ISRO CS 2008
Question 1 |
Which of the following is an illegal array definition?
Type COLOGNE : (LIME, PINE, MUSK, MENTHOL); var a : array [COLOGNE] of REAL; | |
var a : array [REAL] of REAL; | |
var a : array [‘A’…’Z’] of REAL; | |
var a : array [BOOLEAN] of REAL; |
Question 1 Explanation:
Array index should be integer not real numbers.
Expect the option B, All remaining indexes are not real numbers.
Option A , takes enum value as index which is integer number.
Option C, takes character which is having equivalent decimal value.
Option D, has boolean value as index whose value may be 0 or 1
Expect the option B, All remaining indexes are not real numbers.
Option A , takes enum value as index which is integer number.
Option C, takes character which is having equivalent decimal value.
Option D, has boolean value as index whose value may be 0 or 1
Question 2 |
The term Phong associated with
Ray tracing | |
shading | |
Hidden line removal | |
a game |
Question 2 Explanation:
Phong shading is a per-fragment color computation. The vertex shader provides the normal and position data as out variables to the fragment shader. The fragment shader then interpolates these variables and computes the color
Question 3 |
The subnet mask 255.255.255.192
extends the network portion to 16 bits | |
extends the network portion to 26 bits | |
extends the network portion to 36 bits | |
has no effect on the network portion of an IP address |
Question 3 Explanation:
Default subnet mask for Class C is 255.255.255.192
(192)10 = (11000000)2
Since, 192 is written as 11000000, it has 2 sub-nets and remaining all hosts.
So, for first three octets, 24 bits are fixed and for last octet 2 bits are fixed, i.e. 24 + 2 = 26 bits
(192)10 = (11000000)2
Since, 192 is written as 11000000, it has 2 sub-nets and remaining all hosts.
So, for first three octets, 24 bits are fixed and for last octet 2 bits are fixed, i.e. 24 + 2 = 26 bits
Question 4 |
On a LAN ,where are IP datagrams transported?
In the LAN header | |
In the application field | |
In the information field of the LAN frame | |
After the TCP header |
Question 4 Explanation:
IP datagram is encapsulated in the payload field of Ethernet frame, so we can say that it is transported in information field of frame.
Question 5 |
In Ethernet, the source address field in the MAC frame is the _______ address.
original sender’s physical | |
previous station’s physical | |
next destination’s physical | |
original sender’s service port |
Question 5 Explanation:
While the IP address of source and the destination in a datagram is kept same at each hop, the source MAC address is replaced at each station while the frame is in transit. So for the current station, the source address field will contain the MAC address of the previous station.
Question 6 |
Which of the following transmission media is not readily suitable to CSMA operation?
Radio | |
Optical fibers | |
Coaxial cable | |
Twisted pair |
Question 6 Explanation:
Wireless medium can’t be used for CSMA operations as they are not suitable for collision detection methods. As radio already have a large number of users, it can’t detect the collisions between the senders and the receivers.
Question 7 |
Consider the grammar
S → ABCc ∣ bc
BA → AB
Bb → bb
Ab → ab
Aa → aa
Which of the following sentences can be derived by this grammar?
S → ABCc ∣ bc
BA → AB
Bb → bb
Ab → ab
Aa → aa
Which of the following sentences can be derived by this grammar?
abc | |
aab | |
abcc | |
abbc |
Question 7 Explanation:
C is useless in S→ABCc so remove it.
S→ABc
Now see each of remaining production
Bb→bb ( i.e. B→b)
Ab→ab (i.e.A→a)
Aa→aa (i.e. A→a)
So
S→ABc→abc
S→ABc
Now see each of remaining production
Bb→bb ( i.e. B→b)
Ab→ab (i.e.A→a)
Aa→aa (i.e. A→a)
So
S→ABc→abc
Question 8 |
The TCP sliding window
can be used to control the flow of information | |
always occurs when the field value is 0 | |
always occurs when the field value is 1 | |
occurs horizontally |
Question 8 Explanation:
TCP uses a Sliding Window mechanism for the flow control of data in transit on a network. In Sliding Window, the sending device can send all packets within the TCP window size without receiving an ACK.
