ISRO CS 2011
Question 1 |
The encoding technique used to transmit the signal in giga ethernet technology over fiber optic medium is
Differential Manchester encoding
| |
Non return to zero | |
4B/5B encoding
| |
8B/10B encoding |
Question 1 Explanation:
→ In telecommunications, 8b/10b is a line code that maps 8-bit words to 10-bit symbols to achieve DC-balance and bounded disparity, and yet provide enough state changes to allow reasonable clock recovery
→ The FC(Fiber Channel) -0 standard defines what encoding scheme is to be used (8b/10b or 64b/66b) in a Fibre Channel system – higher speed variants typically use 64b/66b to optimize bandwidth efficiency.Thus, 8b/10b encoding is used for 4GFC and 8GFC variants;
→ The Fibre Channel 8b/10b coding scheme is also used in other telecommunications systems. Data is expanded using an algorithm that creates one of two possible 10-bit output values for each input 8-bit value.
→ The FC(Fiber Channel) -0 standard defines what encoding scheme is to be used (8b/10b or 64b/66b) in a Fibre Channel system – higher speed variants typically use 64b/66b to optimize bandwidth efficiency.Thus, 8b/10b encoding is used for 4GFC and 8GFC variants;
→ The Fibre Channel 8b/10b coding scheme is also used in other telecommunications systems. Data is expanded using an algorithm that creates one of two possible 10-bit output values for each input 8-bit value.
Question 2 |
Which of the following is an unsupervised neural network?
RBS | |
Hopfield | |
Back propagation | |
Kohonen | |
Incomplete Question |
Question 2 Explanation:
→ A self-organizing map (SOM) or self-organizing feature map (SOFM) is a type of artificial neural network (ANN) that is trained using unsupervised learning to produce a low-dimensional (typically two-dimensional), discretized representation of the input space of the training samples, called a map, and is therefore a method to do dimensionality reduction.
→ Kohonen map or network is self-organizing map
→ Hopfield nets serve as content-addressable ("associative") memory systems with binary threshold nodes. They are guaranteed to converge to a local minimum, but will sometimes converge to a false pattern (wrong local minimum) rather than the stored pattern (expected local minimum). Hopfield networks also provide a model for understanding human memory.
→ Backpropagation is a method used in artificial neural networks to calculate a gradient that is needed in the calculation of the weights to be used in the network
→ Kohonen map or network is self-organizing map
→ Hopfield nets serve as content-addressable ("associative") memory systems with binary threshold nodes. They are guaranteed to converge to a local minimum, but will sometimes converge to a false pattern (wrong local minimum) rather than the stored pattern (expected local minimum). Hopfield networks also provide a model for understanding human memory.
→ Backpropagation is a method used in artificial neural networks to calculate a gradient that is needed in the calculation of the weights to be used in the network
Question 3 |
In compiler terminology reduction in strength means
Replacing run time computation by compile time computation | |
Removing loop invariant computation | |
Removing common subexpressions
| |
replacing a costly operation by a relatively cheaper one |
Question 3 Explanation:
An optimization method in which an operator is changed to a less-expensive operator;
Example: Exponentiation is replaced by multiplication and multiplication is in return replaced by addition.(x * 2 becomes x + x)
Example: Exponentiation is replaced by multiplication and multiplication is in return replaced by addition.(x * 2 becomes x + x)
Question 4 |
The following table shows the processes in the ready queue and time required for each process for completing its job.

If round-robin scheduling with 5 ms is used what is the average waiting time of the processes in the queue?
If round-robin scheduling with 5 ms is used what is the average waiting time of the processes in the queue?
27 ms | |
26.2 ms | |
27.5 ms | |
27.2 ms |
Question 4 Explanation:
→In the round robin algorithm, time slices (also known as time quanta) are assigned to each process in equal portions and in circular order, handling all processes without priority (also known as cyclic executive).
→Given scheduling algorithm is round robin with time quantum value is 5ms.

→In the given example, every process will execute for 5ms. process P1 will execute for two times , P2 for one time, P3 for four times , P4 for two times and P5 for three times.
