Parsers
Question 1 |
S’ ⟶ S
S ⟶ S#cS
S ⟶ SS
S ⟶ S@
S ⟶ < S >
S ⟶ a
S ⟶ b
S ⟶ c
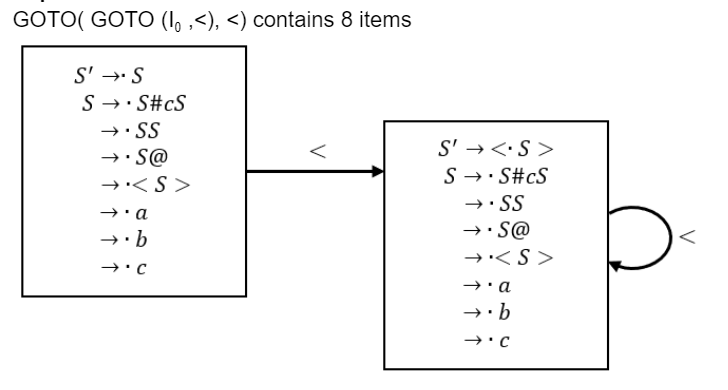
Let I0=CLOSURE({S' ⟶.S}). The number of items in the set GOTO(GOTO(I0, <), <) is ____________.
8 |
Question 2 |
A shift reduce parser carries out the actions specified within braces immediately after reducing with the corresponding rule of grammar
S → xxW {print "1"}
S → y {print "2"}
W → Sz {print "3"}
What is the translation of xxxxyzz using the syntax directed translation scheme described by the above rules?
23131 | |
11233 | |
11231 | |
33211 |
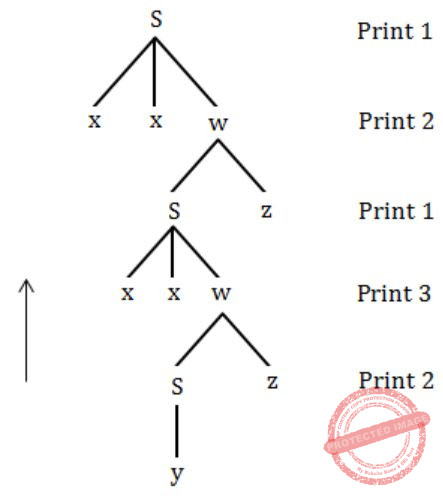
⇒ 23131
Note SR is bottom up parser.
Question 3 |
Consider the following grammar.
S → aSB|d
B → b
The number of reduction steps taken by a bottom-up parser while accepting the string aaadbbb is _______.
7 |
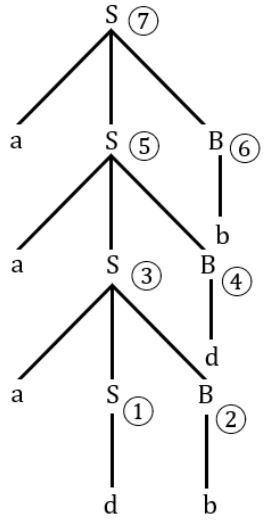
7 reductions total.
Question 4 |
Which of the following statements is true?
SLR parser is more powerful than LALR | |
LALR parser is more powerful than Canonical LR parser | |
Canonical LR parser is more powerful than LALR parser | |
The parsers SLR, Canonical CR, and LALR have the same power |
Canonical LR parser is more powerful than LALR parser.
Question 5 |
Which of the following is the most powerful parsing method?
LL (1) | |
Canonical LR | |
SLR | |
LALR |
LR > LALR > SLR
Question 6 |
Which of the following derivations does a top-down parser use while parsing an input string? The input is assumed to be scanned in left to right order.
Leftmost derivation | |
Leftmost derivation traced out in reverse | |
Rightmost derivation | |
Rightmost derivation traced out in reverse |
Bottom-Up parser - Reverse of rightmost derivation
Question 7 |
Which of the following statements is false?
