UGC NET CS 2013 Sep-paper-2
Question 1 |
A file is downloaded in a home computer using a 56 kbps MODEM connected to an Internet Service Provider. If the download of file completes in 2 minutes, what is the maximum size of data downloaded ?
112 Mbits | |
6.72 Mbits | |
67.20 Mbits | |
672 Mbits |
Question 1 Explanation:
Given data,
-- A file downloaded per second=56 kbps
-- If the file completes in 2 min then maximum size=?
Step-1: Convert minutes into seconds
Given 2 min= 2*60 sec
= 120 sec
Step-2: Downloaded speed per second= 56 kbps
= 56 kbps * 120 sec
= (56 * 1024 *120) / 1024
= 6720 Kbps
= 6.72 Mbits
-- A file downloaded per second=56 kbps
-- If the file completes in 2 min then maximum size=?
Step-1: Convert minutes into seconds
Given 2 min= 2*60 sec
= 120 sec
Step-2: Downloaded speed per second= 56 kbps
= 56 kbps * 120 sec
= (56 * 1024 *120) / 1024
= 6720 Kbps
= 6.72 Mbits
Question 2 |
In ______ CSMA protocol, after the station finds the line idle, it sends or refrains from sending based on the outcome of a random number generator.
Non-persistent | |
0-persistent | |
1-persistent | |
p-persistent |
Question 2 Explanation:
In p-persistent CSMA protocol, after the station finds the line idle, it sends or refrains from sending based on the outcome of a random number generator.
1-persistent: 1-persistent CSMA is an aggressive transmission algorithm. When the transmitting node is ready to transmit, it senses the transmission medium for idle or busy. If idle, then it transmits immediately. If busy, then it senses the transmission medium continuously until it becomes idle, then transmits the message (a frame) unconditionally (i.e. with probability=1). In case of a collision, the sender waits for a random period of time and attempts the same procedure again. 1-persistent CSMA is used in CSMA/CD systems including Ethernet.
Non-persistent: Non persistent CSMA is a non aggressive transmission algorithm. When the transmitting node is ready to transmit data, it senses the transmission medium for idle or busy. If idle, then it transmits immediately. If busy, then it waits for a random period of time (during which it does not sense the transmission medium) before repeating the whole logic cycle (which started with sensing the transmission medium for idle or busy) again. This approach reduces collision, results in overall higher medium throughput but with a penalty of longer initial delay compared to 1–persistent.
P-persistent: This is an approach between 1-persistent and non-persistent CSMA access modes. When the transmitting node is ready to transmit data, it senses the transmission medium for idle or busy. If idle, then it transmits immediately. If busy, then it senses the transmission medium continuously until it becomes idle, then transmits with probability p. If the node does not transmit (the probability of this event is 1-p), it waits until the next available time slot. If the transmission medium is not busy, it transmits again with the same probability p. This probabilistic hold-off repeats until the frame is finally transmitted or when the medium is found to become busy again (i.e. some other node has already started transmitting). In the latter case the node repeats the whole logic cycle (which started with sensing the transmission medium for idle or busy) again. p-persistent CSMA is used in CSMA/CA systems including Wi-Fi and other packet radio systems.
O-persistent: Each node is assigned a transmission order by a supervisory node. When the transmission medium goes idle, nodes wait for their time slot in accordance with their assigned transmission order. The node assigned to transmit first transmits immediately. The node assigned to transmit second waits one time slot (but by that time the first node has already started transmitting). Nodes monitor the medium for transmissions from other nodes and update their assigned order with each detected transmission (i.e. they move one position closer to the front of the queue). O-persistent CSMA is used by CobraNet, LonWorks and the controller area network.
1-persistent: 1-persistent CSMA is an aggressive transmission algorithm. When the transmitting node is ready to transmit, it senses the transmission medium for idle or busy. If idle, then it transmits immediately. If busy, then it senses the transmission medium continuously until it becomes idle, then transmits the message (a frame) unconditionally (i.e. with probability=1). In case of a collision, the sender waits for a random period of time and attempts the same procedure again. 1-persistent CSMA is used in CSMA/CD systems including Ethernet.
Non-persistent: Non persistent CSMA is a non aggressive transmission algorithm. When the transmitting node is ready to transmit data, it senses the transmission medium for idle or busy. If idle, then it transmits immediately. If busy, then it waits for a random period of time (during which it does not sense the transmission medium) before repeating the whole logic cycle (which started with sensing the transmission medium for idle or busy) again. This approach reduces collision, results in overall higher medium throughput but with a penalty of longer initial delay compared to 1–persistent.