The receiving device should acknowledge each packet it received and after receiving the ACK from the receiving device, the sending device slides the window to right side
The receiving device should acknowledge each packet it received and after receiving the ACK from the receiving device, the sending device slides the window to right side
Question 9 |
What is the bandwidth of the signal that ranges from 40 kHz to 4 MHz
36 MHz | |
360 kHz | |
3.96 MHz | |
396 kHz |
Question 9 Explanation:
Let fh is the highest frequency and fi is the lowest frequency.
Bandwidth = fh – fi = 4000 - 40 KHz = 3960 KHz = 3.96 MHz
Bandwidth = fh – fi = 4000 - 40 KHz = 3960 KHz = 3.96 MHz
Question 10 |
Which Project 802 standard provides for a collision-free protocol?
802.2 | |
802.3 | |
802.5 | |
802.6 |
Question 10 Explanation:
→ Token ring is standardized with protocol IEEE 802.5. Token passing is the method of medium access, with only one token allowed to exist on the network at a time.
→ Network devices must acquire the token to transmit data, and may only transmit a single frame before releasing the token to the next station on the ring. When a station has data to transmit, it acquires the token at the earliest opportunity, marks it as busy, and attaches the data and control information to the token to create a data frame, which is then transmitted to the next station on the ring.
→ The frame will be relayed around the ring until it reaches the destination station, which reads the data, marks the frame as having been read, and sends it on around the ring. When the sender receives the acknowledged data frame, it generates a new token, marks it as being available for use, and sends it to the next station.
→ IEEE 802.2 is the logical link control (LLC) as the upper portion of the data link layer of the OSI Model.
→ IEEE 802.6 is a standard governed by the ANSI for Metropolitan Area Networks (MAN).
→ IEEE 802.3 is a working group and a collection of Institute of Electrical and Electronics Engineers (IEEE) standards produced by the working group defining the physical layer and data link layer media access control (MAC) of wired Ethernet.
→ Network devices must acquire the token to transmit data, and may only transmit a single frame before releasing the token to the next station on the ring. When a station has data to transmit, it acquires the token at the earliest opportunity, marks it as busy, and attaches the data and control information to the token to create a data frame, which is then transmitted to the next station on the ring.
→ The frame will be relayed around the ring until it reaches the destination station, which reads the data, marks the frame as having been read, and sends it on around the ring. When the sender receives the acknowledged data frame, it generates a new token, marks it as being available for use, and sends it to the next station.
→ IEEE 802.2 is the logical link control (LLC) as the upper portion of the data link layer of the OSI Model.
→ IEEE 802.6 is a standard governed by the ANSI for Metropolitan Area Networks (MAN).
→ IEEE 802.3 is a working group and a collection of Institute of Electrical and Electronics Engineers (IEEE) standards produced by the working group defining the physical layer and data link layer media access control (MAC) of wired Ethernet.
Question 11 |
The Boolean theorem AB + A’C + BC = AB + A’C corresponds to
(A + B) ∙ (A’ + C) ∙ (B + C) = (A + B) ∙ (A’ + C) | |
AB + A’C + BC = AB + BC | |
AB + A’C + BC = (A + B) ∙ ( A ‘+ C) ∙ (B + C) | |
(A + B) ∙ (A’ + C) ∙ (B + C) = AB + A’C |
Question 11 Explanation:
(X+Y)*(X+Z)*(Y+Z)=(X+Y)*(X+Z) Consensus Law
XY+XZ+YZ=XY+XZ Consensus Law
For min-term: AB + A'C +BC = AB + A'C
AND for max-term : ( A + B ).( A' + C ).( B + C ) = ( A + B ).(A' + C )
XY+XZ+YZ=XY+XZ Consensus Law
