UGC NET CS 2008-june-Paper-2
Question 1 |
Which of the following does not define a tree ?
A tree is a connected acyclic graph. | |
A tree is a connected graph with n-1 edges where ‘n’ is the number of vertices in the graph. | |
A tree is an acyclic graph with n-1 edges where ‘n’ is the number of vertices in the graph. | |
A tree is a graph with no cycles. |
Question 1 Explanation:
→ An undirected graph is connected when there is a path between every pair of vertices. In a connected graph, there are no unreachable vertices. A graph that is not connected is disconnected. An undirected graph G is said to be disconnected if there exist two nodes in G such that no path in G has those nodes as endpoints.
→ An acyclic graph is a graph having no graph cycles. Acyclic graphs are bipartite.
→ A connected acyclic graph is known as a tree, and a possibly disconnected acyclic graph is known as a forest (i.e., a collection of trees).
→ All first 3 options are correctly defining tree without any loss of information, whereas "A tree is a graph with no cycles." is not always correct as it can be bipartite.
Hence D does not define a tree.
→ An acyclic graph is a graph having no graph cycles. Acyclic graphs are bipartite.
→ A connected acyclic graph is known as a tree, and a possibly disconnected acyclic graph is known as a forest (i.e., a collection of trees).
→ All first 3 options are correctly defining tree without any loss of information, whereas "A tree is a graph with no cycles." is not always correct as it can be bipartite.
Hence D does not define a tree.
Question 2 |
The complexity of Kruskal’s minimum spanning tree algorithm on a graph with ‘n’ nodes and ‘e ’ edges is :
O (n) | |
O (n log n) | |
O (e log n) | |
O (e) |
Question 2 Explanation:
MST-KRUSKAL(G,w)
1. A=∅
2. for each vertex v∈ G.V
3. MAKE-SET(v)
4. sort the edges of G.E into nondecreasing order by weight w
5. for each edge (u,v)∈G.E, taken in nondecreasing order by weight
6. if FIND-SET(u)≠FIND-SET(v)
7. A=A∪{(u,v)}
8. UNION(u,v)
9. return A
Analysis:
The running time of Kruskal’s algorithm for a graph G=(V,E) depends on how we implement the disjoint-set data structure.
→ Initializing the set A in line 1 takes O(1) time, and the time to sort the edges in line 4 is O(ElgE). (We will account for the cost of the |V| MAKE-SET operations in the for loop of lines 2–3 in a moment.)
→ The for loop of lines 5–8 performs O(E) FIND-SET and UNION operations on the disjoint-set forest.
→ Along with the |V| MAKE-SET operations, these take a total of O((V+E)α(V)) time, where α is the very slowly growing function.
→ Because we assume that G is connected, we have |E|>=|V|-1, and so the disjoint-set operations take O(Eα(V)) time.
→ Moreover, since α |V|=O(lg V)=O(lg E), the total running time of Kruskal’s algorithm is O(ElgE)
→ Observing that |E|<|V|2 , we have lg |E|=O(lg V), and so we can restate the running time of Kruskal’s algorithm as O(E lg V)
1. A=∅
2. for each vertex v∈ G.V
3. MAKE-SET(v)
4. sort the edges of G.E into nondecreasing order by weight w
5. for each edge (u,v)∈G.E, taken in nondecreasing order by weight
6. if FIND-SET(u)≠FIND-SET(v)
7. A=A∪{(u,v)}
8. UNION(u,v)
9. return A
Analysis:
The running time of Kruskal’s algorithm for a graph G=(V,E) depends on how we implement the disjoint-set data structure.
→ Initializing the set A in line 1 takes O(1) time, and the time to sort the edges in line 4 is O(ElgE). (We will account for the cost of the |V| MAKE-SET operations in the for loop of lines 2–3 in a moment.)
→ The for loop of lines 5–8 performs O(E) FIND-SET and UNION operations on the disjoint-set forest.
