Artificial-Intelligence
Question 1 |

(a)-(iii), (b)-(iv), (c)-(i), (d)-(ii) | |
(a)-(iii), (b)-(iv), (c)-(ii), (d)-(i) | |
(a)-(iv), (b)-(iii), (c)-(i), (d)-(ii) | |
(a)-(iv), (b)-(iii), (c)-(ii), (d)-(i) |
Question 1 Explanation:
Intelligence → Judgemental
Knowledge → Codifiable, endorsed with relevance and purpose
Information → Scattered facts, easily transferable
Data → Contextual, tacit, transfer needs learning
Knowledge → Codifiable, endorsed with relevance and purpose
Information → Scattered facts, easily transferable
Data → Contextual, tacit, transfer needs learning
Question 2 |

(a)-(i), (b)-(iv), (c)-(iii), (d)-(ii) | |
(a)-(iv), (b)-(i), (c)-(ii), (d)-(iii) | |
(a)-(i), (b)-(iv), (c)-(ii), (d)-(iii) | |
(a)-(iv), (b)-(ii), (c)-(i), (d)-(iii) |
Question 2 Explanation:
Steepest – accent Hill Climbing→ Considers all moves from current state and selects best move.
Branch – and – bound → Keeps track of all partial paths which can be a candidate for further exploration
Constraint satisfaction → Discover problem state(s) that satisfy a set of constraints
Means – end – analysis → Detects difference between current state and goal state
Branch – and – bound → Keeps track of all partial paths which can be a candidate for further exploration
Constraint satisfaction → Discover problem state(s) that satisfy a set of constraints
Means – end – analysis → Detects difference between current state and goal state
Question 3 |
Standard planning algorithms assume environment to be __________.
Both deterministic and fully observable | |
Neither deterministic nor fully observable | |
Deterministic but not fully observable | |
Not deterministic but fully observable |
Question 3 Explanation:
→ Classical planning environments that are fully observable, deterministic, finite, static and discrete (in time, action, objects and effects).
Question 4 |
Entropy of a discrete random variable with possible values {x1, x2, ..., xn} and probability density function P(X) is :
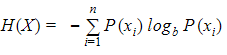
The value of b gives the units of entropy. The unit for b=10 is :
The value of b gives the units of entropy. The unit for b=10 is :
bits | |
bann | |
nats | |
deca |
Question 5 |
For any binary (n, h) linear code with minimum distance (2t+1) or greater
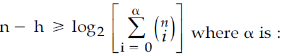
2t+1 | |
t+1 | |
t | |
t-1 |
Question 6 |
Consider a Takagi - Sugeno - Kang (TSK) Model consisting rules of the form: If Xi is Ai1 and... and xr is Air THEN y = fi(x1, x2,.... xr) = bi0 + bi1x1 + birxr assume, ai is the matching degree of rule i, then the total output of the model is given by:
 | |
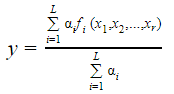 | |
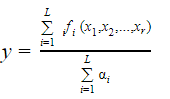 | |
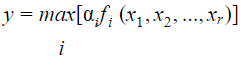 |
Question 7 |
Consider a single perceptron with sign activation function. The perceptron is represented by weight vector [0.4 −0.3 0.1]t and a bias θ = 0. If the input vector to the perceptron is X = [0.2 0.6 0.5] then the output of the perceptron is:
1 | |
0 | |
-0.25 | |
-1 |
Question 8 |
Let Wo represents weight between node i at layer k and node j at layer (k – 1) of a given multilayer perceptron. The weight updation using gradient descent method is given by
Where α and E represents learning rate and Error in the output respectively?
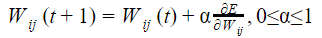 | |
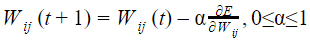 | |
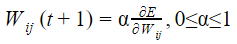 | |
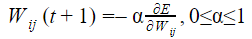 |
Question 9 |
Consider the following learning algorithms:
(a) Logistic regression
(b) Back propagation
(c) Linear repression Which of the following option represents classification algorithms?
(a) and (b) only | |
(a) and (c) only | |
(b) and (c) only | |
(a), (b) and (c) |
Question 9 Explanation:
The classification learning algorithms are
1. Logistic regression
2. Back propagation
Note: They given spelling mistake in Logistic regression instead of “Logistic repression”.
According to final key, given marks to all.
1. Logistic regression
2. Back propagation
Note: They given spelling mistake in Logistic regression instead of “Logistic repression”.
According to final key, given marks to all.
Question 10 |
Consider the following:
(a) Trapping at local maxima
(b) Reaching a plateau
(c) Traversal along the ridge.
Which of the following option represents shortcomings of the hill climbing algorithm?
(a) Trapping at local maxima
(b) Reaching a plateau
(c) Traversal along the ridge.
Which of the following option represents shortcomings of the hill climbing algorithm?
(a) and (b) only | |
(a) and (c) only | |
(b) and (c) only | |
(a), (b) and (c) |
Question 10 Explanation:
Hill climbing limitations:
1. Local Maxima: Hill-climbing algorithm reaching the vicinity a local maximum value, gets drawn towards the peak and gets stuck there, having no other place to go.
2. Ridges: These are sequences of local maxima, making it difficult for the algorithm to navigate.
3. Plateaux: This is a flat state-space region. As there is no uphill to go, algorithm often gets lost in the plateau.
To avoid above problems using 3 standard types of hill climbing algorithm is
1. Stochastic Hill Climbing selects at random from the uphill moves. The probability of selection varies with the steepness of the uphill move.
2. First-Choice Climbing implements the above one by generating successors randomly until a better one is found.
3. Random-restart hill climbing searches from randomly generated initial moves until the goal state is reached.
1. Local Maxima: Hill-climbing algorithm reaching the vicinity a local maximum value, gets drawn towards the peak and gets stuck there, having no other place to go.
2. Ridges: These are sequences of local maxima, making it difficult for the algorithm to navigate.
3. Plateaux: This is a flat state-space region. As there is no uphill to go, algorithm often gets lost in the plateau.
To avoid above problems using 3 standard types of hill climbing algorithm is
1. Stochastic Hill Climbing selects at random from the uphill moves. The probability of selection varies with the steepness of the uphill move.
2. First-Choice Climbing implements the above one by generating successors randomly until a better one is found.
3. Random-restart hill climbing searches from randomly generated initial moves until the goal state is reached.
Question 11 |
According to Dempster-Shafer theory for uncertainty management,
Where Bel(A) denotes Belief of event A.
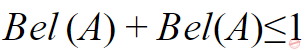 | |
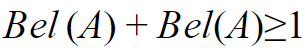 | |
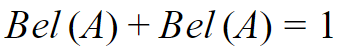 | |
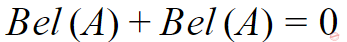 |
Question 12 |
Overfitting is expected when we observe that?