P-persistent: This is an approach between 1-persistent and non-persistent CSMA access modes. When the transmitting node is ready to transmit data, it senses the transmission medium for idle or busy. If idle, then it transmits immediately. If busy, then it senses the transmission medium continuously until it becomes idle, then transmits with probability p. If the node does not transmit (the probability of this event is 1-p), it waits until the next available time slot. If the transmission medium is not busy, it transmits again with the same probability p. This probabilistic hold-off repeats until the frame is finally transmitted or when the medium is found to become busy again (i.e. some other node has already started transmitting). In the latter case the node repeats the whole logic cycle (which started with sensing the transmission medium for idle or busy) again. p-persistent CSMA is used in CSMA/CA systems including Wi-Fi and other packet radio systems.
O-persistent: Each node is assigned a transmission order by a supervisory node. When the transmission medium goes idle, nodes wait for their time slot in accordance with their assigned transmission order. The node assigned to transmit first transmits immediately. The node assigned to transmit second waits one time slot (but by that time the first node has already started transmitting). Nodes monitor the medium for transmissions from other nodes and update their assigned order with each detected transmission (i.e. they move one position closer to the front of the queue). O-persistent CSMA is used by CobraNet, LonWorks and the controller area network.
Question 3 |
Which of the following substitution technique have the relationship between a character in the plain text and a character in the ciphertext as one-to-many ?
Monoalphabetic | |
Polyalphabetic | |
Transpositional | |
None of the above |
Question 3 Explanation:
Monoalphabetic Substitution: The relationship between a character in the plaintext and a character in the ciphertext is always one-to-one
Polyalphabetic Substitution: This is an improvement over the Caesar cipher. In polyalphabetic substitution, each occurrence of a character may have a different substitute. Here the relationship between a character in the plaintext and a character in the ciphertext is always one-to-many.
Transposition Cipher: The transposition cipher, the characters remain unchanged but their positions are changed to create the ciphertext. A transposition cipher does not substitute one symbol for another, instead it changes the location of the symbols. A transposition cipher reorders symbols.
Polyalphabetic Substitution: This is an improvement over the Caesar cipher. In polyalphabetic substitution, each occurrence of a character may have a different substitute. Here the relationship between a character in the plaintext and a character in the ciphertext is always one-to-many.
Transposition Cipher: The transposition cipher, the characters remain unchanged but their positions are changed to create the ciphertext. A transposition cipher does not substitute one symbol for another, instead it changes the location of the symbols. A transposition cipher reorders symbols.
Question 4 |
What is the maximum length of CAT-5 UTP cable in Fast Ethernet network ?
100 meters | |
200 meters | |
1000 meters | |
2000 meters |
Question 4 Explanation:
→ CAT-5 UTP maximum length is 100 meters. CAT-5 is also used to carry other signals such as telephony and video.
→ CAT-5e provides performance of up to 100 MHz and is suitable for most varieties of Ethernet over twisted pair up to 1000BASE-T (Gigabit Ethernet).
→ CAT-5e provides performance of up to 100 MHz and is suitable for most varieties of Ethernet over twisted pair up to 1000BASE-T (Gigabit Ethernet).
Question 5 |
The ______ is a set of standards that defines how a dynamic web document should be written, how input data should be supplied to the program, and how the output result should be used.
Hyper Text Markup Language | |
File Transfer Protocol | |
Hypertext Transfer Protocol | |
Common Gateway Interface |
Question 5 Explanation:
Common Gateway Interface(CGI) is a set of standards that defines how a dynamic web document should be written, how input data should be supplied to the program, and how the output result should be used.
→ CGI is often used to process inputs information from the user and produce the appropriate output.
→ CGI is often used to process inputs information from the user and produce the appropriate output.
Question 6 |
The count-to-infinity problem is associated with
Flooding algorithm | |
Hierarchical routing algorithm | |
Distance vector routing algorithm | |
Link state routing algorithm |
Question 6 Explanation:
The count-to-infinity problem is associated with Distance vector routing algorithm.
Question 7 |
The IEEE single-precision and double-precision format to represent floating-point numbers, has a length of ______ and ______ respectively.
8 bits and 16 bits | |
16 bits and 32 bits | |
32 bits and 64 bits
| |
64 bits and 128 bits |
Question 7 Explanation:
The IEEE single-precision and double-precision format to represent floating-point numbers, has a length of 32 bits and 64 bits respectively.
