OOPS
October 29, 2023Question 9491 – GATE 2004
October 29, 2023NTA UGC NET JUNE-2023 Paper-2
|
Question 12
|
|
{12n2+6n | n is a natural number}
|
|
|
{24 n-12| n is a natural number}
|
|
|
{60n+30| n is a natural number}
|
|
|
{12n-6| n is a natural number}
|
|
Question 13
|
Assertion A: Validity checks real need of system users
Reason R: Completeness checks system user defined requirements
In the light of the above statements, choose the correct answer from the options given below
|
Both A and R are correct and R is the correct explanation of A
|
|
|
Both A and R are correct and R is the NOT correct explanation of A
|
|
|
A is true but R is false
|
|
|
A is false but R is true
|
Assertion A: This statement is correct. Validity checks are essential to ensure that the system meets the real needs and requirements of the system users.
Reason R: Completeness checks are indeed about verifying that the system user-defined requirements are fully captured, but this doesn’t directly explain the concept of validity checks.
Both A and R are independently valid statements, but Reason R doesn’t directly provide an explanation for Assertion A. So, the correct answer is:
Both A and R are correct, but R is not the correct explanation of A.
|
Question 14
|
|
Binary valued
|
|
|
Real valued
|
|
|
Permutation
|
|
|
Combinations
|
Binary Valued: Where each gene in an individual is represented as a binary value (0 or 1).
Real Valued: Where each gene in an individual is represented as a real number, often within a specific range.
Permutation: Where the genes represent a permutation or ordering of elements. This is often used for problems like the Traveling Salesman Problem.
“Combinations” as a direct representation is not commonly used in genetic algorithms. Instead, it might be implemented using other representations like binary, real-valued, or permutation depending on the specific problem being solved.
|
Question 15
|
|
25.25 microseconds and 51.2 microseconds
|
|
|
51.2 microseconds and 12.5 microseconds
|
|
|
10.24 microseconds and 50.12 microseconds
|
|
|
12.5 microseconds and 51.2 microseconds
|
|
Question 16
|
|
Atomicity
|
|
|
Consistency
|
|
|
Isolation
|
|
|
Deadlock-freedom
|
Atomicity: Transactions are treated as all-or-nothing units. Either all the changes are applied, or none of them are.
Consistency: A transaction should bring the database from one consistent state to another consistent state. It ensures that the integrity constraints and rules are not violated during the transaction.
Isolation: Transactions should be isolated from each other, meaning the operations within a transaction should not interfere with other concurrent transactions.
Durability: Once a transaction is committed, its changes are permanent and will survive system failures.
“Deadlock-freedom” is related to concurrency control mechanisms and techniques but is not typically considered one of the core ACID properties. It’s concerned with avoiding situations where multiple transactions are waiting for each other, leading to a standstill in processing.
|
Question 17
|
A. C-fuzzy means cluster is supervised method of learning
B. PCA is used for dimension reduction
C. Apriori is not a supervised technique
D. When a machine learning model becomes so specially tuned to its exact input data that it fails to generalize to other similar data it is called underfitting
Choose the correct answer from the options given below
|
A and B
|
|
|
B and C
|
|
|
C and D
|
|
|
D and A
|
Statement C is also correct. Apriori is a frequent itemset mining algorithm used in association rule learning and is not a supervised technique in machine learning.
Statements A and D are not correct:
Statement A is incorrect. “C-fuzzy” is not a standard term in machine learning, and the statement doesn’t accurately describe a supervised method of learning.
Statement D is also incorrect. “Underfitting” is when a model is too simple and fails to capture the underlying patterns in data. It is the opposite of overfitting, which is when a model becomes too specialized to its training data.
|
Question 18
|
Assertion A: The AVL tree are more balanced as compared to Red black trees, but they may cause more rotations during insertions and deletion
Reason R: A Red Black tree with n nodes has height that is greater than 2 log2(n+1) and the AVL tree with n nodes has height less than log∅(√5(n+2))-2 (where ∅ is golden ratio)
In the light of the above statements, choose the correct answer from the options given below
|
Both A and R are correct and R is the correct explanation of A
|
|
|
Both A and R are correct and R is the NOT correct explanation of A
|
|
|
A is true but R is false
|
|
|
A is false but R is true
|
Assertion A: This statement is correct. AVL trees are generally more balanced than Red-Black trees, which means their heights are closer to logarithmic. However, the insertion and deletion operations in AVL trees may cause more rotations compared to Red-Black trees.
Red-Black Tree Height: In a Red-Black tree, the height is guaranteed to be at most approximately 2 * log₂(n+1), where “n” is the number of nodes in the tree. It can be at most twice the height of a balanced tree, which is log₂(n+1). So, the statement correctly indicates that the height is “greater than 2 * log₂(n+1).”
AVL Tree Height: In an AVL tree, the height is guaranteed to be at most log∅(√5(n+2)) – 2, where “n” is the number of nodes in the tree. The golden ratio (∅) is approximately 1.618. So, the height of an AVL tree is less than log∅(√5(n+2)) – 2.
