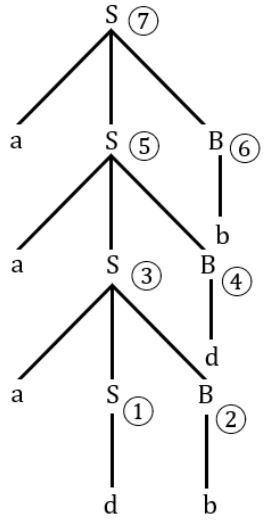
7 reductions total.
Question 11 |
Consider the following statements.
- I. Symbol table is accessed only during lexical analysis and syntax analysis.
II. Compilers for programming languages that support recursion necessarily need heap storage for memory allocation in the run-time environment.
III. Errors violating the condition ‘any variable must be declared before its use’ are detected during syntax analysis.
Which of the above statements is/are TRUE?
II only | |
I only | |
I and III only
| |
None of I, II and III |
II is wrong as compilers which supports recursion require stack memory in run time environment.
III is wrong “any variable must be declared before its use” is a semantic error and not syntax error.
Question 12 |
Consider the productions A⟶PQ and A⟶XY. Each of the five non-terminals A, P, Q, X, and Y has two attributes: s is a synthesized attribute, and i is an inherited attribute. Consider the following rules.
Rule 1: P.i = A.i + 2, Q.i = P.i + A.i, and A.s = P.s + Q.s
Rule 2: X.i = A.i + Y.s and Y.i = X.s + A.i
Which one of the following is TRUE?
Only Rule 2 is L-attributed.
| |
Neither Rule 1 nor Rule 2 is L-attributed. | |
Both Rule 1 and Rule 2 are L-attributed. | |
Only Rule 1 is L-attributed.
|
Question 13 |
The pass number for each of the following activities
- 1. Object code generation
2. Literals added to literal table
3. Listing printed
4. Address resolution of local symbols
That occur in a two pass assembler respectively are
1, 2, 1, 2 | |
2, 1, 2, 1 | |
2, 1, 1, 2 | |
1, 2, 2, 2 |
Pass 1:
1) Assign addresses to all statements in the program.
2) Save the values assigned to all labels for use in pass 2.
3) Perform some processing of assembler directives.
Pass 2:
1) Assemble instructions.
2) Generate data values defined by BYTE, WORD etc.
3) Perform processing of assembler directives not done during pass 1.
4) Write the program and assembling listing.
Question 14 |
Which of the following macros can put a micro assembler into an infinite loop?
(i) .MACRO M1 X
.IF EQ, X ;if X=0 then
M1 X + 1
.ENDC
.IF NE X ;IF X≠0 then
.WORD X ;address (X) is stored here
.ENDC
.ENDM
(ii) .MACRO M2 X
.IF EQ X
M2 X
.ENDC
.IF NE, X
.WORD X+1
.ENDC
.ENDM (ii) only | |
(i) only | |
both (i) and (ii) | |
None of the above |
Question 15 |
Given below are the transition diagrams for two finite state machine M1 and M2 recognizing languages L1 and L2 respectively.
(a) Display the transition diagram for a machine that recognizes L1.L2, obtained from transition diagrams for M1 and M2 by adding only ε transitions and no new states.
(b) Modify the transition diagram obtained in part(a) obtain a transition diagram for a machine that recognizes (L1.L2)∗ by adding only ε transitions and no new states. (Final states are enclosed in double circles).
