ISRO-2017 December
Question 1 |
Suppose A is a finite set with n elements. The number of elements and the rank of the largest equivalence relation on A is
{n,1} | |
{n, n} | |
{n2, 1} | |
{1, n2} |
Question 1 Explanation:
Let us assume a set with 4 elements
S={1,2,3,4}
→ If a set is said to be equivalence, then the set must be
i) Reflexive
ii) Symmetric
iii) Transitive
i) Reflexive Relation: A relation ‘R’ on a set ‘A’ is said to be reflexive if (xRx)∀x∈A.
A = {1,2,3}
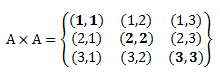
R = {(1,1), (2,2), (3,3)}
R = {(1,1), (2,2)} It is false.
R = {(1,1), (2,2), (3,3), (1,2)}
ii) Symmetric Relation: A relation on a set A is said to be symmetric if (xRy). Then (yRx)∀x,y∈A i.e., if ordered pair (x,y)∈R. Then (y,x)∈R ∀x,y∈A.
A={1,2,3}
R1={(1,2), (2,1)}
R2={(1,1), (2,2), (3,3), (1,2), (2,1), (2,3), (3,2)}
Transitive Relation:
A relation ‘R’ on a set ‘A’ is said to be transitive if (xRy) and (yRz), then (xRz)∀(x,y,z∈A).
A={1,2,3}
R1={ }
R2={(1,1)}
R3={(1,2), (3,1)}
R4={(1,2), (2,1), (1,1)}
⇾ A={1,2,3,4}
Largest ordered set is
S×S={(1,1),(1,2),(1,3),(1,4),(2,1),(2,2),(2,3),(2,4),(3,1),(3,2),(3,3),(3,4),(4,1),(4,2),(4,3),(4,4)}
⇒ Total = 16 = 42 = n2
Smallest ordered set = {(1,1),(2,2),(3,3),(4,4)}
⇒ Total=4=n
Note: In question, they are clearly mentioned that Rank of an Equivalence relation is equal to the number of induced Equivalence classes. Since we have maximum number of ordered pairs(which are reflexive, symmetric and transitive ) in largest Equivalence relation, its rank is always 1.
S={1,2,3,4}
→ If a set is said to be equivalence, then the set must be
i) Reflexive
ii) Symmetric
iii) Transitive
i) Reflexive Relation: A relation ‘R’ on a set ‘A’ is said to be reflexive if (xRx)∀x∈A.
A = {1,2,3}
R = {(1,1), (2,2), (3,3)}
R = {(1,1), (2,2)} It is false.
R = {(1,1), (2,2), (3,3), (1,2)}
ii) Symmetric Relation: A relation on a set A is said to be symmetric if (xRy). Then (yRx)∀x,y∈A i.e., if ordered pair (x,y)∈R. Then (y,x)∈R ∀x,y∈A.
A={1,2,3}
R1={(1,2), (2,1)}
R2={(1,1), (2,2), (3,3), (1,2), (2,1), (2,3), (3,2)}
Transitive Relation:
A relation ‘R’ on a set ‘A’ is said to be transitive if (xRy) and (yRz), then (xRz)∀(x,y,z∈A).
A={1,2,3}
R1={ }
R2={(1,1)}
R3={(1,2), (3,1)}
R4={(1,2), (2,1), (1,1)}
⇾ A={1,2,3,4}
Largest ordered set is
S×S={(1,1),(1,2),(1,3),(1,4),(2,1),(2,2),(2,3),(2,4),(3,1),(3,2),(3,3),(3,4),(4,1),(4,2),(4,3),(4,4)}
⇒ Total = 16 = 42 = n2
Smallest ordered set = {(1,1),(2,2),(3,3),(4,4)}
⇒ Total=4=n
Note: In question, they are clearly mentioned that Rank of an Equivalence relation is equal to the number of induced Equivalence classes. Since we have maximum number of ordered pairs(which are reflexive, symmetric and transitive ) in largest Equivalence relation, its rank is always 1.
Question 2 |
Consider the set of integers I. Let D denote “divides with an integer quotient” (e.g. 4D8 but 4D7). Then D is
Reflexive, not symmetric, transitive | |
Not reflexive, not antisymmetric, transitive | |
Reflexive, antisymmetric, transitive | |
Not reflexive, not antisymmetric, not transitive |
Question 2 Explanation:
Reflexive Relation:
A relation ‘R’ on a set ‘A’ is said to be reflexive if (xRx)∀x∈A.
Example: 4 D 8, 4 D 12, 4 D16, 4 D20…….(Here, D means divide)
8 D 16, 8 D 24……….
In this example, we didn’t get 4D4. So, it is not reflexive.
AntiSymmetric Relation:
For all x ∈ I, R(x,y) and R(y,x) then x=y is antisymmetric. We can easily make a violation as R(-2,2) and R(2,-2) are not antisymmetric.
It is violating. So, not antisymmetric relation.
Transitive relation:
A relation ‘R’ on a set ‘A’ is said to be transitive if (xRy) and (yRz), then (xRz)∀(x,y,z∈A).
Example: 4D8, 4D12, 4D16, 4D20…….(Here, D means divide)
8D16, 8D24……….