An unambiguous grammar has same leftmost and rightmost derivation | |
An LL(1) parser is a top-down parser | |
LALR is more powerful than SLR | |
An ambiguous grammar can never be LR(k) for any k |
Option C: LALR is more powerful than SLR.
Option D: An ambiguous grammar can never be LR (k) for any k, because LR(k) algorithm aren’t designed to handle ambiguous grammars. It would get stuck into undecidability problem, if employed upon an ambiguous grammar, no matter how large the constant k is.
Question 8 |
Consider the following grammar with terminal alphabet ∑{a,(,),+,*} and start symbol E. The production rules of the grammar are:
E → aA
E → (E)
A → +E
A → *E
A → ε
(a) Compute the FIRST and FOLLOW sets for E and A.
(b) Complete the LL(1) parse table for the grammar.
Theory Explanation is given below. |
Question 9 |
Assume that the SLR parser for a grammar G has n1 states and the LALR parser for G has n2 states. The relationship between n1 and n2 is:
n1 is necessarily less than n2 | |
n1 is necessarily equal to n2
| |
n1 is necessarily greater than n2
| |
None of the above |
Question 10 |
Consider the grammar shown below
S → i E t S S' | a S' → e S | ε E → b
In the predictive parse table. M, of this grammar, the entries M[S', e] and M[S', $] respectively are
{S'→e S} and {S'→ε} | |
{S'→e S} and { } | |
{S'→ε} and {S'→ε} | |
{S'→e S, S'→ε} and {S'→ε} |
First(S') = {e,ε}
First(E) = {b}
Follow(S') = {e,$}
Only when 'First' contains ε, we need to consider FOLLOW for getting the parse table entry.
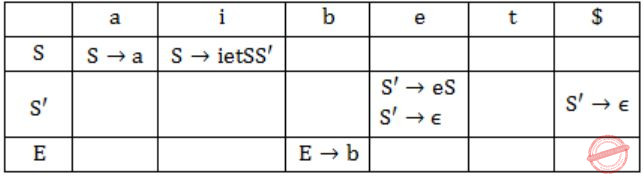
Hence, option (D) is correct.
Question 11 |
Consider the grammar shown below.
S → C C C → c C | d
The grammar is
LL(1) | |
SLR(1) but not LL(1)
| |
LALR(1) but not SLR(1) | |
LR(1) but not LALR(1)
|
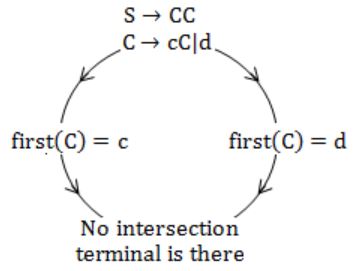
Hence, it is LL(1).
Question 12 |
Which of the following grammar rules violate the requirements of an operator grammar? P,Q,R are nonterminals, and r,s,t are terminals.
- (i) P → Q R
(ii) P → Q s R
(iii) P → ε
(iv) P → Q t R r
(i) only | |
(i) and (iii) only | |
(ii) and (iii) only | |
(iii) and (iv) only |
i) On RHS it contains two adjacent non-terminals.
ii) Have nullable values.
Question 13 |
The go to part of both tables may be different. | |
The shift entries are identical in both tables. | |
The reduce entries in the tables may be different. | |
The error entries in the tables may be different. |
Reduce entry and error entry may be different due to conflicts.
Question 14 |
The LALR (1) parser for a grammar G cannot have reduce-reduce conflict if the LR (1) parser for G does not have reduce-reduce conflict. | |
Symbol table is accessed only during the lexical analysis phase. | |
Data flow analysis is necessary for run-time memory management. | |
LR (1) parsing is sufficient for deterministic context-free languages. |
Symbol table is accessed in all the phases of compiler and not only in lexical analysis phase.
Data flow analysis is done in the control flow graph, in the code optimization phase. If LR(1) parses a grammar then definitely it is DCFL, so LR(1) parsing is sufficient for deterministic context-free languages.
