CHENNAI MATHEMATICAL INSTITUTE - M.Sc. / Ph.D. Programme in Computer Science ( 15 May 2014 )
Question 1 |
For the inter-hostel six-a-side football tournament, a team of 6 players is to be chosen from 11 players consisting of 5 forwards, 4 defenders and 2 goalkeepers. The team must include at least 2 forwards, at least 2 defenders and at least 1 goalkeeper. Find the number of different ways in which the team can be chosen.
260 | |
340 | |
720 | |
1440 |
Question 1 Explanation:
5 positions are fixed. The 6th can be forward/defender/goalkeeper.

Question 2 |
The 12 houses on one side of a street are numbered with even numbers starting at 2 and going up to 24. A free newspaper is delivered on Monday to 3 different houses chosen at random from these 12. Find the probability that at least 2 of these newspapers are delivered to houses with numbers strictly greater than 14.
7/11 | |
5/12 | |
4/11 | |
5/22 |
Question 2 Explanation:
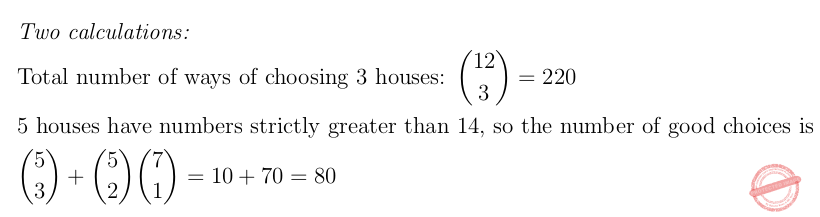

Question 3 |
In the code fragment on the right, start and end are integer values and prime(x) is a function that returns true if x is a prime number and false otherwise.
i := 0; j := 0; k := 0;
for (m := start; m <= end; m := m+1){
k := k + m;
if (prime(m)){
i := i + m;
}else{
j := j + m;
}
}
At the end of the loop:
k < i+j | |
k = i+j | |
k > i+j | |
Depends on start and end |
Question 3 Explanation:
In each iteration, the value added to k is also added to exactly one of i and j.
Question 4 |
Alan’s task is to design an algorithm for a decision problem P . He knows that there is an algorithm A that transforms instances of P to instances of the Halting Problem such that yes instances of P map to yes instances of the Halting Problem, and no instances of P map to no instances of the Halting problem. Which of the following is true.
The existence of A implies the existence of an algorithm for P . | |
The existence of A implies that there is no algorithm for P . | |
The existence of A says nothing about whether there is an algorithm for P . | |
The Halting Problem can be solved using A. |
Question 4 Explanation:
The reduction is from P to the Halting Problem, so we cannot infer undecidability of P .
There are 4 questions to complete.