Nielit Scientist-C 2016 march
Question 1 |
The advantage of better testing in software development is in
Waterfall model | |
Prototyping | |
Iterative | |
All of these |
Question 1 Explanation:
● Iterative development was created as a response to inefficiencies and problems found in the waterfall model. A simplified version of a typical iteration cycle in agile project management.
● The basic idea behind this method is to develop a system through repeated cycles (iterative) and in smaller portions at a time (incremental), allowing software developers to take advantage of what was learned during development of earlier parts or versions of the system. Learning comes from both the development and use of the system, where possible key steps in the process start with a simple implementation of a subset of the software requirements and iteratively enhance the evolving versions until the full system is implemented. At each iteration, design modifications are made and new functional capabilities are added.
● The basic idea behind this method is to develop a system through repeated cycles (iterative) and in smaller portions at a time (incremental), allowing software developers to take advantage of what was learned during development of earlier parts or versions of the system. Learning comes from both the development and use of the system, where possible key steps in the process start with a simple implementation of a subset of the software requirements and iteratively enhance the evolving versions until the full system is implemented. At each iteration, design modifications are made and new functional capabilities are added.
Question 2 |
The file manager is responsible for
naming files | |
saving files | |
deleting files | |
all the above |
Question 2 Explanation:
● A file manager is a software program that helps a user manage all the files on their computer. For example, all file managers allow the user to view, edit, copy, and delete the files on their computer storage devices.
● Note: Although a file manager helps the user view and manage their files, it is the operating system that is responsible for accessing and storing the files on a storage device.
● Note: Although a file manager helps the user view and manage their files, it is the operating system that is responsible for accessing and storing the files on a storage device.
Question 3 |
Every Boyce-Codd Normal Form(BCNF) decomposition is
dependency preserving | |
not dependency preserving | |
need not be dependency preserving | |
none of these |
Question 3 Explanation:
Normalization requires definitely loss less decomposition but not dependency preserving. But BCNF need to be functional dependency.
Question 4 |
A functional dependency of the form x → y is trivial if
y ⊆ x | |
y ⊂ x | |
x ⊆ y | |
x ⊂ y and y ⊂ x |
Question 4 Explanation:
Trivial − If a functional dependency (FD) X → Y holds, where Y is a subset of X, then it is called a trivial FD. Trivial FDs always hold.
Question 5 |
A primary key, if combined with a foreign key creates
parent child relationship between the tables that connect them | |
many-to-many relationship between the tables that connect them | |
network model between the tables connect them | |
none of these |
Question 5 Explanation:
Using the two relationships mother and father provides us a record of a child’s mother, even if we are not aware of the father’s identity; a null value would be required if the ternary relationship parent is used. Using binary relationship sets is preferable in this case.
Question 6 |
Memory mapped displays
are utilized for high resolution graphics such as maps | |
uses ordinary memory to store the display data in character form | |
stores the display data as individual bits | |
are associated with electromechanical teleprinters |
Question 6 Explanation:
● Graphs can be displayed on a screen by writing character values into a special area of RAM within the video controller.
● Prior to cheap RAM that enabled bit-mapped displays, this character cell method was a popular technique for computer video displays.
Question 7 |
In real time operating systems, which of the following is the most suitable scheduling scheme?
Round Robin | |
First come first serve | |
preemptive | |
random scheduling |
Question 7 Explanation:
● A real-time operating system (RTOS) is any operating system (OS) intended to serve real-time applications that process data as it comes in, typically without buffer delays.
● Processing time requirements (including any OS delay) are measured in tenths of seconds or shorter increments of time.
● A real time system is a time bound system which has well defined fixed time constraints. Processing must be done within the defined constraints or the system will fail. They either are event driven or time sharing.
● Event driven systems switch between tasks based on their priorities while time sharing systems switch the task based on clock interrupts. Most RTOS’s use a pre-emptive scheduling algorithm.
● Processing time requirements (including any OS delay) are measured in tenths of seconds or shorter increments of time.
● A real time system is a time bound system which has well defined fixed time constraints. Processing must be done within the defined constraints or the system will fail. They either are event driven or time sharing.
● Event driven systems switch between tasks based on their priorities while time sharing systems switch the task based on clock interrupts. Most RTOS’s use a pre-emptive scheduling algorithm.