→ Along with the |V| MAKE-SET operations, these take a total of O((V+E)α(V)) time, where α is the very slowly growing function.
→ Because we assume that G is connected, we have |E|>=|V|-1, and so the disjoint-set operations take O(Eα(V)) time.
→ Moreover, since α |V|=O(lg V)=O(lg E), the total running time of Kruskal’s algorithm is O(ElgE)
→ Observing that |E|<|V|2 , we have lg |E|=O(lg V), and so we can restate the running time of Kruskal’s algorithm as O(E lg V)
Question 3 |
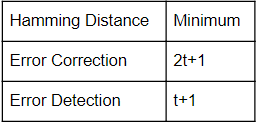
If a code is t-error correcting, the minimum Hamming distance is equal to :
2t+1 | |
2t | |
2t-1 | |
t-1 |
Question 3 Explanation:
Question 4 |
The set of positive integers under the operation of ordinary multiplication is :
not a monoid | |
not a group | |
a group | |
an Abelian group |
Question 4 Explanation:
The set of positive integers under the operation of ordinary multiplication is a monoid but not a group.
Question 5 |
In a set of 8 positive integers, there always exists a pair of numbers having the same remainder when divided by :
7 | |
11 | |
13 | |
15 |
Question 5 Explanation:
Given data,
-- Set of positive integers=8
-- A pair of numbers having the same remainder when divided by=?
Step-1: This problem, we can use pigeonhole principle.
Pigeonhole Principle: If there are ‘X’ positive integers to be placed in ‘Y’ possible remainder where Y < X, then there is at least one possible remainder which receives more than one positive integer.
Option-A: Total number of possible remainders, divided by 7 is 0,1,2,3,4,5,6.
These numbers are less than 8 only.
Option-B,C and D: Total number of possible remainders,
divided by 11, 13, 15 is greater than 8
-- Set of positive integers=8
-- A pair of numbers having the same remainder when divided by=?
Step-1: This problem, we can use pigeonhole principle.
Pigeonhole Principle: If there are ‘X’ positive integers to be placed in ‘Y’ possible remainder where Y < X, then there is at least one possible remainder which receives more than one positive integer.
Option-A: Total number of possible remainders, divided by 7 is 0,1,2,3,4,5,6.
These numbers are less than 8 only.
Option-B,C and D: Total number of possible remainders,
divided by 11, 13, 15 is greater than 8
Question 6 |
An example of a tautology is :
x v y | |
x v (~y) | |
x v (~x) | |
(x=>y) v (x<=y) |
Question 6 Explanation:

Question 7 |
Among the logic families RTL, TTL, ECL and CMOS, the fastest family is :
ECL | |
CMOS | |
TTL | |
RTL |
Question 7 Explanation:
Emitter Coupled Logic (ECL):
The storage time is eliminated as the transistors are used in difference amplifier mode and are never driven into saturation.
1. Fastest among all logic families
2. Lowest propagation delay.
Complementary metal oxide semiconductor(CMOS):
The power dissipation is usually 10nW per gate depending upon the power supply voltage, output load etc.
1. Lowest power dissipation
2. Excellent noise immunity
3. High packing density
4. Wide range of supply voltage
5. Highest fan out among all logic families
Transistor Transistor Logic:
→ TTL devices consume substantially more power than equivalent CMOS devices at rest, but power consumption does not increase with clock speed as rapidly as for CMOS devices.
The storage time is eliminated as the transistors are used in difference amplifier mode and are never driven into saturation.
1. Fastest among all logic families
2. Lowest propagation delay.
Complementary metal oxide semiconductor(CMOS):
The power dissipation is usually 10nW per gate depending upon the power supply voltage, output load etc.
1. Lowest power dissipation
2. Excellent noise immunity
3. High packing density
4. Wide range of supply voltage
5. Highest fan out among all logic families
Transistor Transistor Logic:
→ TTL devices consume substantially more power than equivalent CMOS devices at rest, but power consumption does not increase with clock speed as rapidly as for CMOS devices.
