UGC NET CS 2015 Dec - paper-3
Question 1 |
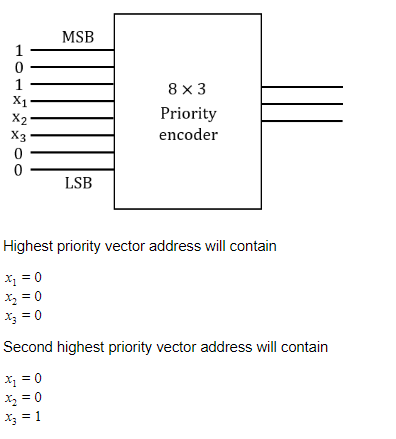
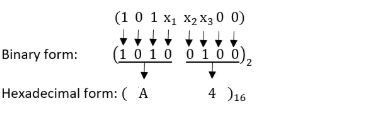
The three outputs x1x2x3 from the 8 X 3 priority encoder are used to provide a vector address of the form 101x1x2x300. What is the second highest priority vector address in hexadecimal if the vector addresses are starting from the one with the highest priority ?
BC | |
A4 | |
BD | |
AC |
Question 1 Explanation:
Question 2 |
What will be the output at PORT1 if the following program is executed ?
MVI B, 82H
MOV A, B
MOV C, A
MVI D, 37H
OUT PORT1
HLT
MVI B, 82H
MOV A, B
MOV C, A
MVI D, 37H
OUT PORT1
HLT
37H | |
82H | |
B9H | |
00H |
Question 2 Explanation:
MOV instruction copies the data from one location to other
MVI B, 82H / Copy value 82H to register B
MOV A, B / Copy value of B (82H) to accumulator A
MOV C, A / Copy value of accumulator A (82H) to register C
MVI D, 37H / Copy value 37H to register D
OUT PORT1 /Copy value of accumulator A (82H) to PORT 1 (because still accumulator A is having 82H)
MVI B, 82H / Copy value 82H to register B
MOV A, B / Copy value of B (82H) to accumulator A
MOV C, A / Copy value of accumulator A (82H) to register C
MVI D, 37H / Copy value 37H to register D
OUT PORT1 /Copy value of accumulator A (82H) to PORT 1 (because still accumulator A is having 82H)
Question 3 |
Which of the following 8085 microprocessor hardware interrupt has the lowest priority?
RST 6.5 | |
RST 7.5 | |
TRAP | |
INTR |
Question 3 Explanation:
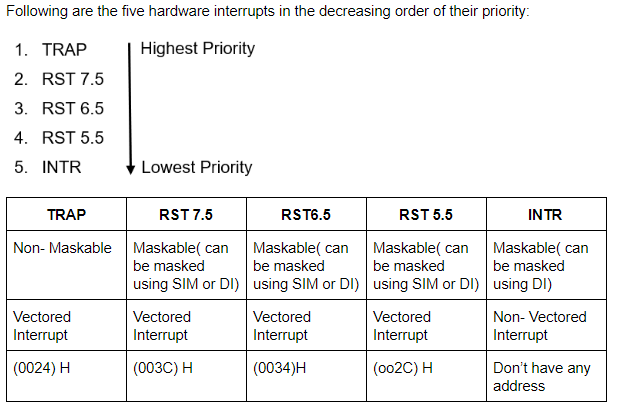
DI(Disable Interrupt): DI allows the microprocessor to reject the interrupt. In DI the interrupts are disabled immediately and no flags are affected.
SIM(Set Instruction Mask): It uses flags to disable the interrupts. Here “1” indicated that the interrupt is masked and “0” indicates the the instruction is not masked.
Question 4 |
A dynamic RAM has refresh cycle of 32 times per msec. Each refresh operation requires 100 nsec and a memory cycle requires 250 nsec. What percentage of memory’s total operating time is required for refreshes?
0.64 | |
0.96 | |
2.00 | |
0.32 |
Question 4 Explanation:

Question 5 |
A DMA controller transfers 32-bit words to memory using cycle stealing. The words are assembled from a device that transmits characters at a rate of 4800 characters per second. The CPU is fetching and executing instructions at an average rate of one million instructions per second. By how much will the CPU be slowed down because of the DMA transfer?
0.6% | |
0.12% | |
1.2% | |
2.5% |
Question 5 Explanation:
→ In one second, device is sending - 4800 characters to DMA
→ 1 character = 8 bits
→ So in one second, device is sending - (4800⨯8) bits to DMA
→ In one cycle, DMA sends - 32 bits.