→Waiting time of process P1 = 0+(25-20)=5
→Waiting time of process P2 = 5
→Waiting time of process P3 = 10 + (30-15 )+ (43-35) + (53-48)=10 + 15 + 8 + 5 = 38
→Waiting time of process P4 = 15+(35-20)=15 + 15 = 30
→Waiting time of process P5 =20+(38-25)+48-43= 20 + 13 + 5 = 38
→Average waiting time = 20 + 5 + 38 + 30 + 38 =131/5 = 26.2
→Given scheduling algorithm is round robin with time quantum value is 5ms.
→In the given example, every process will execute for 5ms. process P1 will execute for two times , P2 for one time, P3 for four times , P4 for two times and P5 for three times.
→Waiting time of process P1 = 0+(25-20)=5
→Waiting time of process P2 = 5
→Waiting time of process P3 = 10 + (30-15 )+ (43-35) + (53-48)=10 + 15 + 8 + 5 = 38
→Waiting time of process P4 = 15+(35-20)=15 + 15 = 30
→Waiting time of process P5 =20+(38-25)+48-43= 20 + 13 + 5 = 38
→Average waiting time = 20 + 5 + 38 + 30 + 38 =131/5 = 26.2
Question 5 |
MOV [BX], AL type of data addressing is called ?
register | |
immediate | |
register indirect | |
register relative |
Question 5 Explanation:
Register indirect addressing means that the location of an operand is held in a register.
In register addressing mode, a register contains the operand. Depending upon the instruction, the register may be the first operand, the second operand or both.
In Immediate Addressing,an immediate operand has a constant value or an expression. When an instruction with two operands uses immediate addressing, the first operand may be a register or memory location, and the second operand is an immediate constant.
In register addressing mode, a register contains the operand. Depending upon the instruction, the register may be the first operand, the second operand or both.
In Immediate Addressing,an immediate operand has a constant value or an expression. When an instruction with two operands uses immediate addressing, the first operand may be a register or memory location, and the second operand is an immediate constant.
Question 6 |
Evaluate (X XOR Y) XOR Y?
All 1’s | |
All 0’s | |
X | |
Y |
Question 6 Explanation:

Question 7 |
Which of the following is true about the z-buffer algorithm?
It is a depth sort algorithm | |
No limitation on total number of objects | |
Comparisons of objects is done | |
z-buffer is initialized to background colour at start of algorithm |
Question 7 Explanation:
The Z-buffer algorithm is a convenient algorithm for rendering images properly according to depth.
To begin with, a buffer containing the closest depth at each pixel location is created parallel to the image buffer. Each location in this depth buffer is initialized to negative infinity.
Since the algorithm processes objects one at a time, the total number of polygons in a picture can be arbitrarily large.
To begin with, a buffer containing the closest depth at each pixel location is created parallel to the image buffer. Each location in this depth buffer is initialized to negative infinity.
Since the algorithm processes objects one at a time, the total number of polygons in a picture can be arbitrarily large.
Question 8 |
What is the decimal value of the floating-point number C1D00000 (hexadecimal notation)? (Assume 32-bit, single precision floating point IEEE representation)
28 | |
-15 | |
-26 | |
-28 |
Question 8 Explanation:
Floating Point number in Hexadecimal = C1D00000
Floating Point number in Binary = 1100 0001 1101 0000 0000 0000 0000 0000
In 32-bit, single precision floating point IEEE representation, first MSB represents sign of mantissa: 1 is used to represent a negative mantissa and 0 for a positive value of mantissa, next 8 bits are for exponent value and then 23 bits represents mantissa.
Value of exponent = 131-127 = 4
Mantissa = -1.1010000 0000 0000 0000 0000
Floating point number = -1.1010000 0000 0000 0000 0000
Converting the above one into decimal no -(1*20+1*2-1*0*2-2+1*2-2+0* 2-3 +.....)