For min-term: AB + A'C +BC = AB + A'C
AND for max-term : ( A + B ).( A' + C ).( B + C ) = ( A + B ).(A' + C )
Question 12 |
In the given network of AND and OR gates, f can be written as
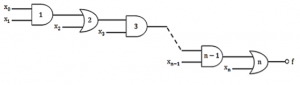
X0X1X2 … Xn + X1X2 … Xn + X2X3 … Xn + ⋯ + Xn | |
X0X1 + X2X3 + … Xn-1 Xn | |
X0 + X1 + X2 + … + Xn | |
X0X1 + X3 … Xn−1 + X2X3 + X5 … Xn−1 + ⋯ + Xn−2Xn−1 + Xn | |
None of the above |
Question 12 Explanation:
(X0X1+X2)X3+X4)X5+⋯+XN
=(X0X1X3+X2X3+X4)X5+⋯+XN
=X0X1X3X5+X2X3X5+X4X5+⋯+XN
=X0X1X3X5⋯XN−1+X2X3X5⋯XN−1+X4X5X7⋯XN−1+⋯+XN
=(X0X1X3+X2X3+X4)X5+⋯+XN
=X0X1X3X5+X2X3X5+X4X5+⋯+XN
=X0X1X3X5⋯XN−1+X2X3X5⋯XN−1+X4X5X7⋯XN−1+⋯+XN
Question 13 |
If N2 = (7601)8 where N is a positive integer, then the value of N is
(241)5 | |
(143)6 | |
(165)7 | |
(39)16 |
Question 13 Explanation:
N2 = (7601)8
N2 = 7*8*8*8 + 6*8*8 + 0 + 1*8
N2 = 3969
N = (63)10
Now, (241)5 = 2*5*5 + 4*5 + 1 = 71
Option (A) is incorrect.
(143)6 = 1*6*6 + 4*6 + 3 = 63
Option (B) is correct.
N2 = 7*8*8*8 + 6*8*8 + 0 + 1*8
N2 = 3969
N = (63)10
Now, (241)5 = 2*5*5 + 4*5 + 1 = 71
Option (A) is incorrect.
(143)6 = 1*6*6 + 4*6 + 3 = 63
Option (B) is correct.
Question 14 |
Assume that each character code consists of 8 bits. The number of characters that can be transmitted per second through an asynchronous serial line at 2400 baud rate, and with two stop bits, is:
109 | |
216 | |
218 | |
219 |
Question 14 Explanation:
Here, the baud value represents the serial port is capable of transferring a maximum number of bits per second.
Given 2400 baud value,
Sending maximum of 2400 bits per second with serial port .
Total Data To send = 1 bit(start) + 8 bits(char size) + 2 bits(Stop) = 11 bits.
Number of 8-bit characters that can be transmitted per second = 2400/11 = 218.18
The effective number of characters transmitted = 218 So, the correct option is (C).
Given 2400 baud value,
Sending maximum of 2400 bits per second with serial port .
Total Data To send = 1 bit(start) + 8 bits(char size) + 2 bits(Stop) = 11 bits.
Number of 8-bit characters that can be transmitted per second = 2400/11 = 218.18
The effective number of characters transmitted = 218 So, the correct option is (C).
Question 15 |
Four jobs to be executed on a single processor system arrive at time 0 in the order A, B, C, D . Their burst CPU time requirements are 4, 1, 8, 1 time units respectively. The completion time of A under round robin scheduling with time slice of one time unit is
10 | |
4 | |
8 | |
9 |
Question 15 Explanation:
1. All processes are arrived at time 0.
2. Algorithm used for scheduling is round robin with time quantum of one unit time.
3. The order of execution of the processes A B C D A C A C A,C,C,C,C,C
4. After 8 context switches, process A completes it execution So the completion time is 9
2. Algorithm used for scheduling is round robin with time quantum of one unit time.
3. The order of execution of the processes A B C D A C A C A,C,C,C,C,C
4. After 8 context switches, process A completes it execution So the completion time is 9
Question 16 |
Which one of the following algorithm design techniques is used in finding all pairs of shortest distances in a graph?
Dynamic programming | |
Backtracking | |
Greedy | |
Divide and Conquer |
Question 16 Explanation:
→ The Floyd-Warshall algorithm is an algorithm for finding shortest paths in a weighted graph with positive or negative edge weights (but with no negative cycles).
→ A single execution of the algorithm will find the lengths (summed weights) of shortest paths between all pairs of vertices
→ The Floyd-Warshall algorithm is an example of dynamic programming.
→ A single execution of the algorithm will find the lengths (summed weights) of shortest paths between all pairs of vertices
→ The Floyd-Warshall algorithm is an example of dynamic programming.