Question 8 |
If there are 32 segments, each of size 1 K byte, then the logical address should have
13 bits | |
14 bits | |
15 bits | |
16 bits |
Question 8 Explanation:
There are 32 segments which is equal to 25
Each segment size 1K byte =2 10
Then total number of bits that logical address consists is 15 bits.
Each segment size 1K byte =2 10
Then total number of bits that logical address consists is 15 bits.
Question 9 |
Which of the following can be accessed by transfer vector approach of linking?
External data segments | |
External subroutines | |
data located in other procedure | |
All of these |
Question 9 Explanation:
● The transfer vector approach is straightforward, but requires additional memory at execution time for the transfer vector and additional time due to the indirect references. Indexing or indirection on externals may not occur correctly with the transfer vector approach.
● Data segment stores program data. This data could be in form of initialized or uninitialized variables, and it could be local or global.
● External subroutines are routines/procedures that are created and maintained separately from the program that will be calling them
● Data segment stores program data. This data could be in form of initialized or uninitialized variables, and it could be local or global.
● External subroutines are routines/procedures that are created and maintained separately from the program that will be calling them
Question 10 |
Relocation bits used by relocating loader are specified by
relocating loader itself | |
Linker | |
Assembler | |
Macro Processor |
Question 10 Explanation:
● A linker or link editor is a computer utility program that takes one or more object files generated by a compiler and combines them into a single executable file, library file, or another 'object' file.
● Relocating loader in which some of the addresses in the program to be loaded are expressed relative to the start of the program rather than in absolute form.
● An assembler is a type of computer program that interprets software programs written in assembly language into machine language, code and instructions that can be executed by a computer.
● A macro processor is a program that copies a stream of text from one place to another, making a systematic set of replacements as it does so. Macro processors are often embedded in other programs, such as assemblers and compilers. Sometimes they are standalone programs that can be used to process any kind of text.
● Relocating loader in which some of the addresses in the program to be loaded are expressed relative to the start of the program rather than in absolute form.
● An assembler is a type of computer program that interprets software programs written in assembly language into machine language, code and instructions that can be executed by a computer.
● A macro processor is a program that copies a stream of text from one place to another, making a systematic set of replacements as it does so. Macro processors are often embedded in other programs, such as assemblers and compilers. Sometimes they are standalone programs that can be used to process any kind of text.
Question 11 |
The most powerful parser is
SLR | |
LALR | |
Canonical LR | |
Operator Precedence |
Question 11 Explanation:
Canonical LR is more powerful than SLR as every grammar which can be parsed by SLR parser, can also be parsed by CLR parser.
So CLR > LALR > SLR
In computer science, a canonical LR parser or LR(1) parser is an LR(k) parser for k=1, i.e. with a single lookahead terminal. The special attribute of this parser is that any LR(k) grammar with k>1 can be transformed into an LR(1) grammar.However, back-substitutions are required to reduce k and as back-substitutions increase, the grammar can quickly become large, repetitive and hard to understand. LR(k) can handle all deterministic context-free languages.
So CLR > LALR > SLR
In computer science, a canonical LR parser or LR(1) parser is an LR(k) parser for k=1, i.e. with a single lookahead terminal. The special attribute of this parser is that any LR(k) grammar with k>1 can be transformed into an LR(1) grammar.However, back-substitutions are required to reduce k and as back-substitutions increase, the grammar can quickly become large, repetitive and hard to understand. LR(k) can handle all deterministic context-free languages.
Question 12 |
YACC builds up
SLR parsing table | |
Canonical LR parsing table | |
LALR parsing table | |
None of these |
Question 12 Explanation:
● YACC (Yet Another Compiler-Compiler) is a computer program.