= -(1+½+⅛)=-13/8
Decimal value =sign*Exponent*mantissa=1*4*-13/8
= -26
Floating Point number in Binary = 1100 0001 1101 0000 0000 0000 0000 0000
In 32-bit, single precision floating point IEEE representation, first MSB represents sign of mantissa: 1 is used to represent a negative mantissa and 0 for a positive value of mantissa, next 8 bits are for exponent value and then 23 bits represents mantissa.
Value of exponent = 131-127 = 4
Mantissa = -1.1010000 0000 0000 0000 0000
Floating point number = -1.1010000 0000 0000 0000 0000
Converting the above one into decimal no -(1*20+1*2-1*0*2-2+1*2-2+0* 2-3 +.....)
= -(1+½+⅛)=-13/8
Decimal value =sign*Exponent*mantissa=1*4*-13/8
= -26
Question 9 |
What is the raw throughput of USB 2.0 technology?
480 Mbps
| |
400 Mbps | |
200 Mbps | |
12 Mbps |
Question 9 Explanation:
The USB 3.0 SuperSpeed path operates at a raw bit rate of 5.0 Gbits/s, while the USB 2.0 path operates at 480 Mbits/s (High Speed), 12 Mbits/s (Full Speed), or 1.5 Mbits/s (Low Speed).
Question 10 |
Below is the precedence graph for a set of tasks to be executed on a parallel processing system S.
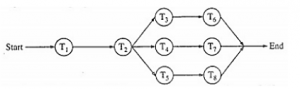
What is the efficiency of this precedence graph on S if each of the tasks T1, T2, T3,….T8 takes the same time and the system S has five processors?
What is the efficiency of this precedence graph on S if each of the tasks T1, T2, T3,….T8 takes the same time and the system S has five processors?
25% | |
40% | |
50%
| |
90%
|
Question 10 Explanation:
From the precedence graph, we say that the following tasks executed sequentially
I. T1 ,T2
II. T3 and T6
III. T4 and T7
IV. T5 and T8
(T3,T6),(T4,T7) and (T5,T8) will execute parallely.
So total number of processes that can be executed in 4 units time using 5 available processors = 5*4 = 20
Maximum number of tasks are 8
Efficiency = 8/20 * 100 = 40%
I. T1 ,T2
II. T3 and T6
III. T4 and T7
IV. T5 and T8
(T3,T6),(T4,T7) and (T5,T8) will execute parallely.
So total number of processes that can be executed in 4 units time using 5 available processors = 5*4 = 20
Maximum number of tasks are 8
Efficiency = 8/20 * 100 = 40%
Question 11 |
How many distinct binary search trees can be created out of 4 distinct keys?
5 | |
14 | |
24 | |
35 |
Question 11 Explanation:
The number of distinct BST for n nodes are given as ((2n)Cn)/(n+1)
So, for 4 distinct nodes, we can have (8C4)/5 = 14 distinct BSTs
So, for 4 distinct nodes, we can have (8C4)/5 = 14 distinct BSTs
Question 12 |
The network protocol which is used to get MAC address of a node by providing IP address is
SMTP | |
ARP | |
RIP | |
BOOTP |
Question 12 Explanation:
→ Address Resolution Protocol(ARP) is used to find the MAC address of a device using its IP address.
→ Reverse Address Resolution Protocol(RARP) is the viceversa case of ARP as it is a protocol by which a physical machine in a local area network can request to learn its IP address from a gateway server.
→ Reverse Address Resolution Protocol(RARP) is the viceversa case of ARP as it is a protocol by which a physical machine in a local area network can request to learn its IP address from a gateway server.
Question 13 |
Which of the following statements about peephole optimization is False?
It is applied to a small part of the code | |
It can be used to optimize intermediate code | |
To get the best out of this, it has to be applied repeatedly | |
It can be applied to the portion of the code that is not contiguous |
Question 13 Explanation:
Peephole optimization is a type of Code Optimization performed on a small part of the code. It is performed on the very small set of instructions in a segment of code.
It basically works on the theory of replacement in which a part of code is replaced by shorter and faster code without change in output.