Question 8 |
Consider an undirected graph G with 100 nodes. The maximum number of edges to be included in G so that the graph is not connected is
2451 | |
4950 | |
4851 | |
9900 |
Question 8 Explanation:
Given data,
-- Undirected graph G with 100 nodes.
-- Maximum number of edges to be included in G so that the graph is not connected is ?
Step-1: As per the above description, it is simple undirected graph.
For simple graph using formula standard formula is ((n-1)*(n-2))/2
Step-2: Here, n=100
n-1=99
n-2=98
=((n-1)(n-2))/2
= (99*98)/2
= 4851
Note: The simple graph won’t have parallel edges and self loops.
-- Undirected graph G with 100 nodes.
-- Maximum number of edges to be included in G so that the graph is not connected is ?
Step-1: As per the above description, it is simple undirected graph.
For simple graph using formula standard formula is ((n-1)*(n-2))/2
Step-2: Here, n=100
n-1=99
n-2=98
=((n-1)(n-2))/2
= (99*98)/2
= 4851
Note: The simple graph won’t have parallel edges and self loops.
Question 9 |
The amortized time complexity to perform ______ operation(s) in Splay trees is O(lg n).
Search | |
Search and Insert | |
Search and Delete | |
Search, Insert and Delete |
Question 9 Explanation:
→ Amortized analysis is a method for analyzing a given algorithm's complexity, or how much of a resource, especially time or memory, it takes to execute. The motivation for amortized analysis is that looking at the worst-case run time per operation, rather than per algorithm, can be too pessimistic.

Search (or) Find: For the Search (or) Find operation, we perform a normal BST find followed by a splay operation on the node found (or the leaf node last encountered, if the key was not found). We can charge the cost of going down the tree to the splay operation. Thus the amortized cost of find is O(log n).
Insert/delete: The amortized cost of the splay operation is also O(log n), and thus the amortized cost of insert/delete is O(log n).
Search (or) Find: For the Search (or) Find operation, we perform a normal BST find followed by a splay operation on the node found (or the leaf node last encountered, if the key was not found). We can charge the cost of going down the tree to the splay operation. Thus the amortized cost of find is O(log n).
Insert/delete: The amortized cost of the splay operation is also O(log n), and thus the amortized cost of insert/delete is O(log n).
Question 10 |
Suppose that the splits at every level of Quicksort are in proportion 1-β to β, where 0 < β ≤ 0.5 is a constant. The number of elements in an array is n. The maximum depth is approximately
0.5 β Ig n | |
0.5 (1 – β) Ig n | |
– (Ig n)/(Ig β) | |
– (Ig n)/Ig (1 – β) |
Question 11 |
The minimum number of nodes in a binary tree of depth d (root is at level 0) is
2d – 1 | |
2d + 1 – 1 | |
d + 1 | |
d |
Question 11 Explanation:
Binary tree is a tree where each node has at most 2 children nodes.
Properties:
→The number of nodes at depth d in a perfect binary tree = 2d
→A perfect binary tree of height h has 2h+1 -1 nodes
→Number of leaf nodes in a perfect binary tree of height h = 2h
→Number of internal nodes in a perfect binary tree of height h = 2h -1
→The minimum number of nodes in a binary tree of height h = h+1
→The maximum number of nodes in a binary tree of height h = 2h+1 -1
Properties:
→The number of nodes at depth d in a perfect binary tree = 2d
→A perfect binary tree of height h has 2h+1 -1 nodes
→Number of leaf nodes in a perfect binary tree of height h = 2h
→Number of internal nodes in a perfect binary tree of height h = 2h -1
→The minimum number of nodes in a binary tree of height h = h+1
→The maximum number of nodes in a binary tree of height h = 2h+1 -1
Question 12 |
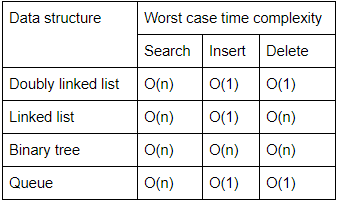
The efficient data structure to insert/delete a number in a stored set of numbers is
Queue | |
Linked list | |
Doubly linked list | |
Binary tree |
Question 12 Explanation:
Doubly linked list is the efficient data structure to insert/delete a number in a stored set of numbers.
There are 12 questions to complete.