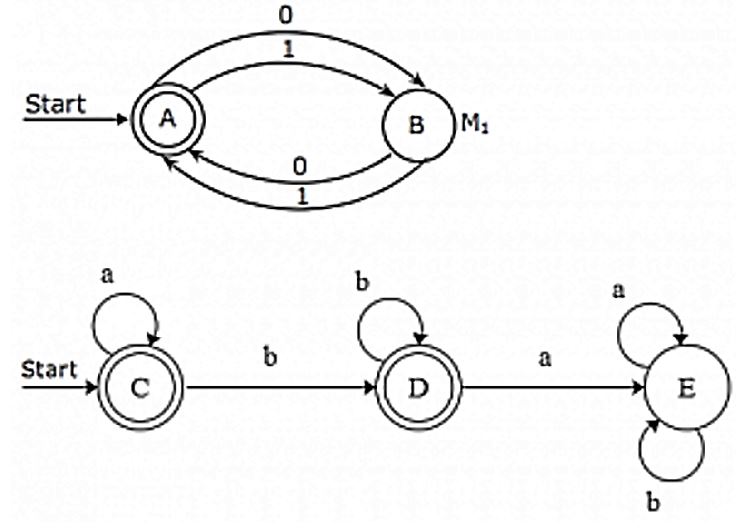
Theory Explanation. |
Question 16 |
Consider the syntax-directed translation schema (SDTS) shown below:
E → E + E {print “+”}
E → E ∗ E {print “.”}
E → id {print id.name}
E → (E)
An LR-parser executes the actions associated with the productions immediately after a reduction by the corresponding production. Draw the parse tree and write the translation for the sentence.
(a+b)∗(c+d), using the SDTS given above.
Theory Explanation. |
Question 17 |
In the following grammar
X ::= X ⊕ Y/Y
Y ::= Z * Y/Z
Z ::= id
Which of the following is true?
‘⊕’ is left associative while ‘*’ is right associative | |
Both ‘⊕’ and ‘*’ is left associative | |
‘⊕’ is right associative while ‘*’ is left associative | |
None of the above |
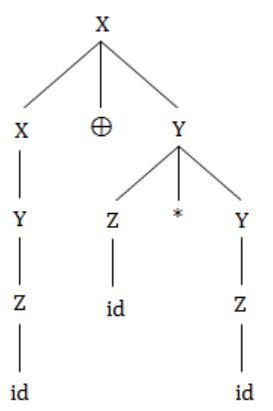
⊕ is left associative.
* is right associative.
Question 18 |
A language L allows declaration of arrays whose sizes are not known during compilation. It is required to make efficient use of memory. Which of the following is true?
A compiler using static memory allocation can be written for L | |
A compiler cannot be written for L; an interpreter must be used | |
A compiler using dynamic memory allocation can be written for L | |
None of the above |
Question 19 |
The conditional expansion facility of macro processor is provided to
test a condition during the execution of the expanded program | |
to expand certain model statements depending upon the value of a condition during the execution of the expanded program | |
to implement recursion | |
to expand certain model statements depending upon the value of a condition during the process of macro expansion |
Question 20 |
Heap allocation is required for languages
that support recursion | |
that support dynamic data structures | |
that use dynamic scope rules | |
None of the above |
Question 21 |
Which one of the following statements is FALSE?
Context-free grammar can be used to specify both lexical and syntax rules. | |
Type checking is done before parsing. | |
High-level language programs can be translated to different Intermediate Representations. | |
Arguments to a function can be passed using the program stack. |
Question 22 |
Consider the following parse tree for the expression a#b$c$d#e#f, involving two binary operators $ and #.
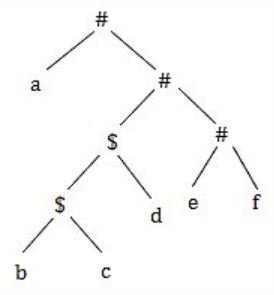
Which one of the following is correct for the given parse tree?
$ has higher precedence and is left associative; # is right associative | |
# has higher precedence and is left associative; $ is right associative
| |
$ has higher precedence and is left associative; # is left associative | |
# has higher precedence and is right associative; $ is left associative
|
Question 23 |
1: a?(b∣c)*aT
2: b?(a∣c)*bT
3: c?(b∣a)*c
Note that ‘x?’ means 0 or 1 occurrence of the symbol x. Note also that the analyzer outputs the token that matches the longest possible prefix.
If the string bbaacabc is processes by the analyzer, which one of the following is the sequence of tokens it outputs?
T1T2T3 | |
T1T1T3 | |
T2T1T3 | |
T3T3 |
T1 : (b+c)*a + a(b+c)*a
T2 : (a+c)*b + b(a+c)*b
T3 : (b+a)*c + c(b+a)*c
Now the string is: bbaacabc
Please NOTE:
Token that matches the longest possible prefix
We can observe that the longest possible prefix in string is : bbaac which can be generated by T3.