It basically works on the theory of replacement in which a part of code is replaced by shorter and faster code without change in output.
Question 14 |
Which one of the following in place sorting algorithms needs the minimum number of swaps?
Quick sort | |
Insertion sort | |
Selection sort | |
Heap sort |
Question 14 Explanation:
Selection sort requires maximum number of swaps i.e O(n).
The algorithm finds the minimum value, swaps it with the value in the first position, and repeats these steps for the remainder of the list. It does no more than n swaps, and thus is useful where swapping is very expensive.
The algorithm finds the minimum value, swaps it with the value in the first position, and repeats these steps for the remainder of the list. It does no more than n swaps, and thus is useful where swapping is very expensive.
Question 15 |
What is the equivalent serial schedule for the following transactions?
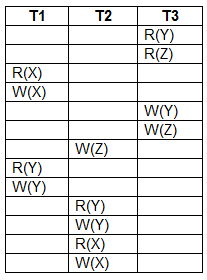
T1 − T2 − T3
| |
T3 − T1 − T2 | |
T2 − T1 − T3 | |
T1 − T3 − T2 |
Question 15 Explanation:
From the following precedence graph, T3 → T1→ T2
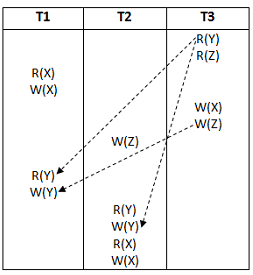
Question 16 |
Logic family popular for low power dissipation
CMOS | |
ECL | |
TTL | |
DTL |
Question 16 Explanation:
CMOS uses almost no power in the static state, i.e. when inputs are not changing. They have low energy requirements for logic transition and hence less power and heat dissipation.
Question 17 |
A context model of a software system can be shown by drawing a
LEVEL-0 DFD
| |
LEVEL-1 DFD | |
LEVEL-2 DFD | |
LEVEL-3 DFD |
Question 17 Explanation:
Explanation:
1. A data flow diagram (DFD) illustrates how data is processed by a system in terms of inputs and outputs. As its name indicates its focus is on the flow of information, where data comes from, where it goes and how it gets stored.
2. Context Diagram. A context diagram is a top level (also known as "Level 0") data flow diagram. It only contains one process node ("Process 0") that generalizes the function of the entire system in relationship to external entities.
1. A data flow diagram (DFD) illustrates how data is processed by a system in terms of inputs and outputs. As its name indicates its focus is on the flow of information, where data comes from, where it goes and how it gets stored.
2. Context Diagram. A context diagram is a top level (also known as "Level 0") data flow diagram. It only contains one process node ("Process 0") that generalizes the function of the entire system in relationship to external entities.
Question 18 |
An example of polyalphabetic substitution is
P-box | |
S-box | |
Caesar cipher | |
Vigenere cipher |
Question 18 Explanation:
A polyalphabetic cipher is any cipher based on substitution, using multiple substitution alphabets. The Vigenère cipher is probably the best-known example of a polyalphabetic cipher, though it is a simplified special case. The Enigma machine is more complex but is still fundamentally a polyalphabetic substitution cipher.
Question 19 |
If node A has three siblings and B is a parent of A, what is the degree of A?
0 | |
3 | |
4 | |
None of the above |
Question 19 Explanation:
The degree of a vertex of a graph is the number of edges incident to the vertex, and in a multigraph, loops are counted twice.
According to question, there is no information regarding children nodes of node “A”. So the degree of A is 0.
According to question, there is no information regarding children nodes of node “A”. So the degree of A is 0.
Question 20 |
The IEEE standard for WiMax technology is
IEEE 802.16 | |
IEEE 802.36 | |
IEEE 812.16 | |
IEEE 806.16 |
Question 20 Explanation:
WiMAX (Worldwide Interoperability for Microwave Access) is a family of wireless communication standards based on the IEEE 802.16 set of standards, which provide multiple physical layer (PHY) and Media Access Control (MAC) options.
There are 20 questions to complete.