UGC NET CS 2014 June-paper-2
Question 1 |
Infrared signals can be used for short range communication in a closed area using _______ propagation.
ground | |
sky | |
line of sight | |
space |
Question 1 Explanation:
Propagation methods are 3 types
1. Ground
2. Sky
3. Line of sight
1. Ground
2. Sky
3. Line of sight
Question 2 |
A bridge has access to _______ address in the same network.
Physical | |
Network | |
Datalink | |
Application |
Question 2 Explanation:
A bridge use MAC addresses (DLL layer) and router uses IP addresses (network layer). A bridge has access to physical address in the same network.
Question 3 |
The minimum frame length for 10 Mbps Ethernet is _______ bytes and maximum is _______ bytes.
64 & 128 | |
128 & 1518 | |
1518 & 3036 | |
64 & 1518 |
Question 3 Explanation:
10Base-T is the Ethernet wiring standard for 10 Mbps (megabits per second) for a maximum distance of approximately 100 meters per segment over unshielded twisted pair cables terminated with RJ-45 connectors.

Note: 100Base-T (Fast Ethernet) and 100Base-T (Gigabit Ethernet)
Note: 100Base-T (Fast Ethernet) and 100Base-T (Gigabit Ethernet)
Question 4 |
The bit rate of a signal is 3000 bps. If each signal unit carries 6 bits, the baud rate of the signal is _______.
500 baud/sec | |
1000 baud/sec | |
3000 baud/sec | |
18000 baud/sec. |
Question 4 Explanation:
→ Bit rate is nothing but number of bits transmitted per second
→ Baud rate is nothing but number of signals units transmitted per unit time.
Given data,
-- Bit rate of a signal=3000 bps
-- Each signal unit carries=6 bits
-- Baud rate=?
Step-1: Baud rate= Bit rate of signal / baud rate
= 3000/6
= 500 baud/sec
→ Baud rate is nothing but number of signals units transmitted per unit time.
Given data,
-- Bit rate of a signal=3000 bps
-- Each signal unit carries=6 bits
-- Baud rate=?
Step-1: Baud rate= Bit rate of signal / baud rate
= 3000/6
= 500 baud/sec
Question 5 |
Match the following :

a-iv, b-v, c-ii, d-iii, e-i | |
a-v, b-iv, c-i, d-ii, e-iii | |
a-i, b-iii, c-ii, d-v, e-iv | |
a-i, b-ii, c-iv, d-iii, e-v |
Question 5 Explanation:
Physical layer→ Transmission of bit stream
Data link layer→ Formation of frames
Network layer→ Move packets from one destination to other
Transport layer→ Process to process message delivery
Application Layer→ Allow resources to network access
Data link layer→ Formation of frames
Network layer→ Move packets from one destination to other
Transport layer→ Process to process message delivery
Application Layer→ Allow resources to network access
Question 6 |
A grammar G is LL(1) if and only if the following conditions hold for two distinct productions
A → α | β
- First (α) ∩ First (β) ≠ {a} where a is some terminal symbol of the grammar.
- First (α) ∩ First (β) ≠ λ
I and II | |
I and III | |
II and III | |
I, II and III |
Question 6 Explanation:
A grammar G is LL(1) if and only if the following conditions hold for two distinct productions:
A → α | β
1. First (α) and First (β) must be disjoint if none of α and β contains NULL move.
2. At most one of the strings α or β can drive NULL move i.e. α → NULL(since First (α) and First (β) are disjoint). In this case, First (β) and Follow(A) must be disjoint.
Hence the answer is option(D).
A → α | β
1. First (α) and First (β) must be disjoint if none of α and β contains NULL move.
2. At most one of the strings α or β can drive NULL move i.e. α → NULL(since First (α) and First (β) are disjoint). In this case, First (β) and Follow(A) must be disjoint.
Hence the answer is option(D).
Question 7 |
Which of the following suffices to convert an arbitrary CFG to an LL(1) grammar ?
Removing left recursion alone | |
Removing the grammar alone | |
Removing left recursion and factoring the grammar | |
None of the above |
Question 7 Explanation:
→ Left recursion removing (or) factoring the given grammar are not sufficient to convert an arbitrary CFG to an LL(1) grammar.