→ To send (4800 ⨯ 8) bits DMA needs = (4800⨯8)/30 cycles = 1200 cycles
→ Now in one second CPU executes 106 instructions.
→ But because of cycle stealing, CPU has slow down and the % by which CPU gets slow down can be calculated as
= 1200/106 * 100
= 12/10000 * 100
=0.12%
→ 1 character = 8 bits
→ So in one second, device is sending - (4800⨯8) bits to DMA
→ In one cycle, DMA sends - 32 bits.
→ To send (4800 ⨯ 8) bits DMA needs = (4800⨯8)/30 cycles = 1200 cycles
→ Now in one second CPU executes 106 instructions.
→ But because of cycle stealing, CPU has slow down and the % by which CPU gets slow down can be calculated as
= 1200/106 * 100
= 12/10000 * 100
=0.12%
Question 6 |
A CPU handles interrupt by executing interrupt service subroutine __________.
by checking interrupt register after execution of each instruction | |
by checking interrupt register at the end of the fetch cycle | |
whenever an interrupt is registered | |
by checking interrupt register at regular time interval |
Question 6 Explanation:
CPU after completing the execution of a instruction checks the status of interrupt if there is a interrupt then CPU executes the interrupt service routine to service it else CPU stats executing next instruction.
Question 7 |
Given the following set of prolog clauses :
father(X, Y) :
parent(X, Y),
male(X),
parent(Sally, Bob),
parent(Jim, Bob),
parent(Alice, Jane),
parent(Thomas, Jane),
male(Bob),
male(Jim),
female(Salley),
female(Alice).
How many atoms are matched to the variable ‘X’ before the query father(X, Jane) reports a Result ?
father(X, Y) :
parent(X, Y),
male(X),
parent(Sally, Bob),
parent(Jim, Bob),
parent(Alice, Jane),
parent(Thomas, Jane),
male(Bob),
male(Jim),
female(Salley),
female(Alice).
How many atoms are matched to the variable ‘X’ before the query father(X, Jane) reports a Result ?
1 | |
2 | |
3 | |
4 | |
No option is correct. |
Question 7 Explanation:
Excluded for evaluation
Question 8 |
Forward chaining systems are __________ where as backward chaining systems are __________.
Data driven, Data driven | |
Goal driven, Data driven | |
Data driven, Goal driven | |
Goal driven, Goal driven |
Question 8 Explanation:
Forward Chaining: Forward chaining starts with the available data and uses inference rules to extract more data until a conclusion is reached.
It is also known as data driven inference technique.
It is bottom up reasoning.
It is a breadth first search.
For Example: “If it is raining then i will bring the umbrella”. Here “it is raining” is a available data from which more data is extracted and a conclusion “i will bring the umbrella” is drived.
Backward Chaining: Backward chaining is an inference method described colloquially as working backward from the goal.
It is also known as goal driven inference technique.
Here we starts from a goal and apply inference rules to get some data.
It is top down reasoning.
It is a depth first search.
For Example: “If it is raining then i will bring the umbrella”. Here our conclusion is “i will bring the umbrella”. Now If I am bringing an umbrella then it can be stated that it is raining that is why I am bringing the umbrella. So here “ It is raining” is the data obtained from goal . Hence it was derived in a backward direction so it is the process of backward chaining.
It is also known as data driven inference technique.
It is bottom up reasoning.
It is a breadth first search.
For Example: “If it is raining then i will bring the umbrella”. Here “it is raining” is a available data from which more data is extracted and a conclusion “i will bring the umbrella” is drived.
Backward Chaining: Backward chaining is an inference method described colloquially as working backward from the goal.
It is also known as goal driven inference technique.
Here we starts from a goal and apply inference rules to get some data.
It is top down reasoning.
It is a depth first search.
For Example: “If it is raining then i will bring the umbrella”. Here our conclusion is “i will bring the umbrella”. Now If I am bringing an umbrella then it can be stated that it is raining that is why I am bringing the umbrella. So here “ It is raining” is the data obtained from goal . Hence it was derived in a backward direction so it is the process of backward chaining.