With training iterations error on training set as well as test set decreases | |
With training iterations error on training set decreases but test set increases | |
With training iterations error on training set as well as test set increases | |
With training iterations training set as well as test error remains constant |
Question 13 |
The A* algorithm is optimal when,
It always finds the solution with the lowest total cost if the heuristic 'h' is admissible. | |
Always finds the solution with the highest total cost if the heuristic 'h' is admissible. | |
Finds the solution with the lowest total cost if the heuristic 'h' is not admissible. | |
It always finds the solution with the highest total cost if the heuristic 'h' is not admissible. |
Question 14 |
Which Artificial intelligence technique enables the computers to understand the associations and relationships between objects & Events?
Heuristic Processing | |
Cognitive Science | |
Relative Symbolism | |
Pattern matching |
Question 15 |
What does the values of alpha-beta search get updated?
Along the path of search | |
Initial state itself | |
At the end | |
None of these |
Question 16 |
A 4-input neuron has weights 1,2,3,4. The transfer function is linear with the constant of proportionality being equal to 3. The inputs are 5,7,10,30, respectively, Then the output will be,
120 | |
213 | |
410 | |
507 |
Question 17 |
In a game playing search tree, up to which depth α-β pruning can be applied?
(A) Root (0) level
(B) 6 level
(C) 8 level
(D) Depends on utility value in a breadth first order
(A) Root (0) level
(B) 6 level
(C) 8 level
(D) Depends on utility value in a breadth first order
(B) and (C) only | |
(A) and (B) only | |
(A),(B) and (C) only | |
(A) and (D) only |
Question 17 Explanation:
Alpha-beta pruning is a modified version of the minimax algorithm. It is an optimization technique for the minimax algorithm.
Alpha-beta Algorithm:
- Uses Depth first search
- only considers nodes along a single path from root at any time
α = highest-value choice found at any choice point of path for MAX (initially, α = −infinity)
β = lowest-value choice found at any choice point of path for MIN (initially, β = +infinity)
- Pass current values of α and β down to child nodes during search.
- Update values of α and β during search:
- MAX updates α at MAX nodes
- MIN updates β at MIN nodes
When to Prune:
- Prune whenever α ≥ β.
- Prune below a Max node whose alpha value becomes greater than or equal to the beta value of its ancestors.
- Max nodes update alpha based on children’s returned values. - Prune below a Min node whose beta value becomes less than or equal to the alpha value of its ancestors.
- Min nodes update beta based on children’s returned values.
Effectiveness of Alpha-Beta Search:
- Alpha/beta best case is O(b(d/2)) rather than O(bd)
- This is the same as having a branching factor of sqrt(b),
- (sqrt(b))d/ = b(d/2) (i.e., we have effectively gone from b to square root of b)
- In chess go from b ~ 35 to b ~ 6
- permitting much deeper search in the same amount of time
- In practice it is often b(2d/3)
Alpha-beta Algorithm:
- Uses Depth first search
- only considers nodes along a single path from root at any time
α = highest-value choice found at any choice point of path for MAX (initially, α = −infinity)
β = lowest-value choice found at any choice point of path for MIN (initially, β = +infinity)
- Pass current values of α and β down to child nodes during search.
- Update values of α and β during search:
- MAX updates α at MAX nodes
- MIN updates β at MIN nodes
When to Prune:
- Prune whenever α ≥ β.
- Prune below a Max node whose alpha value becomes greater than or equal to the beta value of its ancestors.
- Max nodes update alpha based on children’s returned values. - Prune below a Min node whose beta value becomes less than or equal to the alpha value of its ancestors.
- Min nodes update beta based on children’s returned values.
Effectiveness of Alpha-Beta Search:
- Alpha/beta best case is O(b(d/2)) rather than O(bd)
- This is the same as having a branching factor of sqrt(b),
- (sqrt(b))d/ = b(d/2) (i.e., we have effectively gone from b to square root of b)
- In chess go from b ~ 35 to b ~ 6
- permitting much deeper search in the same amount of time
- In practice it is often b(2d/3)
Question 18 |
Consider the statement below.
A person who is radical (R) is electable (E) if he/she is conservative (C), but otherwise is not electable.
Few probable logical assertions of the above sentence are given below.,
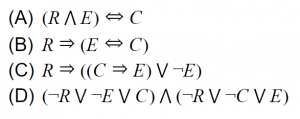
Which of the above logical assertions are true?
Choose the correct answer from the options given below:
Which of the above logical assertions are true?
Choose the correct answer from the options given below:
(B) only | |
(C) only | |
(A) and (C) only | |
(B) and (D) only |
Question 18 Explanation:
1. (R ∧E) ↔C
This is not equivalent. It says that all (and only) conservatives are radical and electable.
2. R →(E ↔C)
This one is equivalent. if a person is a radical then they are electable if and only if they are conservative.
3. R →((C →E) ∨¬E)
This one is vacuous. It’s equivalent to ¬R ∨ (¬C ∨ E ∨ ¬E), which is true in all interpretations.
4.R ⇒ (E ⇐⇒ C) ≡ R ⇒ ((E ⇒ C) ∧ (C ⇒ E))
≡ ¬R ∨ ((¬E ∨ C) ∧ (¬C ∨ E))
≡ (¬R ∨ ¬E ∨ C) ∧ (¬R ∨ ¬C ∨ E))
This is not equivalent. It says that all (and only) conservatives are radical and electable.
2. R →(E ↔C)
This one is equivalent. if a person is a radical then they are electable if and only if they are conservative.
3. R →((C →E) ∨¬E)
This one is vacuous. It’s equivalent to ¬R ∨ (¬C ∨ E ∨ ¬E), which is true in all interpretations.
4.R ⇒ (E ⇐⇒ C) ≡ R ⇒ ((E ⇒ C) ∧ (C ⇒ E))
≡ ¬R ∨ ((¬E ∨ C) ∧ (¬C ∨ E))
≡ (¬R ∨ ¬E ∨ C) ∧ (¬R ∨ ¬C ∨ E))
Question 19 |
Consider the following argument with premise

This is a valid argument. | |
Steps (C) and (E) are not correct inferences | |
Steps (D) and (F) are not correct inferences | |
Step (G) is not a correct inference |
Question 20 |
Given below are two statements:
Statement I: A genetic algorithm is a stochastic hill climbing search in which a large population of states is maintained.
Statement II: In a nondeterministic environment, agents can apply AND-OR search to generate containing plans that reach the goal regardless of which outcomes occur during execution.
In the light of the above statements, choose the correct answers from the options given below
Both Statement I and Statement II are true | |
Both Statement I and Statement II are false | |
Statement I is correct but Statement II is false
| |
Statement I is incorrect but Statement II is true |
Question 20 Explanation:
In a genetic algorithm, a population of candidate solutions (called individuals, creatures, or phenotypes) to an optimization problem is evolved toward better solutions. Each candidate solution has a set of properties (its chromosomes or genotype) which can be mutated and altered; traditionally, solutions are represented in binary as strings of 0s and 1s, but other encodings are also possible.