Question 17 |
The address space of 8086 CPU is
one Megabyte | |
256 Kilobytes | |
1 K Megabytes | |
64 Kilobytes |
Question 17 Explanation:
In 8086 architecture there are 16 bit data lines and 20 bit address lines.
16 bit data lines means that the word size must be 2 bytes and these 2 bytes can be read in a single memory cycle.
20 bit address lines corresponds that the memory size is 220 Bytes = 1 Megabyte
16 bit data lines means that the word size must be 2 bytes and these 2 bytes can be read in a single memory cycle.
20 bit address lines corresponds that the memory size is 220 Bytes = 1 Megabyte
Question 18 |
The performance of a pipelined processor suffers if
the pipeline stages have different delays | |
consecutive instructions are dependent on each other | |
the pipeline stages share hardware resources | |
All of the above |
Question 18 Explanation:
1. Pipelining is one way of improving the overall processing performance of a processor.
2. This architectural approach allows the simultaneous execution of several instructions.
3. Pipelining is transparent to the programmer; it exploits parallelism at the instruction level by overlapping the execution process of instructions.
4. It is analogous to an assembly line where workers perform a specific task and pass the partially completed product to the next worker.
2. This architectural approach allows the simultaneous execution of several instructions.
3. Pipelining is transparent to the programmer; it exploits parallelism at the instruction level by overlapping the execution process of instructions.
4. It is analogous to an assembly line where workers perform a specific task and pass the partially completed product to the next worker.
Question 19 |
If (12x)3 = (123)x then the value of x is
3 | |
3 or 4 | |
2 | |
None of these |
Question 19 Explanation:
Given, (12x)3 = (123)x
Since LHS has 3 as the base and RHS has ‘x’ base,
1 * 3*3 + 2 * 3 + x * 1 = 1 * x*x + 2 * x + 3
9 + 6 + x = x2 + 2x + 3
x2 + x - 12 = 0
x2 + 4x - 3x - 12 = 0
x( x + 4 ) - 3(x + 4) = 0
(x + 4)(x - 3) = 0
x = 3 and -4
But, both the values are infeasible.
Alternative explanation :
According to the rules of number systems , the numbers present in a number system should not be greater than the base of the number system.
According to LHS , (12x)3 tells us that the value of x should be less than 3.
According to RHS , (123)x tells us that the value of x should be greater than 3 as largest digit in 123 is 3.
Therefore, any combination is not possible.
Since LHS has 3 as the base and RHS has ‘x’ base,
1 * 3*3 + 2 * 3 + x * 1 = 1 * x*x + 2 * x + 3
9 + 6 + x = x2 + 2x + 3
x2 + x - 12 = 0
x2 + 4x - 3x - 12 = 0
x( x + 4 ) - 3(x + 4) = 0
(x + 4)(x - 3) = 0
x = 3 and -4
But, both the values are infeasible.
Alternative explanation :
According to the rules of number systems , the numbers present in a number system should not be greater than the base of the number system.
According to LHS , (12x)3 tells us that the value of x should be less than 3.
According to RHS , (123)x tells us that the value of x should be greater than 3 as largest digit in 123 is 3.
Therefore, any combination is not possible.
Question 20 |
The advantage of MOS devices over bipolar devices is that
it allows higher bit densities and also cost effective | |
it is easy to fabricate | |
it is higher-impedance and operational speed | |
all of these |
Question 20 Explanation:
Explanation:
→ The Mosfet has a much better response in high frequency than the BJT.
→ Normally the switching speed would be in the us range for the BJT while the Mosfet is in the ns range.
→ The advantage of the Mosfet is also in the circuitry needed to operate it. The BJT is a current driven device while the Mosfet is voltage driven. The circuitry for creating voltage pulses is much simpler than the ones for current pulses and the first ones require less power
→ The Mosfet has a much better response in high frequency than the BJT.
→ Normally the switching speed would be in the us range for the BJT while the Mosfet is in the ns range.
→ The advantage of the Mosfet is also in the circuitry needed to operate it. The BJT is a current driven device while the Mosfet is voltage driven. The circuitry for creating voltage pulses is much simpler than the ones for current pulses and the first ones require less power
There are 20 questions to complete.