Nielit Scientist-B CS 2016 march
Question 1 |
Which of the following logic expression is incorrect?
1 ⊕ 0=1 | |
1 ⊕ 1 ⊕ 0=1 | |
1 ⊕ 1 ⊕ 1=1 | |
1 ⊕ 1 =0 |
Question 1 Explanation:
This ⊕ symbol is nothing but Ex-OR
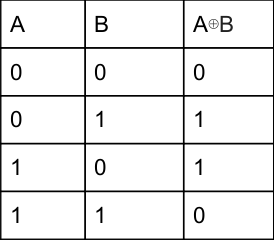
Option A: Here, 1 ⊕ 0=1 true according to truth table.
Option B: 1⊕1=0⊕0=0 false
Option C: 1 ⊕ 1=0 ⊕ 1=1 true
Option D: 1 ⊕ 1 =0 true.
Option A: Here, 1 ⊕ 0=1 true according to truth table.
Option B: 1⊕1=0⊕0=0 false
Option C: 1 ⊕ 1=0 ⊕ 1=1 true
Option D: 1 ⊕ 1 =0 true.
Question 2 |
In which of the following adder circuits, the carry look ripple delay is eliminated?
Half Adder | |
Full Adder | |
Parallel adder | |
Carry-Look-Ahead adder |
Question 2 Explanation:
A carry-lookahead adder (CLA) or fast adder is a type of adder used in digital logic. A carry-lookahead adder improves speed by reducing the amount of time required to determine carry bits. It can be contrasted with the simpler, but usually slower, ripple-carry adder (RCA), for which the carry bit is calculated alongside the sum bit, and each bit must wait until the previous carry bit have been calculated to begin calculating its own result and carry bits. The carry-lookahead adder calculates one or more carry bits before the sum, which reduces the wait time to calculate the result of the larger-value bits of the adder.
Question 3 |
The output of a sequential circuit depends on
presents inputs only | |
past inputs only | |
both present and past inputs | |
present outputs only |
Question 3 Explanation:
In digital circuit theory, sequential logic is a type of logic circuit whose output depends not only on the present value of its input signals but on the sequence of past inputs, the input history as well. This is in contrast to combinational logic, whose output is a function of only the present input.
Question 4 |
In a ripple counter using edge triggered JK flip-flops, the pulse input is applied to the
clock input of all flip-flops | |
clock input of one flip flops | |
J and K inputs of all flip flops | |
J and K inputs of one flip-flop |
Question 4 Explanation:
In a ripple counter using edge triggered JK flip-flops, the pulse input is applied to the clock input of one flip flops
Question 5 |
A decimal number has 30 digits. Approximately, how many digits would the binary representation have?
30 | |
60 | |
90 | |
120 |
Question 5 Explanation:
Here, 30 digits numbers means 123....30.
1030 -1=1000000000000000000000000000000-1=999999999999999999999999999999
Therefore, it takes approximately above 90 binary numbers. So, 120 is correct answer.
Therefore, it takes approximately above 90 binary numbers. So, 120 is correct answer.
Question 6 |
The result of the subtraction FD16 - 8816 is
75 16 | |
65 16 | |
5E 16 | |
10 16 |
Question 6 Explanation:
Step-1: Convert Hexadecimal numbers into decimal numbers.
(FD) 16</sub> = (253) 10
(88) 16</sub> = (136) 10
Step-2: Perform subtraction 253-136=(117) 10
Step-3: Convert (117) 10 =(75) 16
(FD) 16</sub> = (253) 10
(88) 16</sub> = (136) 10
Step-2: Perform subtraction 253-136=(117) 10
Step-3: Convert (117) 10 =(75) 16
Question 7 |
How many RAM chips of size (256K x 1 bit) are required to build 1M Byte memory?
8 | |
10 | |
24 | |
32 |
Question 7 Explanation:
1 MB = 1024 KB = (1024*8) bits
New RAM would be (1024*8) / (256*1) = 32 .
→ 32 RAM chips of size 256 k x 1 bit are required to build 1 MB of memory.
New RAM would be (1024*8) / (256*1) = 32 .
→ 32 RAM chips of size 256 k x 1 bit are required to build 1 MB of memory.
Question 8 |
When we move from the outermost track to the innermost track in a magnetic disk, then density(bits per linear inch)
increases | |
decreases | |
remains the same | |
either remains constant or decreases |
Question 8 Explanation:
→ we move from the outermost track to the innermost track in a magnetic disk, then density(bits per linear inch) increases
→ The density, in bits per linear inch, increases as we move from the outermost track to the innermost track (this same phenomenon is present in a phonograph record).