In nondeterministic environments, percepts tell the agent which of the possible outcomes has actually occurred.Solutions for nondeterministic problems can contain nested if-then-else statements that create a tree rather than a sequence of actions
In nondeterministic environments, percepts tell the agent which of the possible outcomes has actually occurred.Solutions for nondeterministic problems can contain nested if-then-else statements that create a tree rather than a sequence of actions
Question 21 |
Which of the following statements are true?
A) Minimax search is breadth-first; it processes all the nodes at a level before moving to a node in the next level.
B) The effectiveness of the alpha-beta pruning is highly dependent on the order in which the states are examined.
C) The alpha-beta search algorithm computes the same optimal moves as the minimax algorithm.
D) Optimal play in games of imperfect information does not require reasoning about the current and future belief states of each player.
Choose the correct answer from the options given below:
(A) and (C) only | |
(A) and (D) only | |
(B) and (C) only | |
(C) and (D) only |
Question 21 Explanation:
Minimax is a decision rule used in artificial intelligence, decision theory, game theory, statistics, and philosophy for minimizing the possible loss for a worst case (maximum loss) scenario.
Optimal decision in deterministic, perfect information games
Idea : choose the move resulting in the highest minimax value
Completeness: Yes if the tree is finite
Optimality: Yes, against an optimal opponent.
Time Complexity: O(bm)
Space Complexity: O(bm) – depth first exploration.
Hence Statement (A) is true.
Statement (B):
Alpha Bound of J:
→ The max current The max current val of all MAX ancestors of J of all MAX ancestors of J
→ Exploration of a min node, J, Exploration of a min node, J, is stopped when its value is stopped when its value equals or falls below alpha. equals or falls below alpha.
→ In a min node, we n node, we update beta update beta
Beta Bound of J:
→ The min current The min current val of all MIN ancestors of J of all MIN ancestors of J
→ Exploration of a Exploration of a max node, J ax node, J, is stopped when its stopped when its value equals or exceeds beta equals or exceeds beta
→ In a max node, we update a ax node, we update alpha
Pruning does not affect the final result
Does ordering affect the pruning process?
Best case O(bm/2)
Random (instead of best first search) - O(b3m/4)
Hence statement (B) is false.
Statement C: This statement is true.
Statement D: This statement is false because past exploration information is used from transposition tables.
Optimal decision in deterministic, perfect information games
Idea : choose the move resulting in the highest minimax value
Completeness: Yes if the tree is finite
Optimality: Yes, against an optimal opponent.
Time Complexity: O(bm)
Space Complexity: O(bm) – depth first exploration.
Hence Statement (A) is true.
Statement (B):
Alpha Bound of J:
→ The max current The max current val of all MAX ancestors of J of all MAX ancestors of J
→ Exploration of a min node, J, Exploration of a min node, J, is stopped when its value is stopped when its value equals or falls below alpha. equals or falls below alpha.
→ In a min node, we n node, we update beta update beta
Beta Bound of J:
→ The min current The min current val of all MIN ancestors of J of all MIN ancestors of J
→ Exploration of a Exploration of a max node, J ax node, J, is stopped when its stopped when its value equals or exceeds beta equals or exceeds beta
→ In a max node, we update a ax node, we update alpha
Pruning does not affect the final result
Does ordering affect the pruning process?
Best case O(bm/2)
Random (instead of best first search) - O(b3m/4)
Hence statement (B) is false.
Statement C: This statement is true.
Statement D: This statement is false because past exploration information is used from transposition tables.
Question 22 |
Which of the following statements are true?
A) A sentence ∝ entails another sentence ß if ß is true in few words where is true.
B) Forward chaining and backward chaining are very natural reasoning algorithms for knowledge bases in Horn form.
C) Sound inference algorithms derive all sentences that are entailed.
D) Propositional logic does not scale to environments of unbounded size.
Choose the correct answer from the options given below:
(A) and (B) only
| |
(B) and (C) only | |
(C) and (D) only | |
(B) and (D) only |
Question 22 Explanation:
Statement A is false : The relationship of entailment between sentence is crucial to our understanding of reasoning. A sentence α entails another sentence β if β is true in all world where α is true. Equivalent definitions include the validity of the sentence α⇒β and the unsatisfiability of sentence α∧¬β.
Statement D is false:Propositional logic does not scale to environments of unbounded size because it lacks the expressive power to deal concisely with time, space and universal patterns of relationships among objects.
Statement B is true:
Refer the below link:
https://www.iiia.csic.es/~puyol/IAGA/Teoria/07-AgentsLogicsII.pdf Statement C is true:
Sound/truth preserving: An inference algorithm that derives only entailed sentences. Soundness is a highly desirable property. (e.g. model checking is a sound procedure when it is applicable.)
Statement D is false:Propositional logic does not scale to environments of unbounded size because it lacks the expressive power to deal concisely with time, space and universal patterns of relationships among objects.
Statement B is true:
Refer the below link:
https://www.iiia.csic.es/~puyol/IAGA/Teoria/07-AgentsLogicsII.pdf Statement C is true:
Sound/truth preserving: An inference algorithm that derives only entailed sentences. Soundness is a highly desirable property. (e.g. model checking is a sound procedure when it is applicable.)
Question 23 |
Given below are two statements:
If two variables V1and V2 are used for clustering, then consider the following statements for k means clustering with k=3:-
Statement I: If V1and V2 have correlation of 1 the cluster centroid will be in straight line.
Statement II: If V1and V2 have correlation of 0 the cluster centroid will be in straight line.
In the light of the above statements, choose the correct answer from the options given below
Both Statement I and Statement II are true | |
Both Statement I and Statement II are false | |
Statement I is correct but Statement II is false | |
Statement I is incorrect but Statement II is true |
Question 23 Explanation:
If the correlation between the variables V1 and V2 is 1, then all the data points will be in a straight line. So, all the three cluster centroids will form a straight line as well.
Question 24 |
Which of the following pairs of propositions are not logically equivalent?