After prefix we left with “abc” which is again generated by T3 (as longest possible prefix).
So, answer is T3T3.
Question 24 |
In a resident – OS computer, which of the following systems must reside in the main memory under all situations?
Assembler | |
Linker | |
Loader | |
Compiler |
Some OS may allow virtual memory may allow the loader to be located in a region of memory that is in page table.
Question 25 |
Which of the following statements is true?
SLR parser is more powerful than LALR | |
LALR parser is more powerful than Canonical LR parser | |
Canonical LR parser is more powerful than LALR parser | |
The parsers SLR, Canonical CR, and LALR have the same power |
Canonical LR parser is more powerful than LALR parser.
Question 26 |
Type checking is normally done during
lexical analysis | |
syntax analysis | |
syntax directed translation | |
code optimization |
Question 27 |
Let the attribute 'val' give the value of a binary number generated by S in the following grammar:
S → L.L | L L→ LB | B B → 0 | 1
For example, an input 101.101 gives S.val = 5.625
Construct a syntax directed translation scheme using only synthesized attributes, to determine S.val.
Theory Explanation. |
Question 28 |
Which of the following is the most powerful parsing method?
LL (1) | |
Canonical LR | |
SLR | |
LALR |
LR > LALR > SLR
Question 29 |
The number of tokens in the Fortran statement DO 10 I = 1.25 is
3 | |
4 | |
5 | |
None of the above |
10 → 2
I → 3
= → 4
1.25 → 5
Question 30 |
Let synthesized attribute val give the value of the binary number generated by S in the following grammar. For example, on output 101.101, S.val = 5.625.
S → LL|L L → LB|B B → 0|1
Write S-attributed values corresponding to each of the productions to find S.val.
Theory Explanation. |
Question 31 |
The number of tokens in the following C statement.
printf("i = %d, &i = %x", i, &i);
is
3 | |
26 | |
10 | |
21 |
(i) Keyword
(ii) Identifier
(iii) Constant
(iv) Variable
(v) String
(vi) Operator
Print = Token 1
( = Token 2
"i=%d%x" = Token 3 [Anything inside " " is one Token]
, = Token 4
i = Token 5
, = Token 6
& = Token 7
i = Token 8
) = Token 9
; = Token 10
Here, totally 10 Tokens are present in the equation.
Question 32 |
Which of the following derivations does a top-down parser use while parsing an input string? The input is assumed to be scanned in left to right order.
Leftmost derivation | |
Leftmost derivation traced out in reverse | |
Rightmost derivation | |
Rightmost derivation traced out in reverse |
Bottom-Up parser - Reverse of rightmost derivation
Question 33 |
Given the following expression grammar:
E → E * F | F + E | F
F → F - F | id
which of the following is true?
* has higher precedence than + | |
- has higher precedence than * | |
+ and – have same precedence | |
+ has higher precedence than * |
Order of precedence is *, +, -.
Here * and + have equal preference, '-' can have higher precedence than + and *.
Question 34 |
Consider the syntax directed translation scheme (SDTS) given in the following.
Assume attribute evaluation with bottom-up parsing, i.e., attributes are evaluated immediately after a reduction.
E → E1 * T {E.val = E1.val * T.val}
E → T {E.val = T.val}
T → F – T1{T.val = F.val – T1.val}
T → F {T.val = F.val}
F → 2 {F.val = 2}
F → 4 {F.val = 4}
(a) Using this SDTS, construct a parse tree for the expression
4 – 2 – 4 * 2
and also compute its E.val.
(b) It is required to compute the total number of reductions performed to parse a given input. Using synthesized attributes only, modify the SDTS given, without changing the grammar, to find E.red, the number of reductions performed while reducing an input to E.
Theory Explanation is given below. |
Question 35 |
The process of assigning load addresses to the various parts of the program and adjusting the code and date in the program to reflect the assigned addresses is called
Assembly | |
Parsing | |
Relocation | |
Symbol resolution |
Question 36 |
Which of the following statements is false?