Question 9 |
Match the following w.r.t. programming language:

(a)-(iii), (b)-(i), (c)-(ii), (d)-(iv) | |
(a)-(i), (b)-(iii), (c)-(ii), (d)-(iv) | |
(a)-(i), (b)-(iii), (c)-(iv), (d)-(ii) | |
(a)-(ii), (b)-(iv), (c)-(i), (d)-(iii) | |
None of the above |
Question 9 Explanation:
→ Dynamic programming language is a class of high-level programming languages which, at runtime, execute many common programming behaviors that static programming languages perform during compilation. These behaviors could include extension of the program, by adding new code, by extending objects and definitions, or by modifying the type system.
→ Ada is a structured, statically typed, imperative, and object-oriented high-level computer programming language, extended from Pascal and other languages.
→ Prolog is a logic programming language associated with artificial intelligence and computational linguistics. Prolog is intended primarily as a declarative programming language: the program logic is expressed in terms of relations, represented as facts and rules.
→ Python is dynamically typed and garbage-collected. It supports multiple programming paradigms, including procedural, object-oriented, and functional programming
→ Ada is a structured, statically typed, imperative, and object-oriented high-level computer programming language, extended from Pascal and other languages.
→ Prolog is a logic programming language associated with artificial intelligence and computational linguistics. Prolog is intended primarily as a declarative programming language: the program logic is expressed in terms of relations, represented as facts and rules.
→ Python is dynamically typed and garbage-collected. It supports multiple programming paradigms, including procedural, object-oriented, and functional programming
Question 10 |
The combination of an IP address and a port number is known as ___________.
network number | |
socket address | |
subnet mask number | |
MAC address |
Question 10 Explanation:
Socket address: A socket address is used to uniquely identify a process on a host.
Example: There can be multiple hosts that are communicating to a server. So to identify each host uniquely IP address is required. Now there could be multiple processes executing on a host machine So to identify each process uniquely on a host Port number is used.
So to identify a process on a host combination of an IP address and a port number is used and this combination is termed as Socket Address.
Socket Address is a 48-bit address which includes 32 -bit IP address and 16-bit Port address.
Example: There can be multiple hosts that are communicating to a server. So to identify each host uniquely IP address is required. Now there could be multiple processes executing on a host machine So to identify each process uniquely on a host Port number is used.
So to identify a process on a host combination of an IP address and a port number is used and this combination is termed as Socket Address.
Socket Address is a 48-bit address which includes 32 -bit IP address and 16-bit Port address.
Question 11 |
A network with a bandwidth of 10 Mbps can pass only an average of 15,000 frames per minute with each frame carrying an average of 8,000 bits. What is the throughput of this network?
2 Mbps | |
60 Mbps | |
120 Mbps | |
10 Mbps |
Question 11 Explanation:
1 minute - 1500 frames
60 seconds - 1500 frames
1 second - 1500/60 frames
1 second = 25 frames
Now each frame is of 8,000 bits.
So total bits in 1 second = 25 × 80 bits
= 25×8000/1000000 Mbps
= 200/100 Mbps
= 2 Mbps
60 seconds - 1500 frames
1 second - 1500/60 frames
1 second = 25 frames
Now each frame is of 8,000 bits.
So total bits in 1 second = 25 × 80 bits
= 25×8000/1000000 Mbps
= 200/100 Mbps
= 2 Mbps
Question 12 |
Consider a subnet with 720 routers. If a three-level hierarchy is chosen with eight clusters, each containing 9 regions of 10 routers, then the total number of entries in the routing table is __________.
25 | |
27 | |
53 | |
72 |
Question 12 Explanation:
For example, consider a subnet with 720 routers. If there is no hierarchy, each router needs 720 routing table entries.
If the subnet is partitioned into 24 regions of 30 routers each, each router needs 30 local entries plus 23 remote entries for a total of 53 entries.
If a three-level hierarchy is chosen, with eight clusters, each containing 9 regions of 10 routers, each router needs 10 entries for local routers, 8 entries for routing to other regions within its own cluster, and 7 entries for distant clusters, for a total of 25 entries.
If the subnet is partitioned into 24 regions of 30 routers each, each router needs 30 local entries plus 23 remote entries for a total of 53 entries.
If a three-level hierarchy is chosen, with eight clusters, each containing 9 regions of 10 routers, each router needs 10 entries for local routers, 8 entries for routing to other regions within its own cluster, and 7 entries for distant clusters, for a total of 25 entries.
Question 13 |
In a classful addressing, the IP addresses with 0 (zero) as network number :
refers to the current network | |
refers to broadcast on the local network
| |
refers to broadcast on a distant network | |
refers to loopback testing | |
None of the above |
Question 13 Explanation:
In a classful addressing, the IP addresses with 0 (zero) as network number refers to the default IP of a host when it has no IP. When a host don’t have any IP then it sends a RARP request by having 0.0.0.0 as source IP.