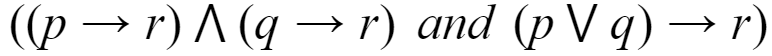 | |
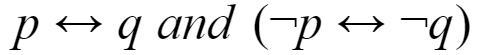 | |
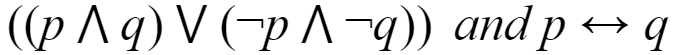 | |
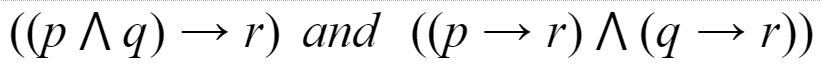 |
Question 24 Explanation:
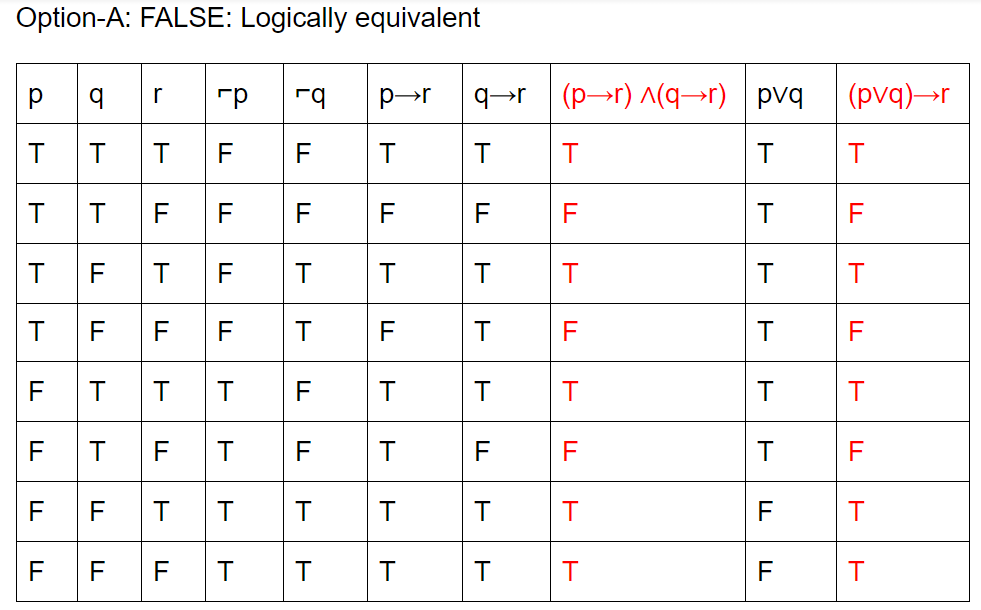
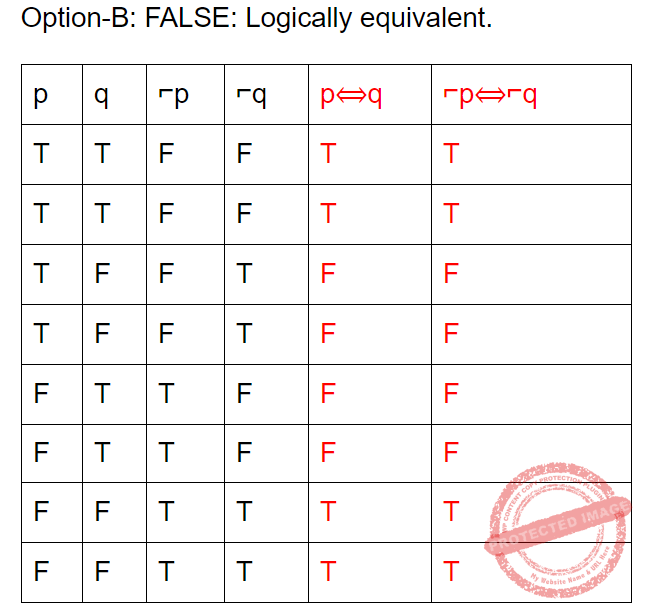
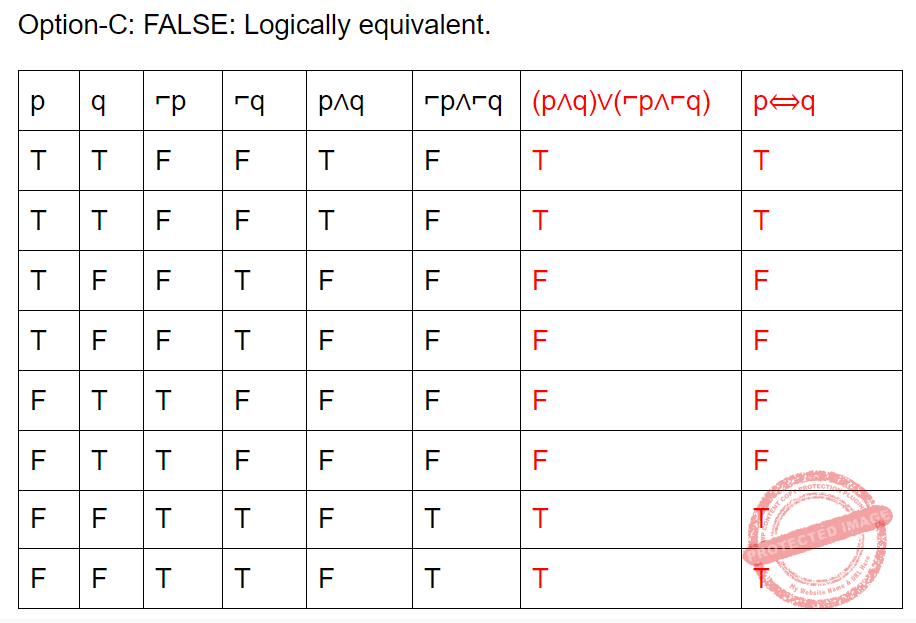
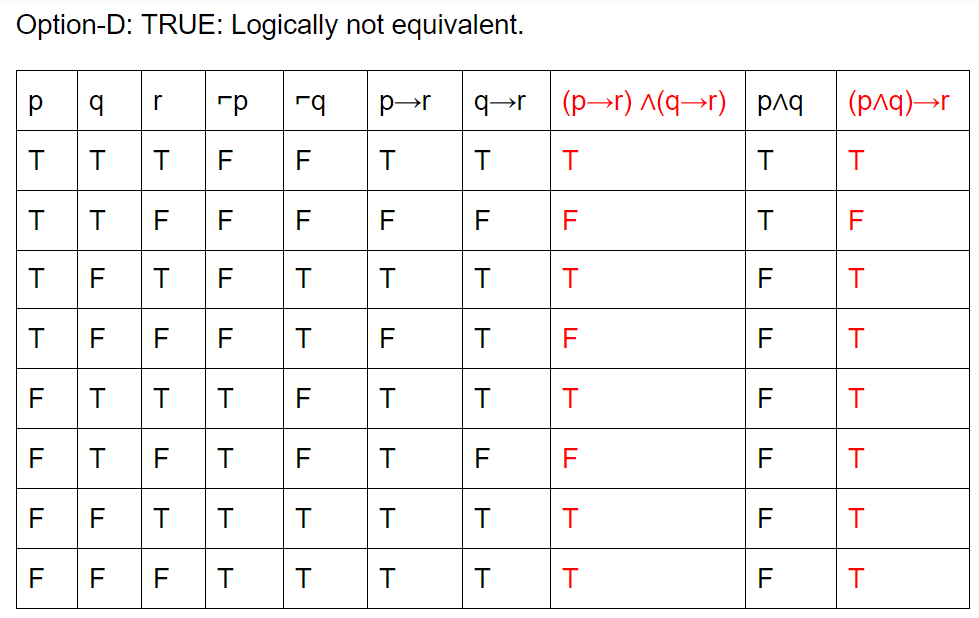
Question 25 |
Match List I with List II

Choose the correct answer from the options given below
Choose the correct answer from the options given below
A-II, B-IV, C-I, D-III
| |
A-II, B-III, C-I, D-IV | |
A-III, B-II, C-IV, D-I | |
A-III, B-IV, C-II, D-I |
Question 25 Explanation:
Greedy best-first search algorithm always selects the path which appears best at that moment. It is the combination of depth-first search and breadth-first search algorithms.