An unambiguous grammar has same leftmost and rightmost derivation | |
An LL(1) parser is a top-down parser | |
LALR is more powerful than SLR | |
An ambiguous grammar can never be LR(k) for any k |
Option C: LALR is more powerful than SLR.
Option D: An ambiguous grammar can never be LR (k) for any k, because LR(k) algorithm aren’t designed to handle ambiguous grammars. It would get stuck into undecidability problem, if employed upon an ambiguous grammar, no matter how large the constant k is.
Question 37 |
Consider the following grammar with terminal alphabet ∑{a,(,),+,*} and start symbol E. The production rules of the grammar are:
E → aA
E → (E)
A → +E
A → *E
A → ε
(a) Compute the FIRST and FOLLOW sets for E and A.
(b) Complete the LL(1) parse table for the grammar.
Theory Explanation is given below. |
Question 38 |
The syntax of the repeat-until statement is given by the gollowing grammar
S → repeat S1 until E
Where E stands for expressions, S and S1 stand for statement. The non-terminals S and S1 have an attribute code that represents generated code. The nonterminal E has two attributes. The attribute code represents generated code to evaluate the expression and store its truth value in a distinct variable, and the attribute varName contains the name of the variable in which the truth value is stored? The truth-value stored in the variable is 1 if E is true, 0 if E is false.
Give a syntax-directed definition to generate three-address code for the repeatuntil statement. Assume that you can call a function newlabel( ) that returns a distinct label for a statement. Use the operator ‘\\’ to concatenate two strings and the function gen(s) to generate a line containing the string s.
Theory Explanation is given below. |
Question 39 |
(a) Remove left-recursion from the following grammar:
S → Sa| Sb | a | b
(b) Consider the following grammar:
S → aSbS| bSaS |ε
Construct all possible parse trees for the string abab. Is the grammar ambiguous?
Theory Explanation is given below. |
Question 40 |
(a) Construct all the parse trees corresponding to i + j * k for the grammar
E → E+E
E → E*E
E → id
- (b) In this grammar, what is the precedence of the two operators * and +?
(c) If only one parse tree is desired for any string in the same language, what changes are to be made so that the resulting LALR(1) grammar is non-ambiguous?
Theory Explanation is given below. |
Question 41 |
Which of the following suffices to convert an arbitrary CFG to an LL(1) grammar?
Removing left recursion alone | |
Factoring the grammar alone | |
Removing left recursion and factoring the grammar | |
None of the above |
To convert an arbitrary CFG to an LL(1) grammar we need to remove the left recursion and as well as left factoring without that we cannot convert.
Question 42 |
Assume that the SLR parser for a grammar G has n1 states and the LALR parser for G has n2 states. The relationship between n1 and n2 is:
n1 is necessarily less than n2 | |
n1 is necessarily equal to n2
| |
n1 is necessarily greater than n2
| |
None of the above |
Question 43 |
In a bottom-up evaluation of a syntax directed definition, inherited attributes can
always be evaluated | |
be evaluated only if the definition is L-attributed | |
be evaluated only if the definition has synthesized attributes | |
never be evaluated |
L-Attributed definitions are a class of syntax directed definitions whose attributes can be evaluated by a single traversal of the parse-tree.
Question 44 |
Which of the following statements is FALSE?
In statically typed languages, each variable in a program has a fixed type | |
In un-typed languages, values do not have any types | |
In dynamically typed languages, variables have no types | |
In all statically typed languages, each variable in a program is associated with values of only a single type during the execution of the program
|
Question 45 |
Consider the grammar shown below
S → i E t S S' | a S' → e S | ε E → b
In the predictive parse table. M, of this grammar, the entries M[S', e] and M[S', $] respectively are
{S'→e S} and {S'→ε} | |
{S'→e S} and { } | |
{S'→ε} and {S'→ε} | |
{S'→e S, S'→ε} and {S'→ε} |
First(S') = {e,ε}
First(E) = {b}
Follow(S') = {e,$}
Only when 'First' contains ε, we need to consider FOLLOW for getting the parse table entry.