→ The density, in bits per linear inch, increases as we move from the outermost track to the innermost track (this same phenomenon is present in a phonograph record).
Question 9 |
A certain processor supports only the immediate and the direct addressing modes. Which of the following programming language features cannot be implemented on this processor?
Pointers | |
Arrays | |
Records | |
All of these |
Question 9 Explanation:
→ Pointer access requires indirect addressing which can be simulated with indexed addressing or register indirect addressing but not with direct and immediate addressing.
→ An array and record access needs a pointer access. So, options (A), (B) and (C) cannot be implemented on such a processor.
→ Now to handle recursive procedure we need to use stack. A local variable inside the stack will be accessed as *(SP+Offset) which is nothing but a pointer access and requires indirect addressing. Usually this is done by moving the SP value to the base register and then using base register addressing to avoid unnecessary memory access for indirect addressing but not possible with just direct and immediate addressing.
→ An array and record access needs a pointer access. So, options (A), (B) and (C) cannot be implemented on such a processor.
→ Now to handle recursive procedure we need to use stack. A local variable inside the stack will be accessed as *(SP+Offset) which is nothing but a pointer access and requires indirect addressing. Usually this is done by moving the SP value to the base register and then using base register addressing to avoid unnecessary memory access for indirect addressing but not possible with just direct and immediate addressing.
Question 10 |
Disadvantage of dynamic RAM over static RAM is
Higher power consumptions | |
Variable speed | |
need to refresh the capacitor charge every once in two milliseconds | |
higher bit density |
Question 10 Explanation:
→ Dynamic random access memory, implies, this form of memory technology is a type of random access memory. It stores each bit of data on a small capacitor within the memory cell. The capacitor can be either charged or discharged and this provides the two states, "1" or "0" for the cell.
→ Since the charge within the capacitor leaks, it is necessary to refresh each memory cell periodically. This refresh requirement gives rise to the term dynamic - static memories do not have a need to be refreshed.
→ Since the charge within the capacitor leaks, it is necessary to refresh each memory cell periodically. This refresh requirement gives rise to the term dynamic - static memories do not have a need to be refreshed.
Question 11 |
What is the correct way to round off x, a float. to an int value?
y=(int)(x+0.5) | |
y=int(x+0.5) | |
y=(int)x+0.5 | |
y=(int)(int) x+0.5) |
Question 11 Explanation:
Rounding off a value means replacing it by a nearest value that is approximately equal or smaller or greater to the given number.
y = (int)(x + 0.5); here x is any float value. To round off, we have to typecast the value of x by using (int)
Example:
#include
int main ()
{
float x = 3.6;
int y = (int)(x + 0.5);
printf ("Result = %d\n", y );
return 0;
}
Output:
Result = 4.
y = (int)(x + 0.5); here x is any float value. To round off, we have to typecast the value of x by using (int)
Example:
#include
int main ()
{
float x = 3.6;
int y = (int)(x + 0.5);
printf ("Result = %d\n", y );
return 0;
}
Output:
Result = 4.
Question 12 |
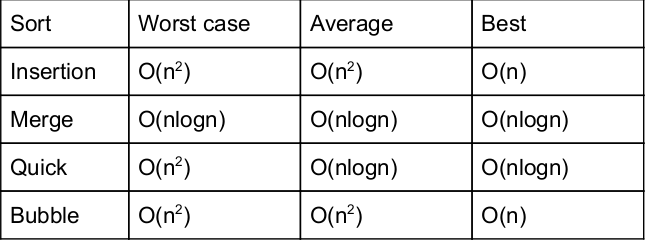
which of the following sorting algorithms does not have a worst case running time of O(n 2 )
Insertion sort | |
merge sort | |
Quick sort | |
bubble sort |
Question 12 Explanation:
Question 13 |
What error would the following function given on compilation?
f(int a, int b)
{
int a;
a=20;
return a;
}
f(int a, int b)
{
int a;
a=20;
return a;
}
Missing parenthesis is return statement | |
Function should be defined as int f(int a, int b) | |
Redeclaration of a | |
None of these |
Question 13 Explanation:
We are already declared variable name ‘a’ in function. Again we are declared inside the function. So, the compiler will raise a error “Redeclaration of a”
There are 13 questions to complete.