Time Complexity: The worst case time complexity of Greedy best first search is O(bm).
Space Complexity: The worst case space complexity of Greedy best first search is O(bm). Where, m is the maximum depth of the search space.
Complete: Greedy best-first search is also incomplete, even if the given state space is finite.
Optimal: Greedy best first search algorithm is not optimal.
Note:Refer the corresponding algorithms from standard sources.
Time Complexity: The worst case time complexity of Greedy best first search is O(bm).
Space Complexity: The worst case space complexity of Greedy best first search is O(bm). Where, m is the maximum depth of the search space.
Complete: Greedy best-first search is also incomplete, even if the given state space is finite.
Optimal: Greedy best first search algorithm is not optimal.
Note:Refer the corresponding algorithms from standard sources.
Question 26 |
If f(x)=x is my friend, and p(x) = x is perfect, then the correct logical translation of the statement "some of my friends are not perfect" is _____.
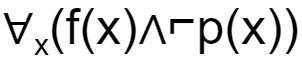 | |
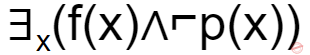 | |
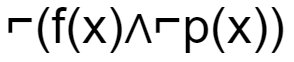 | |
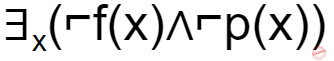 |
Question 26 Explanation:
Input:
f(x)=x is my friend
p(x) = x is perfect
So, they are asking about SOME. Finally, outer most parentheses will get SOME.
So, based on this we will eliminate 2 options.
They are given conditions like NOT perfect. So, we get ⌐p(x).
The final condition is ∃x(f(x)∧⌐p(x))
f(x)=x is my friend
p(x) = x is perfect
So, they are asking about SOME. Finally, outer most parentheses will get SOME.
So, based on this we will eliminate 2 options.
They are given conditions like NOT perfect. So, we get ⌐p(x).
The final condition is ∃x(f(x)∧⌐p(x))
Question 27 |
Match List I with List II
List I List II
A) Branch-and-bound (I) Keeps track of all partial paths which can be can be a candidate for further exploration.
B) Steepest-ascent hill climbing (II) Detects difference between current state and goal state.
C) Constraint satisfaction (III) Discovers problem state(s) that satisfy a set of constraints.
D) Means-end-analysis (IV) Considers all moves from current state and selects the best move.
Choose the correct answer from the options given below:
A-I, B-IV, C-III, D-II | |
A-I, B-II, C-III, D-IV
| |
A-II, B-I, C-III, D-IV | |
A-II, B-IV, C-III, D-I |
Question 27 Explanation:
Branch-and-bound→ Keep track of all partial paths which can be a candidate for further exploration.
Steepest-ascent hill climbing → Considers all moves from current state and selects the best move.
Constraint satisfaction → Discovers problem state(s) that satisfy a set of constraints.
Means-end-analysis → Detects difference between current state and goal state.
Steepest-ascent hill climbing → Considers all moves from current state and selects the best move.
Constraint satisfaction → Discovers problem state(s) that satisfy a set of constraints.
Means-end-analysis → Detects difference between current state and goal state.
Question 28 |
Which of the following is NOT true in problem solving in artificial intelligence?
Implements heuristic search techniques | |
Solution steps are not explicit | |
Knowledge is imprecise | |
it works on or implements repetition mechanism |
Question 29 |
Match the following :

a-i, b-ii, c-iii, d-iv | |
a-i, b-iii, c-iv, d-ii | |
a-ii, b-iii, c-iv, d-i | |
a-ii, b-ii, c-iii, d-iv |
Question 29 Explanation:
Absurd→ Clearly impossible being contrary to some evident truth.
Ambiguous→ Capable of more than one interpretation or meaning.
Axiom→ An assertion that is accepted and used without a proof.
Conjecture→ An opinion preferably based on some experience or wisdom
Ambiguous→ Capable of more than one interpretation or meaning.
Axiom→ An assertion that is accepted and used without a proof.
Conjecture→ An opinion preferably based on some experience or wisdom
Question 30 |
Match the following:

a-i, b-ii, c-iii, d-iv | |
a-i, b-iii, c-ii, d-iv | |
a-iii, b-ii, c-iv, d-i | |
a-ii, b-iii, c-i, d-iv |
Question 30 Explanation:
Affiliate Marketing: Vendors ask partners to place logos on partner’s site. If customers click, come to vendors and buy.
Viral Marketing: Spread your brand on the net by word-of-mouth. Receivers will send your information to their friends.
Group Purchasing: Aggregating the demands of small buyers to get a large volume. Then negotiate a price.
Bartering Online: Exchanging surplus products and services with the process administered completely online by an intermediary. Company receives “points” for its contribution.
Viral Marketing: Spread your brand on the net by word-of-mouth. Receivers will send your information to their friends.
Group Purchasing: Aggregating the demands of small buyers to get a large volume. Then negotiate a price.
Bartering Online: Exchanging surplus products and services with the process administered completely online by an intermediary. Company receives “points” for its contribution.
Question 31 |
Let P(m, n) be the statement “m divides n” where the Universe of discourse for both the variables is the set of positive integers. Determine the truth values of the following propositions.
(a)∃m ∀n P(m, n)
(b)∀n P(1, n)
(c) ∀m ∀n P(m, n)
(a)∃m ∀n P(m, n)
(b)∀n P(1, n)
(c) ∀m ∀n P(m, n)
(a) - True; (b) - True; (c) - False | |
(a) - True; (b) - False; (c) - False | |
(a) - False; (b) - False; (c) - False | |
(a) - True; (b) - True; (c) - True |
Question 31 Explanation:
Given P(m,n) ="m divides n"
Statement-A is ∃m ∀n P(m, n). Here, there exists some positive integer which divides every positive integer. It is true because there is positive integer 1 which divides every positive integer.
Statement-B is ∀n P(1, n). Here, 1 divided every positive integer. It is true.