{ 4D8, 8D16, 1D16}. So, it is satisfied.
A relation ‘R’ on a set ‘A’ is said to be reflexive if (xRx)∀x∈A.
Example: 4 D 8, 4 D 12, 4 D16, 4 D20…….(Here, D means divide)
8 D 16, 8 D 24……….
In this example, we didn’t get 4D4. So, it is not reflexive.
AntiSymmetric Relation:
For all x ∈ I, R(x,y) and R(y,x) then x=y is antisymmetric. We can easily make a violation as R(-2,2) and R(2,-2) are not antisymmetric.
It is violating. So, not antisymmetric relation.
Transitive relation:
A relation ‘R’ on a set ‘A’ is said to be transitive if (xRy) and (yRz), then (xRz)∀(x,y,z∈A).
Example: 4D8, 4D12, 4D16, 4D20…….(Here, D means divide)
8D16, 8D24……….
{ 4D8, 8D16, 1D16}. So, it is satisfied.
Question 3 |
A bag contains 19 red balls and 19 black balls. Two balls are removed at a time repeatedly and discarded if they are of the same colour, but if they are different, black ball is discarded and red ball is returned to the bag. The probability that this process will terminate with one red ball is
1 | |
1/21 | |
0 | |
0.5 |
Question 3 Explanation:
Given data,
Step-1: Bag contains 19 Red(R) and 19 Blue(B) balls.
BB (or) RR happen we are discarded.
If we get BR (or) RB then B is discarded and R is returned.
Step-2: There are some conditions that,
→ If black balls will either come with black then both black balls are discarder.
→ If it will come with red then only black balls will be discarded.
→ Suppose 2 red balls will come together means we are discarding both red balls.
Step-3: As per the above constraints, total 19 Red balls it means odd number.
→ Among 19 only 18 will be discarded.
Step-3: Final content of bag at second last trail will be either R,B (or) R,R,R and finally in last
trail bag will left with one red ball in both the cases.
Step-1: Bag contains 19 Red(R) and 19 Blue(B) balls.
BB (or) RR happen we are discarded.
If we get BR (or) RB then B is discarded and R is returned.
Step-2: There are some conditions that,
→ If black balls will either come with black then both black balls are discarder.
→ If it will come with red then only black balls will be discarded.
→ Suppose 2 red balls will come together means we are discarding both red balls.
Step-3: As per the above constraints, total 19 Red balls it means odd number.
→ Among 19 only 18 will be discarded.
Step-3: Final content of bag at second last trail will be either R,B (or) R,R,R and finally in last
trail bag will left with one red ball in both the cases.
Question 4 |
If x = -1 and x = 2 are extreme points of f(x) = α log |x| + βx2 + x then
α = -6, β = -1/2 | |
α = 2, β = -1/2 | |
α = 2, β = 1/2 | |
α = -6, β =1/2 |
Question 4 Explanation:
Given data,
Step-1: x= -1 and x=2
f(x) = α log |x| + β x2 + x
f'(x)= α/x + 2βx + 1 = 0
Step-2: for extreme points f'(x)=0
α/x + 2βx + 1=0
Step-3: For x= -1 then we will get α+2β= 1 → (i)
For x= 2: then we will get α+8β= 2 → (ii)
from (i) and (ii) we can get the value of α=2 and β= -1/2
Step-1: x= -1 and x=2
f(x) = α log |x| + β x2 + x
f'(x)= α/x + 2βx + 1 = 0
Step-2: for extreme points f'(x)=0
α/x + 2βx + 1=0
Step-3: For x= -1 then we will get α+2β= 1 → (i)
For x= 2: then we will get α+8β= 2 → (ii)
from (i) and (ii) we can get the value of α=2 and β= -1/2
Question 5 |
Let f(x) = log|x| and g(x) = sin x . If A is the range of f(g(x)) and B is the range of g(f(x)) then A ∩ B is
[-1, 0] | |
[-1, 0) | |
[-∞, 0] | |
[-∞,1] |
Question 5 Explanation:
Given data,
Step-1: f(x) = log|x| and given range is [-∞ to +∞]
g(x) = sin(x) and given range is [-1,1]
Step-2: Given 2 variables are A and B
A= f(g(x))
= log|g(x)|
= log|sin(x)|
So, we will get A range is [-∞ ,0]
Step-3: B= g(f(x))
= sin(f(x))
= sin(log|x|)
So, we will get B range is [-1, 1]
Step-4: Common in both A and B is A∩B
A∩B = [-1, 0]
Key point: Ranges [ -1 ≤ sin(x) ≤ 1 and -∞ ≤ log|x| ≤ ∞ ]
Step-1: f(x) = log|x| and given range is [-∞ to +∞]
g(x) = sin(x) and given range is [-1,1]
Step-2: Given 2 variables are A and B
A= f(g(x))
= log|g(x)|
= log|sin(x)|
So, we will get A range is [-∞ ,0]
Step-3: B= g(f(x))
= sin(f(x))
= sin(log|x|)
So, we will get B range is [-1, 1]
Step-4: Common in both A and B is A∩B
A∩B = [-1, 0]
Key point: Ranges [ -1 ≤ sin(x) ≤ 1 and -∞ ≤ log|x| ≤ ∞ ]
There are 5 questions to complete.