● It is a Look Ahead Left-to-Right (LALR) parser generator, generating a parser, the part of a compiler that tries to make syntactic sense of the source code, specifically a LALR parser, based on an analytic grammar written in a notation similar to Backus–Naur Form (BNF)
● It is a Look Ahead Left-to-Right (LALR) parser generator, generating a parser, the part of a compiler that tries to make syntactic sense of the source code, specifically a LALR parser, based on an analytic grammar written in a notation similar to Backus–Naur Form (BNF)
Question 13 |
Context free grammar can be recognized by
finite state automaton | |
2-way linear bounded automata | |
pushdown automata | |
Both (B) and (C) |
Question 13 Explanation:
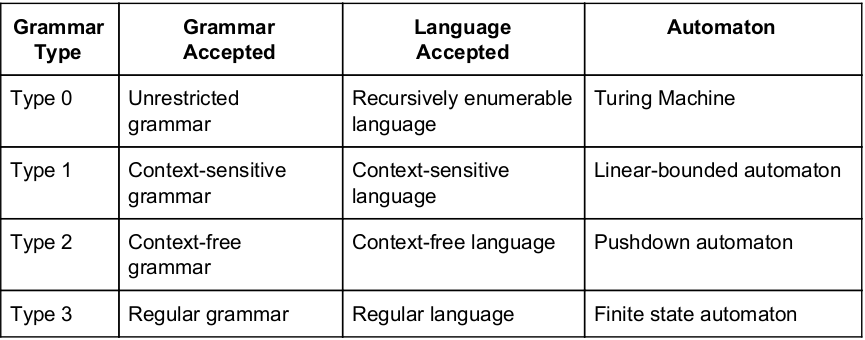
Question 14 |
If every string of a language can be determined, whether it is legal or illegal in finite time, the language is called
Decidable | |
Undecidable | |
interpretive | |
non-deterministic |
Question 14 Explanation:
● A decision problem is a function that associates with each input instance of the problem a truth value true or false.
● A decision problem is decidable if there exists a decision algorithm for it. Otherwise it is undecidable.
● For simple machine models, such as finite automata or pushdown automata, many decision problems are solvable. In the case of deterministic finite automata, problems like equivalence can be solved even in polynomial time
● A decision problem is decidable if there exists a decision algorithm for it. Otherwise it is undecidable.
● For simple machine models, such as finite automata or pushdown automata, many decision problems are solvable. In the case of deterministic finite automata, problems like equivalence can be solved even in polynomial time
Question 15 |
The defining language for developing a formalism in which language definitions can be stated, is called
Syntactic meta language | |
Decidable language | |
Intermediate language | |
High level language |
Question 15 Explanation:
● A high-level language is any programming language that enables development of a program in a much more user-friendly programming context and is generally independent of the computer's hardware architecture.
● Intermediate language (IL) is an object-oriented programming language designed to be used by compilers for the .NET Framework before static or dynamic compilation to machine code. The IL is used by the .NET Framework to generate machine-independent code as the output of compilation of the source code written in any .NET programming language.
● A language L is called Turing-decidable (or just decidable), if there exists a Turing Machine M such that on input x, M accepts if x ∈ L, and M rejects otherwise. L is called undecidable if it is not decidable.
● From the perspective of a syntactic meta language the grammatical sentences are a certain subset of the set of all possible strings of primitive symbols and the transformation rules depict certain relations between such strings of symbols
● Intermediate language (IL) is an object-oriented programming language designed to be used by compilers for the .NET Framework before static or dynamic compilation to machine code. The IL is used by the .NET Framework to generate machine-independent code as the output of compilation of the source code written in any .NET programming language.
● A language L is called Turing-decidable (or just decidable), if there exists a Turing Machine M such that on input x, M accepts if x ∈ L, and M rejects otherwise. L is called undecidable if it is not decidable.
● From the perspective of a syntactic meta language the grammatical sentences are a certain subset of the set of all possible strings of primitive symbols and the transformation rules depict certain relations between such strings of symbols
Question 16 |
In propositional logic, which of the following is equivalent to p → q?
~p → q | |
~p V q | |
~p V ~q | |
p → ~q |
Question 16 Explanation:
We can use a truth table to determine if two compound propositions are logically equivalent, i.e if they always have the same truth values.
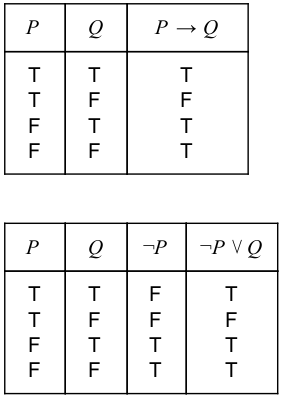
There are 16 questions to complete.