Statement-C is ∀m ∀n P(m, n). Here, every positive integer divided every positive integer. It is false.
Statement-A is ∃m ∀n P(m, n). Here, there exists some positive integer which divides every positive integer. It is true because there is positive integer 1 which divides every positive integer.
Statement-B is ∀n P(1, n). Here, 1 divided every positive integer. It is true.
Statement-C is ∀m ∀n P(m, n). Here, every positive integer divided every positive integer. It is false.
Question 32 |
An agent can improve its performance by
Learning
| |
Responding
| |
Observing
| |
Perceiving
|
Question 32 Explanation:
→ An intelligent agent (IA) is an autonomous entity which observes through sensors and acts upon an environment using actuators (i.e. it is an agent) and directs its activity towards achieving goals (i.e. it is "rational", as defined in economics).
→ Intelligent agents may also learn or use knowledge to achieve their goals. They may be very simple or very complex. A reflex machine, such as a thermostat, is considered an example of an intelligent agent.
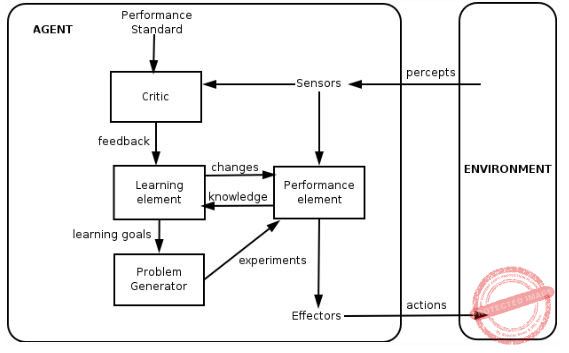
→ Intelligent agents may also learn or use knowledge to achieve their goals. They may be very simple or very complex. A reflex machine, such as a thermostat, is considered an example of an intelligent agent.
Question 33 |
In Challenge-Response authentication the claimant
Proves that she knows the secret without revealing it | |
Proves that she doesn’t know the secret | |
Reveals the secret
| |
Gives a challenge |
Question 33 Explanation:
→ Challenge-Response authentication is a family of protocols in which one party presents a question ("challenge") and another party must provide a valid answer ("response") to be authenticated.
→ The simplest example of a challenge–response protocol is password authentication, where the challenge is asking for the password and the valid response is the correct password.
→ A more interesting challenge–response technique works as follows. Say, Bob is controlling access to some resource. Alice comes along seeking entry. Bob issues a challenge, perhaps "52w72y". Alice must respond with the one string of characters which "fits" the challenge Bob issued. The "fit" is determined by an algorithm "known" to Bob and Alice. (The correct response might be as simple as "63x83z" (each character of response one more than that of challenge), but in the real world, the "rules" would be much more complex.) Bob issues a different challenge each time, and thus knowing a previous correct response (even if it isn't "hidden" by the means of communication used between Alice and Bob) is of no use.
→ The simplest example of a challenge–response protocol is password authentication, where the challenge is asking for the password and the valid response is the correct password.
→ A more interesting challenge–response technique works as follows. Say, Bob is controlling access to some resource. Alice comes along seeking entry. Bob issues a challenge, perhaps "52w72y". Alice must respond with the one string of characters which "fits" the challenge Bob issued. The "fit" is determined by an algorithm "known" to Bob and Alice. (The correct response might be as simple as "63x83z" (each character of response one more than that of challenge), but in the real world, the "rules" would be much more complex.) Bob issues a different challenge each time, and thus knowing a previous correct response (even if it isn't "hidden" by the means of communication used between Alice and Bob) is of no use.
Question 34 |
In Artificial Intelligence (AI), an environment is uncertain if it is
Not fully observable and not deterministic | |
Not fully observable or not deterministic | |
Fully observable but not deterministic
| |
Not fully observable but deterministic
|
Question 34 Explanation:
→ Deterministic AI environments are those on which the outcome can be determined based on a specific state. In other words, deterministic environments ignore uncertainty.
→ Most real world AI environments are not deterministic. Instead, they can be classified as stochastic. Self-driving vehicles are a classic example of stochastic AI processes.
→ Most real world AI environments are not deterministic. Instead, they can be classified as stochastic. Self-driving vehicles are a classic example of stochastic AI processes.
Question 35 |
In Artificial Intelligence (AI), a simple reflex agent selects actions on the basis of
current percept, completely ignoring rest of the percept history. | |
rest of the percept history, completely ignoring current percept. | |
both current percept and complete percept history.
| |
both current percept and just previous percept.
|
Question 35 Explanation:
→ Simple reflex agents act only on the basis of the current percept, ignoring the rest of the percept history. The agent function is based on the condition-action rule: "if condition, then action".
→ This agent function only succeeds when the environment is fully observable. Some reflex agents can also contain information on their current state which allows them to disregard conditions whose actuators are already triggered.
→ Infinite loops are often unavoidable for simple reflex agents operating in partially observable environments. Note: If the agent can randomize its actions, it may be possible to escape from infinite loops.
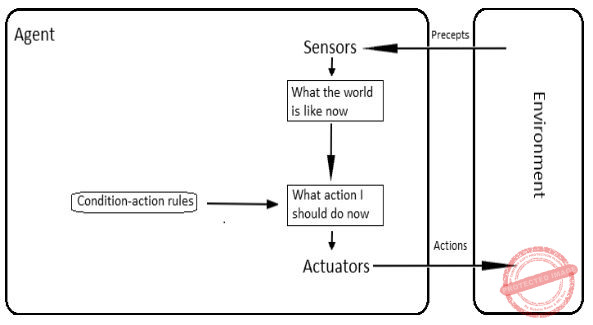
→ This agent function only succeeds when the environment is fully observable. Some reflex agents can also contain information on their current state which allows them to disregard conditions whose actuators are already triggered.
→ Infinite loops are often unavoidable for simple reflex agents operating in partially observable environments. Note: If the agent can randomize its actions, it may be possible to escape from infinite loops.
Question 36 |
In heuristic search algorithms in Artificial Intelligence (AI), if a collection of admissible heuristics h1.......hm is available for a problem and none of them dominates any of the others, which should we choose ?
h(n) = max{h1 (n), ...., hm(n)} | |
h(n) = min{h1(n), ...., hm(n)} | |
h(n) = avg{h1(n), ...., hm(n)} | |
h(n) = sum{h1(n), ...., hm(n)} |
Question 36 Explanation:
Heuristic Search Strategies:
A key component of an evaluation function is a heuristic function h(n), which estimates the cost of the cheapest path from node ‘n’ to a goal node.
→ In connection of a search problem “heuristics” refers to a certain (but loose) upper or lower bound for the cost of the best solution.
→ Goal states are nevertheless identified: in a corresponding node ‘n’ it is required that h(n)=0
E.g., a certain lower bound bringing no information would be to set h(n) ≅ 0
→ Heuristic functions are the most common form in which additional knowledge is imported to the search algorithm.