NOTE: So none of the options is correct but according to UGC official answer keys the correct answer is given as option(A)
NOTE: So none of the options is correct but according to UGC official answer keys the correct answer is given as option(A)
Question 14 |
In electronic mail, which of the following protocols allows the transfer of multimedia messages?
IMAP | |
SMTP | |
POP 3 | |
MIME |
Question 14 Explanation:
SMTP(Simple Mail Transfer Protocol) is used to send mail containing text, voice, video, to MTA of destination.
MIME(Multimedia Internet Mail Extension) is not a mail protocol. It is used to send mails containing ASCII and Non-ASCII files.
It is an extension of SMTP but not a mail protocol.
POP3(Post Office Protocol) is a client server architecture used to download message from MTA to workstation for offline use.
IMAP(Internet Message Access Protocol) is a client server architecture used to check messages without downloading from MTA.
MIME(Multimedia Internet Mail Extension) is not a mail protocol. It is used to send mails containing ASCII and Non-ASCII files.
It is an extension of SMTP but not a mail protocol.
POP3(Post Office Protocol) is a client server architecture used to download message from MTA to workstation for offline use.
IMAP(Internet Message Access Protocol) is a client server architecture used to check messages without downloading from MTA.
Question 15 |
A device is sending out data at the rate of 2000 bps. How long does it take to send a file of 1,00,000 characters ?
50 | |
200 | |
400 | |
800 |
Question 15 Explanation:
Explanation: 1 character ------- 8-bits
1,00,000 character ---------- 8,00,000 bits
2000 bits--------- 1 second
1 bit ---------- 1/2000 seconds
8,00,000 bits ---------(1/2000)* 8,00,000
= 400 seconds
1,00,000 character ---------- 8,00,000 bits
2000 bits--------- 1 second
1 bit ---------- 1/2000 seconds
8,00,000 bits ---------(1/2000)* 8,00,000
= 400 seconds
Question 16 |
In Activity - Selection problem, each activity ai has a start time si and a finish time fi where si ≤ fi. Activities ai and aj are compatible if:
si ≥ fj | |
sj ≥ fi | |
si ≥ fj or sj ≥ fi | |
si ≥ fj and sj ≥ fi |
Question 16 Explanation:
Each activity ai has a start time si and a finish time fi where 0 ≤ si < fi < ∞. If selected, activity ai takes place during the half-open time interval [ si , fi ]. Activities ai and aj are compatible if the intervals [ si , fi ] and [ sj , fj ] do not overlap. That is, ai and aj are compatible if si ≥ fj or sj ≥ fi. In the activity-selection problem, we wish to select a maximum-size subset of mutually compatible activities.
Question 17 |
Given two sequences X and Y :
X = < a, b, c, b, d, a, b >
Y = < b, d, c, a, b, a >
The longest common subsequence of X and Y is :
X = < a, b, c, b, d, a, b >
Y = < b, d, c, a, b, a >
The longest common subsequence of X and Y is :
< b, c, a >
| |
< c, a, b > | |
< b, c, a, a > | |
< b, c, b, a > |
Question 17 Explanation:
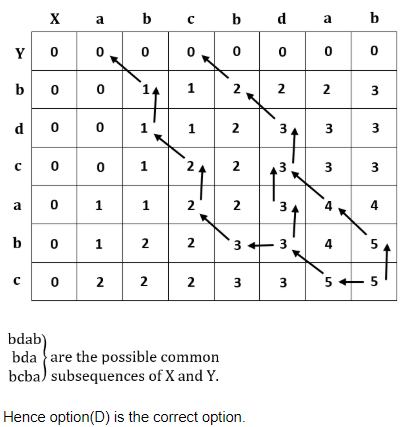
Question 18 |
If there are n integers to sort, each integer has d digits and each digit is in the set {1, 2, ..., k}, radix sort can sort the numbers in :
O(d n k) | |
O(d nk) | |
O((d +n) k) | |
O(d (n + k))
|
Question 18 Explanation:
The radix sort running time depends on the stable sort used as the intermediate sorting algorithm. When each digit is in the range 0 to k-1(It takes k possible values), and ‘k’ is not too large, counting sort is the obvious choice. Each pass over n d-digits numbers then takes time O(n+k). There are ‘d’ passes, and so total time for radix sort is O(d (n + k))
There are 18 questions to complete.