→ To convert an arbitrary CFG to an LL(1) grammar we need to remove the left recursion and as well as left factoring without that we cannot convert.
→ To convert an arbitrary CFG to an LL(1) grammar we need to remove the left recursion and as well as left factoring without that we cannot convert.
Question 8 |
A shift reduce parser suffers from
shift reduce conflict only | |
reduce reduce conflict only | |
both shift reduce conflict and reduce reduce conflict | |
shift handle and reduce handle conflicts |
Question 8 Explanation:
→ A shift-reduce parser scans and parses the input text in one forward pass over the text, without backing up. (That forward direction is generally left-to-right within a line, and top-to-bottom for multi-line inputs.) The parser builds up the parse tree incrementally, bottom up, and left to right, without guessing or backtracking.
A shift-reduce parser works by doing some combination of Shift steps and Reduce steps, hence the name.
→ A Shift step advances in the input stream by one symbol. That shifted symbol becomes a new single-node parse tree.
→ A Reduce step applies a completed grammar rule to some of the recent parse trees, joining them together as one tree with a new root symbol.
*** A shift reduce parser suffers from both shift reduce conflict and reduce reduce conflict.
A shift-reduce parser works by doing some combination of Shift steps and Reduce steps, hence the name.
→ A Shift step advances in the input stream by one symbol. That shifted symbol becomes a new single-node parse tree.
→ A Reduce step applies a completed grammar rule to some of the recent parse trees, joining them together as one tree with a new root symbol.
*** A shift reduce parser suffers from both shift reduce conflict and reduce reduce conflict.
Question 9 |
The context free grammar for the language L = {anbmck | k = |n – m|,
n ≥ 0, m ≥ 0, k ≥ 0} is
S → S1S3, S1 → aS1c | S2| λ,
S2 → aS2b|λ, S3 → aS3b| S4 | λ,
S4 → bS4c|λ | |
S → S1S3, S1→ aS1S2c | λ,
S2 → aS2b|λ, S3 → aS3b| S4 |λ,
S4 → bS4c|λ | |
S → S1|S2, S1→ aS1S2c | λ,
S2 → aS2b | λ, S3 → aS3b | S4 |λ,
S4 → bS4c|λ | |
S → S1 | S3, S1→ aS1c|S2 | λ,
S2 → aS2b | λ, S3 → a S3b| S4 | λ,
S4 → bS4c | λ |
Question 9 Explanation:
L = { λ, ab, ac, bc, aabb,aabc,aac, bbc, ........}
Option(A): Option(A) will generate the string "acab" which does not belongs to the sequence anbmck . So, it is not the context free grammar for the language L.
Option(B): Option(B) will generate the string "acab" which does not belongs to the sequence anbmck. So, it is not the context free grammar for the language L. Option(C): In this option production S3 and S4 are unreachable so it is not the context free grammar for the language L. Option (D): The grammar given in this option can generate { λ, ab, ac, bc, aabb,aabc,aac, bbc, ........}. So it is the context free grammar for the language L.
Option(A): Option(A) will generate the string "acab" which does not belongs to the sequence anbmck . So, it is not the context free grammar for the language L.
Option(B): Option(B) will generate the string "acab" which does not belongs to the sequence anbmck. So, it is not the context free grammar for the language L. Option(C): In this option production S3 and S4 are unreachable so it is not the context free grammar for the language L. Option (D): The grammar given in this option can generate { λ, ab, ac, bc, aabb,aabc,aac, bbc, ........}. So it is the context free grammar for the language L.