Generating admissible heuristics from relaxed problems:
→ To come up with heuristic functions one can study relaxed problems from which some restrictions of the original problem have been removed.
→ The cost of an optimal solution to a relaxed problem is an admissible heuristic for the original problem (does not overestimate).
→ The optimal solution in the original problem is, by definition, also a solution in the relaxed problem.
Example:
→ Heuristic h1 for the 8-puzzle gives perfectly accurate path length for a simplified version of the puzzle, where a tile can move anywhere.
→ Similarly h2 gives an optimal solution to a relaxed 8-puzzle, where tiles can move also to occupied squares.
→ If a collection of admissible heuristics is available for a problem, and none of them dominates any of the others, we can use the composite function.
h(n) = max { h1(n), …, hm(n) }
→ The composite function dominates all of its component functions and is consistent if none of the components overestimates. Reference:
http://www.cs.tut.fi/~elomaa/teach/AI-2011-3.pdf
A key component of an evaluation function is a heuristic function h(n), which estimates the cost of the cheapest path from node ‘n’ to a goal node.
→ In connection of a search problem “heuristics” refers to a certain (but loose) upper or lower bound for the cost of the best solution.
→ Goal states are nevertheless identified: in a corresponding node ‘n’ it is required that h(n)=0
E.g., a certain lower bound bringing no information would be to set h(n) ≅ 0
→ Heuristic functions are the most common form in which additional knowledge is imported to the search algorithm.
Generating admissible heuristics from relaxed problems:
→ To come up with heuristic functions one can study relaxed problems from which some restrictions of the original problem have been removed.
→ The cost of an optimal solution to a relaxed problem is an admissible heuristic for the original problem (does not overestimate).
→ The optimal solution in the original problem is, by definition, also a solution in the relaxed problem.
Example:
→ Heuristic h1 for the 8-puzzle gives perfectly accurate path length for a simplified version of the puzzle, where a tile can move anywhere.
→ Similarly h2 gives an optimal solution to a relaxed 8-puzzle, where tiles can move also to occupied squares.
→ If a collection of admissible heuristics is available for a problem, and none of them dominates any of the others, we can use the composite function.
h(n) = max { h1(n), …, hm(n) }
→ The composite function dominates all of its component functions and is consistent if none of the components overestimates. Reference:
http://www.cs.tut.fi/~elomaa/teach/AI-2011-3.pdf
Question 37 |
Consider following sentences regarding A*, an informed search strategy in Artificial Intelligence (AI).
- (a) A* expands all nodes with f(n)<C*.
(b) A* expands no nodes with f(n)/C*.
(c) Pruning is integral to A*.
Here, C* is the cost of the optimal solution path.
Both statement (a) and statement (b) are true. | |
Both statement (a) and statement (c) are true. | |
Both statement (b) and statement (c) are true. | |
All the statements (a), (b) and (c) are true.
|
Question 37 Explanation:
A* search:
→ A* combines the value of the heuristic function h(n)and the cost to reach the node ‘n’, g(n).
→ Evaluation function f(n) = g(n) + h(n) thus estimates the cost of the cheapest solution through ‘n’.
→ A* tries the node with the lowest f(n) value first.
→ This leads to both complete and optimal search algorithm, provided that h(n) satisfies certain conditions.
Optimality of A*:
→ A* expands all nodes ‘n’ for which f(n)
→ However, all nodes n for which f(n) > C* get pruned.
→ It is clear that A* search is complete.
→ A* search is also optimally efficient for any given heuristic function, because any algorithm that does not expand all nodes with f(n)
→ Despite being complete, optimal, and optimally efficient, A* search also has its weaknesses.
→ The number of nodes for which f(n)< C* for most problems is exponential in the length of the solution.
Reference:
http://www.cs.tut.fi/~elomaa/teach/AI-2011-3.pdf
→ A* combines the value of the heuristic function h(n)and the cost to reach the node ‘n’, g(n).
→ Evaluation function f(n) = g(n) + h(n) thus estimates the cost of the cheapest solution through ‘n’.
→ A* tries the node with the lowest f(n) value first.
→ This leads to both complete and optimal search algorithm, provided that h(n) satisfies certain conditions.
Optimality of A*:
→ A* expands all nodes ‘n’ for which f(n)
→ It is clear that A* search is complete.
→ A* search is also optimally efficient for any given heuristic function, because any algorithm that does not expand all nodes with f(n)
→ The number of nodes for which f(n)< C* for most problems is exponential in the length of the solution.
Reference:
http://www.cs.tut.fi/~elomaa/teach/AI-2011-3.pdf
Question 38 |
Self Organizing maps are___
A type of statistical tool for data analysis | |
A type of Artificial Swarm networks | |
A type of particle Swarm algorithm | |
None of the above |
Question 38 Explanation:
A self-organizing map or self-organizing feature map is a type of artificial neural network that is trained using unsupervised learning to produce a low-dimensional, discretized representation of the input space of the training samples, called a map, and is therefore a method to do dimensionality reduction.
Self-organizing maps differ from other artificial neural networks as they apply competitive learning as opposed to error-correction learning (such as backpropagation with gradient descent), and in the sense that they use a neighborhood function to preserve the topological properties of the input space.
Question 39 |
Hopfield networks are a type of__
Gigabit network | |
Terabyte network | |
Artificial Neural network | |
Wireless network |
Question 39 Explanation:
A Hopfield neural network is a type of artificial neural network invented by John Hopfield in 1982. It usually works by first learning a number of binary patterns and then returning the one
that is the most similar to a given input.
What defines a Hopfield network:
It is composed of only one layer of nodes or units each of which is connected to all the others but not itself. It is therefore a feedback network, which means that its outputs are redirected to its inputs. Every unit also acts as an input and an output of the network. Thus the number of nodes, inputs, outputs of the network are equal. Additionally, each one of the neurons in a has a binary state or activation value, usually represented as 1 or -1, which is its
particular output. The state of each node generally converges, meaning that the state of each node becomes fixed after a certain number of updates.
Question 40 |
Sigmoidal feedforward artificial neural networks with one hidden layer can / are ___
Approximation any continuous function | |
Approximation any disContinuous function | |
Approximation any continuous function and its derivatives of arbitrary order. | |
Exact modeling technique |
Question 40 Explanation:
Multilayer perceptron class of networks consists of multiple layers of computational units, usually interconnected in a feed-forward way. Each neuron in one layer has directed connections to the neurons of the subsequent layer. In many applications the units of these networks apply a sigmoid function as an activation function.
A feedforward neural network is an artificial neural network wherein connections between the nodes do not form a cycle. As such, it is different from recurrent neural networks. The feedforward neural network was the first and simplest type of artificial neural network devised. In this network, the information moves in only one direction, forward, from the input nodes, through the hidden nodes (if any) and to the output nodes. There are no cycles or loops in the network.