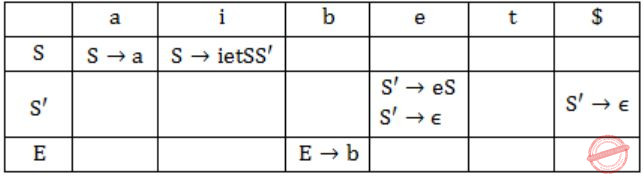
Hence, option (D) is correct.
Question 46 |
Consider the grammar shown below.
S → C C C → c C | d
The grammar is
LL(1) | |
SLR(1) but not LL(1)
| |
LALR(1) but not SLR(1) | |
LR(1) but not LALR(1)
|
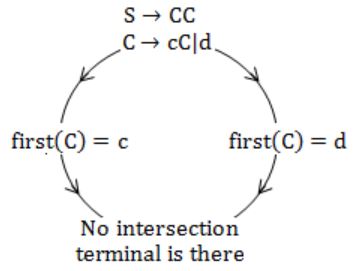
Hence, it is LL(1).
Question 47 |
Consider the translation scheme shown below.
S → T R
R → + T {print ('+');} R|ε
T → num {print(num.val);}
Here num is a token that represents an integer and num.val represents the corresponding integer value. For an input string '9 + 5 + 2', this translation scheme will print
9 + 5 + 2 | |
9 5 + 2 + | |
9 5 2 + + | |
+ + 9 5 2 |
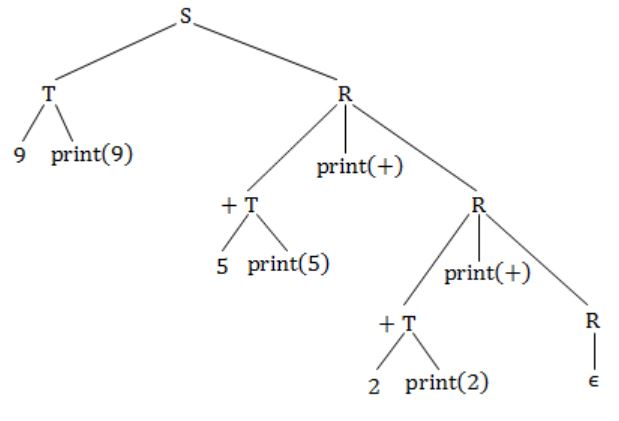
Now traverse the tree and whatever comes first to print, just print it.
Answer will be 9 5 + 2 +.
Question 48 |
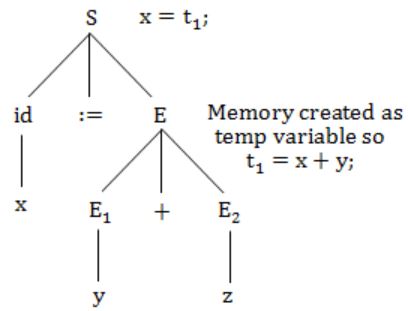
Consider the syntax directed definition shown below.
S → id := E {gen (id.place = E.place;);}
E → E1 + E2 {t = newtemp ( );
gen(t = E1.place + E2.place;);
E.place = t}
E → id {E.place = id.place;}
Here, gen is a function that generates the output code, and newtemp is a function that returns the name of a new temporary variable on every call. Assume that ti's are the temporary variable names generated by newtemp. For the statement 'X: = Y + Z', the 3-address code sequence generated by this definition is
X = Y + Z | |
t1 = Y + Z; X = t1 | |
t1= Y; t2 = t1 + Z; X = t2 | |
t1 = Y; t2 = Z; t3 = t1 + t2; X = t3
|
Question 49 |
Which of the following is NOT an advantage of using shared, dynamically linked libraries as opposed to using statically linked libraries?
Smaller sizes of executable files | |
Lesser overall page fault rate in the system | |
Faster program startup
| |
Existing programs need not be re-linked to take advantage of newer versions of libraries |
Question 50 |
Which of the following grammar rules violate the requirements of an operator grammar? P,Q,R are nonterminals, and r,s,t are terminals.
- (i) P → Q R
(ii) P → Q s R
(iii) P → ε
(iv) P → Q t R r
(i) only | |
(i) and (iii) only | |
(ii) and (iii) only | |
(iii) and (iv) only |
i) On RHS it contains two adjacent non-terminals.
ii) Have nullable values.