Question 15 |

5 |
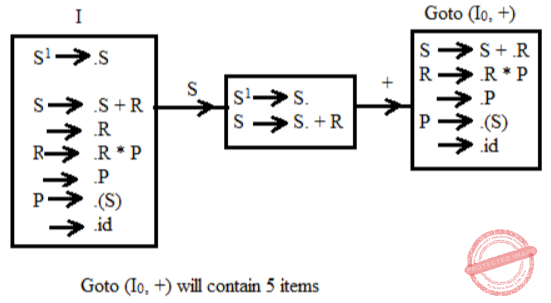
Question 16 |

80 |
Question 17 |
S1:Every SLR(1) grammar is unambiguous but there are certain unambiguous grammars that are not SLR(1).
S2: For any context-free grammar, there is a parser that takes at most O(n3 )
Which one of the following options is correct?
S1is true and S2is true
| |
S1is true and S2is false | |
S1is false and S2is true | |
S1is false and S2is false |
Every unambiguous grammar need not be SLR(1). As we know some unambiguous grammar which is CLR(1) but not SLR(1). So S1 is true.
Any CFG (which is in CNF form) can be parsed by CYK algorithm in O(n3) where n is length of string. Although it is not given that CFG is in CNF form but since we can convert any CFG in CNF form so S2 is true
Question 18 |
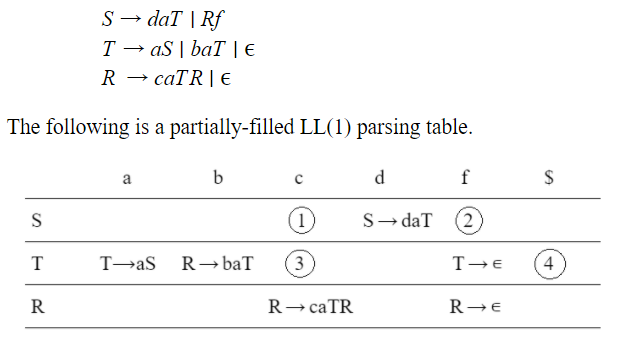
Which one of the following choices represents the correct combination for the numbered cells in the parsing table (“blank” denotes that the corresponding cell is empty)?
① S ⟶ Rf ② S ⟶ Rf ③ T ⟶ ∊ ④ T ⟶ ∊
| |
① blank ② S ⟶ Rf ③ T ⟶ ∊ ④ T ⟶ ∊ | |
① S ⟶ Rf ② blank ③ blank ④ T ⟶ ∊ | |
① blank ② S ⟶ Rf ③ blank ④ blank |

Question 19 |
An operator precedence parser is a
Bottom-up parser. | |
Top-down parser. | |
Back tracking parser. | |
None of the above. |
Question 20 |
Merging states with a common core may produce __________ conflicts and does not produce ___________ conflicts in an LALR purser.
Reduce-Reduce, Shift-Reduce |
Question 21 |
Choose the correct alternatives (more than one may be correct) and write the corresponding letters only: Indicate all the true statements from the following:
Recursive descent parsing cannot be used for grammar with left recursion. | |
The intermediate form the representing expressions which is best suited for code optimization is the post fix form. | |
A programming language not supporting either recursion or pointer type does not need the support of dynamic memory allocation. | |
Although C does not support call by name parameter passing, the effect can be correctly simulated in C.
| |
No feature of Pascal violates strong typing in Pascal. | |
A and D |
(B) False.
(C) It is false. The language can have dynamic data types which required dynamically growing memory when data type size increases.
(D) Is true and using macro we can do this.
(E) Out of syllabus now.
Question 22 |
The grammar A → AA | (A) | ε is not suitable for predictive-parsing because the grammar is:
ambiguous | |
left-recursive | |
right-recursive | |
an operator-grammar |
It have A → AA has left recursion.
Question 23 |
Consider the grammar:
S → (S) | a
Let the number of states in SLR(1), LR(1) and LALR(1) parsers for the grammar be n1, n2 and n3 respectively. The following relationship holds good:
n1 < n2 < n3 | |
n1 = n3 < n2 | |
n1 = n2 = n3 | |
n1 ≥ n3 ≥ n2 |
→ LR(1) be the states of LR(1) items.