A feedforward neural network is an artificial neural network wherein connections between the nodes do not form a cycle. As such, it is different from recurrent neural networks. The feedforward neural network was the first and simplest type of artificial neural network devised. In this network, the information moves in only one direction, forward, from the input nodes, through the hidden nodes (if any) and to the output nodes. There are no cycles or loops in the network.
Question 41 |
Consider the results of a medical experiment that aims to predict whether someone is going to develop myopia based on some physical measurements and heredity. In this case, the input dataset consists of the person’s medical characteristics and the target variable is binary: 1 for those who are likely to develop myopia and 0 for those who aren’t. This can be best classified as
Regression | |
Decision Tree | |
Clustering | |
Association Rules |
Question 41 Explanation:
Regression: It is a statistical analysis which is used to establish relation between a response and a predictor variable. It is mainly used in finance related applications.
Decision Tree: Decision tree is a computational method which works on descriptive data and records the observations of each object to reach to a result.
Clustering: It is a method of grouping more similar objects in a group and the non-similar objects to other groups.
Association Rules: It uses if-then reasoning method using the support-confidence technique to give a result.
According to the question Decision Tree is the most suitable technique that can be used to get best result of the experiment.
Decision Tree: Decision tree is a computational method which works on descriptive data and records the observations of each object to reach to a result.
Clustering: It is a method of grouping more similar objects in a group and the non-similar objects to other groups.
Association Rules: It uses if-then reasoning method using the support-confidence technique to give a result.
According to the question Decision Tree is the most suitable technique that can be used to get best result of the experiment.
Question 42 |
In neural network, the network capacity is defined as
The traffic carry capacity of the network | |
The total number of nodes in the network | |
The number of patterns that can be stored and recalled in a network | |
None of the above |
Question 42 Explanation:
In neural network, the network capacity is defined as the number of patterns that can be stored and recalled in a network
Question 43 |
Consider the following:
(a) Evolution
(b) Selection
(c) reproduction
(d) Mutation
Which of the following are found in genetic algorithms?
(a) Evolution
(b) Selection
(c) reproduction
(d) Mutation
Which of the following are found in genetic algorithms?
(b),(c) and (d) only | |
(b) and (d) only | |
(a),(b),(c) and (d) | |
(a),(b) and (d) only |
Question 43 Explanation:
Five phases are considered in a genetic algorithm.
1.Initial population
2.Fitness function
3.Selection
4.Crossover
5.Mutation Note: According to official key option-C is correct.
1.Initial population
2.Fitness function
3.Selection
4.Crossover
5.Mutation Note: According to official key option-C is correct.
Question 44 |
Which of the following is an example of unsupervised neural network?
Back propagation network | |
Hebb network | |
Associative memory network
| |
Self-organizing feature map |
Question 44 Explanation:
A self-organizing map (SOM) or self-organizing feature map (SOFM) is a type of artificial neural network (ANN) that is trained using unsupervised learning to produce a low-dimensional (typically two-dimensional), discretized representation of the input space of the training samples, called a map, and is therefore a method to do dimensionality reduction. Self-organizing maps differ from other artificial neural networks as they apply competitive learning as opposed to error-correction learning (such as backpropagation with gradient descent), and in the sense that they use a neighborhood function to preserve the topological properties of the input space.
Question 45 |
The STRIPS representation is
a feature-centric representation | |
an action-centric representation | |
a combination of feature-centric and action-centric representation
| |
a hierarchical feature-centric representation |
Question 45 Explanation:
The STRIPS representation for an action consists of
→The precondition, which is a set of assignments of values to features that must be true for the action to occur, and
→The effect, which is a set of resulting assignments of values to those primitive features that change as the result of the action.
→The precondition, which is a set of assignments of values to features that must be true for the action to occur, and
→The effect, which is a set of resulting assignments of values to those primitive features that change as the result of the action.
Question 46 |
Given U={1,2,3,4,5,6,7}
A={(3,0.7),(5,1),(6,0.8)}
then ~A will be: (where ~ → complement)
{(4,0.7), (2,1), (1,0.8)} | |
{(4,0.3), (5,0), (6,0.2)} | |
{(1,1), (2,1), (3, 0.3), (4, 1), (6, 0.2), (7, 1)} | |
{(3, 0.3), (6.0.2)} |
Question 46 Explanation:

Question 47 |
Consider a fuzzy set old as defined below Old = {(20, 0.1), (30, 0.2), (40, 0.4), (50, 0.6), (60, 0.8), (70, 1), (80, 1)} Then the alpha-cut for alpha = 0.4 for the set old will be
{(40, 0.4)} | |
{50, 60, 70, 80} | |
{(20, 0.1), (30, 0.2)} | |
{(20, 0), (30, 0), (40, 1), (50, 1), (60, 1), (70, 1), (80, 1)} |
Question 47 Explanation:
If the membership of an element is greater than or equal to alpha-cut value then its membership will become one in the resultant set otherwise it’s membership will be zero(i.e. Will not be a member of the resulting set).
Here alpha = 0.4
So new set = {(20, 0), (30, 0), (40, 1), (50, 1), (60, 1), (70, 1), (80, 1)}
OR
{(40, 1), (50,1), (60.1), (70,1), (80,1)}
Here alpha = 0.4
So new set = {(20, 0), (30, 0), (40, 1), (50, 1), (60, 1), (70, 1), (80, 1)}
OR
{(40, 1), (50,1), (60.1), (70,1), (80,1)}
Question 48 |
Perceptron learning, Delta learning and LMS learning are learning methods which falls under the category of
Error correction learning – learning with a teacher | |
Reinforcement learning – learning with a critic | |
Hebbian learning | |
Competitive learning – learning without a teacher |
Question 49 |
Which one of the following describes the syntax of prolog program ?
I. Rules and facts are terminated by full stop (.)
II. Rules and facts are terminated by semicolon (;)
III. Variables names must start with upper case alphabets.
IV. Variables names must start with lower case alphabets.
I, II | |
III, IV | |
I, III | |
II, IV |
Question 49 Explanation:
Rules:

Question 50 |
Match the following:
List-I List-II
a. Expert systems i. Pragmatics
b. Planning ii. Resolution
c. Prolog iii. Means-end analysis
d. Natural language processing iv. Explanation facility
a-iii, b-iv, c-i, d-ii | |
a-iii, b-iv, c-ii, d-i | |
a-i, b-ii, c-iii, d-iv | |
a-iv, b-iii, c-ii, d-i |
Question 50 Explanation:
Expert systems → Explanation facility
Planning → Means-end analysis
Prolog → Resolution
Natural language processing → Pragmatics
Planning → Means-end analysis
Prolog → Resolution
Natural language processing → Pragmatics
There are 50 questions to complete.