|
Question 19
|
|
EMPTY: REAR == FRONT , FULL: (REAR+1) mod n == FRONT
|
|
|
EMPTY: (FRONT+1) mod n == REAR,FULL: (REAR+1) mod n == FRONT
|
|
|
EMPTY: (REAR+1) mod n == FRONT,FULL: REAR == FRONT
|
|
|
EMPTY: REAR == FRONT,FULL: (FRONT+1) mod n == REAR empty
|
EMPTY: REAR == FRONT, FULL: (REAR + 1) mod n == FRONT
|
Question 20
|
|
(0,0)(6,0)(0,4)(6,4)
|
|
|
(0,0)(6,0)(0,4)(3,2)
|
|
|
(0,0)(6,0)(0,6)(6,6)
|
|
|
(0,0)(4,0)(0,6)(4,6)
|
Given the original vertices of the rectangle:
(0, 0)
(0, 2)
(3, 0)
(3, 2)
After scaling, the new coordinates are:
(0 * 2, 0 * 3) = (0, 0)
(0 * 2, 2 * 3) = (0, 6)
(3 * 2, 0 * 3) = (6, 0)
(3 * 2, 2 * 3) = (6, 6)
So, the correct new coordinates of the rectangle after scaling are:
(0, 0) (0, 6) (6, 0) (6, 6)
The option that matches these coordinates is:
(0, 0) (0, 6) (6, 0) (6, 6)
|
Question 21
|
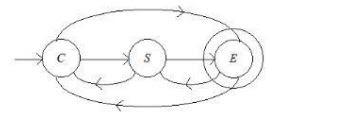
Let F2 be a finite automata which is obtained by reversal of F1.ten which of the following is correct?
|
L(F1) ≠ L(F2)
|
|
|
L(F1)=L(F2)
|
|
|
L(F1) ≤ L(F2)
|
|
|
L(F1) ≥ L(F2)
|
|
Question 22
|
A.The MAX-HEAPIFY procedure which runs in O lg(n) time, is the key to maintaining the max heap property
B. The BUILD-MAX-HEAP procedure which runs in O lg(n) time,produces max-heap from an unordered input array
C. The MAX-HEAP-INSERT, which runs in O(lg n) time, implements the insertion operation
D.The HEAP-INCREASE-KEY procedure runs in O(nlg n) time, to set the key of new node of its correct value
Choose the correct answer from the options given below
|
A,B only
|
|
|
A,C only
|
|
|
B,D only
|
|
|
A,B,C,D
|
B. The statement “The BUILD-MAX-HEAP procedure which runs in O(log n) time, produces a max-heap from an unordered input array” is incorrect. BUILD-MAX-HEAP typically runs in O(n) time, not O(log n) time. It’s used to create a max-heap from an unordered array.
C. The statement “The MAX-HEAP-INSERT, which runs in O(log n) time, implements the insertion operation” is correct. MAX-HEAP-INSERT is used for inserting elements into a max-heap and typically runs in O(log n) time.
D. The statement “The HEAP-INCREASE-KEY procedure runs in O(n log n) time, to set the key of a new node to its correct value” is incorrect. HEAP-INCREASE-KEY usually runs in O(log n) time, not O(n log n) time.
So, the correct statements are A and C
|
Question 23
|
Statement I: Fuzzifier is a part of a fuzzy system
Statement Ii: Inference engine is a part of fuzzy system
In the ligt of the above statements, choose the most appropriate answer from the options given below
|
Both statement I and Statement II are correct
|
|
|
Both statement I and Statement II are incorrect
|
|
|
Statement I is correct but Statement II is incorrect
|
|
|
Statement I is incorrect but Statement II is correct
|
Statement II is also correct because an “inference engine” is a crucial component of a fuzzy system. It’s responsible for making decisions and performing reasoning based on fuzzy logic rules and inputs.
Both statements are accurate, and there is no conflict between them.
|
Question 24
|
Statement I: If f and g are two functions and f=O(g) but g!=o(f), we say that the growth rate of g is smaller than that of f.
Statement Ii: The class of all decision problems decided by a TM in exponential time, that is O(2k), k being a constant
In the light of the above statements, choose the most appropriate answer from the options given below
|
Both statement I and Statement II are correct
|
|
|
Both statement I and Statement II are incorrect
|
|
|
Statement I is correct but Statement II is incorrect
|
|
|
Statement I is incorrect but Statement II is correct
|
|
Question 25
|
A->B,B->C
C->D and D->B
The decomposition of R into (A,B)(B,C)(B,D)
|
gives a lossless join, and is dependency preserving
|
|
|
gives lossless join,but is not dependency preserving
|
|
|
does not give a lossless join, but is dependency preserving
|
|
|
does not give a lossless join, but is not dependency preserving
|
A -> B
B -> C
C -> D
D -> B
Now, let’s consider the decomposition of R into (A, B), (B, C), and (B, D).
Lossless Join:
For the decomposition to be lossless join, we need to check if the natural join of the decomposed schemas can reconstruct the original relation R.
(A, B) ∩ (B, C) = (B)
(B, C) ∩ (B, D) = (B)
Both intersections include the attribute B. So, joining (A, B), (B, C), and (B, D) together would reconstruct all attributes of R. Therefore, the decomposition gives a lossless join.
Dependency Preservation:
For the decomposition to be dependency preserving, it should be checked if all the original functional dependencies can be inferred from the functional dependencies in the decomposed schemas.
In (A, B):
A -> B (from the original dependencies)
In (B, C):
B -> C (from the original dependencies)
In (B, D):
D -> B (from the original dependencies)
All original functional dependencies can be inferred from the functional dependencies in the decomposed schemas. Therefore, the decomposition is dependency preserving.
So, the correct answer is:
The decomposition gives a lossless join and is dependency preserving.
Assertion A: This statement is correct. Validity checks are essential to ensure that the system meets the real needs and requirements of the system users.
Reason R: Completeness checks are indeed about verifying that the system user-defined requirements are fully captured, but this doesn’t directly explain the concept of validity checks.
Both A and R are independently valid statements, but Reason R doesn’t directly provide an explanation for Assertion A. So, the correct answer is:
Both A and R are correct, but R is not the correct explanation of A.