→ LR(0) items never be greater than LR(1) items then SLR(1) = LALR(1) < LR(1)
n1 = (n3) < (n2)
Question 24 |
Consider the following expression grammar. The semantic rules for expression calculation are stated next to each grammar production.
E → number E.val = number. val
|E '+' E E(1).val = E(2).val + E>sup>(3).val
|E '×' E E(1).val = E(2).val × E(3).val
The above grammar and the semantic rules are fed to a yacc tool (which is an LALR(1) parser generator) for parsing and evaluating arithmetic expressions. Which one of the following is true about the action of yacc for the given grammar?
It detects recursion and eliminates recursion
| |
It detects reduce-reduce conflict, and resolves
| |
It detects shift-reduce conflict, and resolves the conflict in favor of a shift over a reduce action | |
It detects shift-reduce conflict, and resolves the conflict in favor of a reduce over a shift action
|
Question 25 |
Consider the following expression grammar. The semantic rules for expression calculation are stated next to each grammar production.
E → number E.val = number. val
|E '+' E E(1).val = E(2).val + E>sup>(3).val
|E '×' E E(1).val = E(2).val × E(3).val
Assume the conflicts in Part (a) of this question are resolved and an LALR(1) parser is generated for parsing arithmetic expressions as per the given grammar. Consider an expression 3 × 2 + 1. What precedence and associativity properties does the generated parser realize?
Equal precedence and left associativity; expression is evaluated to 7
| |
Equal precedence and right associativity; expression is evaluated to 9 | |
Precedence of '×' is higher than that of '+', and both operators are left associative; expression is evaluated to 7 | |
Precedence of '+' is higher than that of '×', and both operators are left associative; expression is evaluated to 9 |
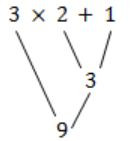
Hence, the answer is 9 and right associative.
Question 26 |
Which of the following statements about parser is/are CORRECT?
I. Canonical LR is more powerful than SLR.
II. SLR is more powerful than LALR.
III. SLR is more powerful than Canonical LR.
I only | |
II only | |
III only | |
II and III only |
The power in increasing order is:
LR(0) < SLR < LALR < CLR
Hence only I is true.
Question 27 |
Shift-reduce Parser
| |
Predictive Parser | |
LL(1) Parser | |
LR Parser |
Question 28 |
Which one of the following is True at any valid state in shift-reduce parsing?
Viable prefixes appear only at the bottom of the stack and not inside | |
Viable prefixes appear only at the top of the stack and not inside | |
The stack contains only a set of viable prefixes | |
The stack never contains viable prefixes |
A viable prefixes is prefix of the handle and so can never extend to the right of handle, i.e., top of stack.
So set of viable prefixes is in stack.
Question 29 |
S → Aa
A → BD
B → b | ε
D → d | ε
Let a, b, d and $ be indexed as follows:
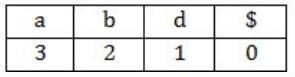
Compute the FOLLOW set of the non-terminal B and write the index values for the symbols in the FOLLOW set in the descending order. (For example, if the FOLLOW set is {a, b, d, $}, then the answer should be 3210)
30 | |
31 | |
10 | |
21 |
{Follow(B) = Follow(A) when D is epsilon}
Follow(B) = {d} Union {a} = {a,d}
Hence Answer is : 31
Question 30 |
Which one of the following kinds of derivation is used by LR parsers?
Leftmost in reverse | |
Rightmost in reverse | |
Leftmost | |
Rightmost |
Question 31 |
Consider the augmented grammar given below:
S' → S
S → 〈L〉 | id
L → L,S | S
Let I0 = CLOSURE ({[S' → ·S]}). The number of items in the set GOTO (I0 , 〈 ) is: _____.
4 | |
5 | |
6 | |
7 |

Hence, the set GOTO (I0 , 〈 ) has 5 items.