Question 8 |
The octal equivalent of the hexadecimal number FF is :
100 | |
150 | |
377 | |
737 |
Question 8 Explanation:
Step-1: Convert FF into binary number
(FF)16 = (1111 1111)2
Step-2: Divide binary number into 3 segments from LSB(Least significant bit).
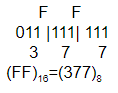
(FF)16 = (1111 1111)2
Step-2: Divide binary number into 3 segments from LSB(Least significant bit).
Question 9 |
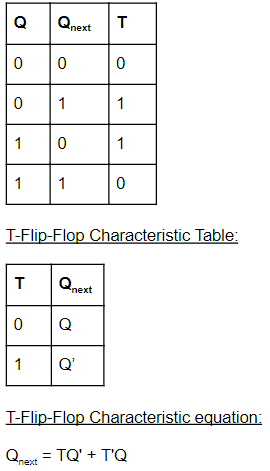
The characteristic equation of a T flip flop is given by :
QN+1 = TQN | |
QN+1 = T+QN | |
QN+1 = T ⊕ QN | |
QN+1=T'QN |
Question 9 Explanation:
T-Flip flop Truth Table:
Question 10 |
The idempotent law in Boolean algebra says that :
~(~x)=x | |
x+x=x | |
x+xy=x | |
x(x+y)=x |
Question 10 Explanation:
→ Idempotent law:
The idempotence in the context of elements of algebras that remain invariant when raised to a positive integer power, and literally means "(the quality of having) the same power", from idem + potence (same + power).
(i). X + X=X
(ii). X ∧ X=X
According to boolean algebra
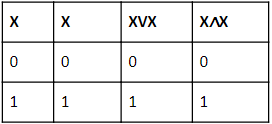
The idempotence in the context of elements of algebras that remain invariant when raised to a positive integer power, and literally means "(the quality of having) the same power", from idem + potence (same + power).
(i). X + X=X
(ii). X ∧ X=X
According to boolean algebra
Question 11 |
What is the effect of the following C code ?
for(int i=1; i≤5; i=i+½)
printf(“%d,”,i);
for(int i=1; i≤5; i=i+½)
printf(“%d,”,i);
It prints 1, 1.5, 2, 2.5, 3, 3.5, 4, 4.5, 5, and stops | |
It prints 1, 2, 3, 4, 5, and stops | |
It prints 1, 2, 3, 4, 5, and repeats forever | |
It prints 1, 1, 1, 1, 1, and repeats forever |
Question 11 Explanation:
According to integer datatype, fraction values we are not considering. So,it will always become
1. Iteration-1: for(int i=1; i≤5; i=i+½) /*condition TRUE, then we are printing value but incrementing by 0. It means, i=1+0 */
So, ‘i’ value always become 1 only. The given condition always TRUE and will print infinite times.
1. Iteration-1: for(int i=1; i≤5; i=i+½) /*condition TRUE, then we are printing value but incrementing by 0. It means, i=1+0 */
So, ‘i’ value always become 1 only. The given condition always TRUE and will print infinite times.
Question 12 |
Consider the following declaration in C :
char a[ ];
char *p;
Which of the following statement is not a valid statement ?
char a[ ];
char *p;
Which of the following statement is not a valid statement ?
p=a; | |
p=a+2; | |
a=p; | |
p=&a[2]; |
Question 12 Explanation:
According to pointer value assigning declarations,
p=a; /*It is correct declaration */
p=p+2; /*It is correct declaration */
p=&a[2]; /*It is correct declaration */
a=p; /* It is incorrect declaration */
p=a; /*It is correct declaration */
p=p+2; /*It is correct declaration */
p=&a[2]; /*It is correct declaration */
a=p; /* It is incorrect declaration */
There are 12 questions to complete.