Question 10 |
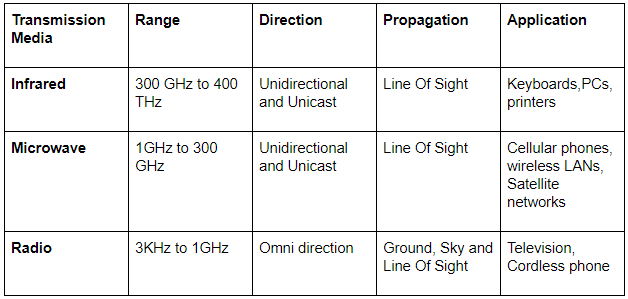
The regular grammar for the language
L = {w|na(w) and nb(w) are both even,
w ∈ {a, b}*} is given by :
(Assume, p, q, r and s are states)
L = {w|na(w) and nb(w) are both even,
w ∈ {a, b}*} is given by :
(Assume, p, q, r and s are states)
p → aq | br | λ, q → bs | ap r → as | bp, s → ar | bq, p and s are initial and final states. | |
p → aq | br, q → bs | ap r → as | bp, s → ar | bq, p and s are initial and final states. | |
p → aq | br | λ, q → bs | ap r → as | bp, s → ar | bq p is both initial and final states. | |
p → aq | br, q → bs | ap r → as | bp, s → ar | bq p is both initial and final states |
Question 10 Explanation:
L={ λ. ab, λab, λaabb, aabb, ..........}
Option (A): The grammar given in this option does not contain a state which is accepting a terminal "λ" , having zero number of "a" and "b". Since the grammar is not accepting λ so it not the regular grammar for the given language L.
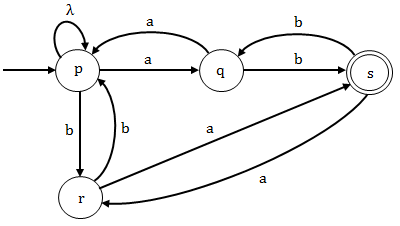
Option (B): The grammar given in this option is not generating any string "λ" which is having zero number of "a" and "b". Since the grammar is not generating λ so it not the regular grammar for the given language L.
Option (C): Here state "p" is the initial and final state and the grammar given here is generating string "λ" , having zero number of "a" and "b". Since the grammar is accepting λ so it is the regular grammar for the given language L.
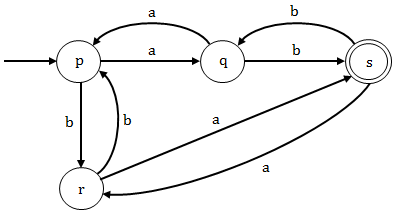
Option (D): In this option (p) is the initial and final state but the grammar is not generating any string "λ" which also belongs to the given language L. So this grammar is not the regular grammar for the given language L.
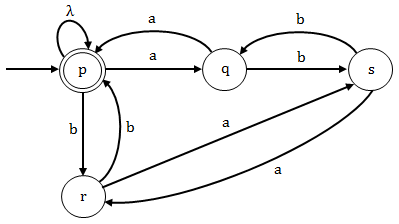
Option (A): The grammar given in this option does not contain a state which is accepting a terminal "λ" , having zero number of "a" and "b". Since the grammar is not accepting λ so it not the regular grammar for the given language L.
Option (B): The grammar given in this option is not generating any string "λ" which is having zero number of "a" and "b". Since the grammar is not generating λ so it not the regular grammar for the given language L.
Option (C): Here state "p" is the initial and final state and the grammar given here is generating string "λ" , having zero number of "a" and "b". Since the grammar is accepting λ so it is the regular grammar for the given language L.
Option (D): In this option (p) is the initial and final state but the grammar is not generating any string "λ" which also belongs to the given language L. So this grammar is not the regular grammar for the given language L.
Question 11 |
KPA in CMM stands for
Key Process Area | |
Key Product Area | |
Key Principal Area | |
Key Performance Area |
Question 11 Explanation:
KPA(Key process area) in Capability Maturity Model(CMM):
A Process Area is a cluster of related practices in an area that, when implemented collectively, satisfy a set of goals considered important for making significant improvement in that area. All CMMI process areas are common to both continuous and staged representations.
A Process Area is a cluster of related practices in an area that, when implemented collectively, satisfy a set of goals considered important for making significant improvement in that area. All CMMI process areas are common to both continuous and staged representations.
Question 12 |
Which one of the following is not a risk management technique for managing the risk due to unrealistic schedules and budgets ?
Detailed multi source cost and schedule estimation. | |
Design cost | |
Incremental development | |
Information hiding |
Question 12 Explanation:
Information hiding is not a risk management technique for managing the risk due to unrealistic schedules and budgets.
There are 12 questions to complete.