UGC NET CS 2015 Jun- paper-2
Question 1 |
How many strings of 5 digits have the property that the sum of their digits is 7?
66 | |
330 | |
495 | |
99 |
Question 1 Explanation:
→ From the given question, there should be string with 5 digits and sum of that digits should be 7
→ There is no specification about positive,negative digits and also repetition of digits.
→ We are assuming the positive digits which is greater than or equal to 0.
→ The starting digit of the string should not be zero. We will also consider the repetition of digits.
→ Example of such strings are 70000,61000,60100,60010..,
→ The possible number of strings are C((n+r-1),(r-1))
→ From the given data n=7,r=5 then We have to fine C(11,4) which is equal to 330
→ There is no specification about positive,negative digits and also repetition of digits.
→ We are assuming the positive digits which is greater than or equal to 0.
→ The starting digit of the string should not be zero. We will also consider the repetition of digits.
→ Example of such strings are 70000,61000,60100,60010..,
→ The possible number of strings are C((n+r-1),(r-1))
→ From the given data n=7,r=5 then We have to fine C(11,4) which is equal to 330
Question 2 |
Consider an experiment of tossing two fair dice, one black and one red. What is the probability that the number on the black die divides the number on red die?
22 / 36 | |
12 / 36 | |
14 / 36 | |
6 / 36 |
Question 2 Explanation:
→ From the given data, there are two dice and each dice the possible ways are 6. So total possible ways are 6*6=36 ways.
→ The possible ways are 1,2,3,4,5,6
→ The possible ways of one number divides another number are (1,1) (1,2), (1,3), (1,4), (1,5), (1,6), (2,2), (2,4), (2,6), (3,3), (3,6), (4,4), (5,5) and (6,6).
→ The probability is the number of outcomes / total outcomes = 14/36
→ The possible ways are 1,2,3,4,5,6
→ The possible ways of one number divides another number are (1,1) (1,2), (1,3), (1,4), (1,5), (1,6), (2,2), (2,4), (2,6), (3,3), (3,6), (4,4), (5,5) and (6,6).
→ The probability is the number of outcomes / total outcomes = 14/36
Question 3 |
In how many ways can 15 indistinguishable fish be placed into 5 different ponds, so that each pond contains at least one fish ?
1001 | |
3876 | |
775 | |
200 |
Question 3 Explanation:
→ We know that if we have “n” identical items which will be distributed in “r” distinct groups where each must get at least one then the number of way is C(n−1,r−1)
→ From the given question, n=15, r=5 We need to calculate C(14,4) and it’s value is 1001.
→ From the given question, n=15, r=5 We need to calculate C(14,4) and it’s value is 1001.
Question 4 |
Consider the following statements:
(a) Depth first search is used to traverse a rooted tree.
(b) Preorder, Postorder and Inorder are used to list the vertices of an ordered rooted tree.
(c) Huffman’s algorithm is used to find an optimal binary tree with given weights.
(d) Topological sorting provides a labelling such that the parents have larger labels than their children.
Which of the above statements are true?
(a) Depth first search is used to traverse a rooted tree.
(b) Preorder, Postorder and Inorder are used to list the vertices of an ordered rooted tree.
(c) Huffman’s algorithm is used to find an optimal binary tree with given weights.
(d) Topological sorting provides a labelling such that the parents have larger labels than their children.
Which of the above statements are true?
(a) and (b) | |
(c) and (d) | |
(a), (b) and (c) | |
(a), (b), (c) and (d) |
Question 4 Explanation:
→ Preorder, Postorder and Inorder are traversing techniques where all the nodes of the tree will be traversed from the root node.
→ Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking.
→ The optimal binary tree, which has minimum weighted path length when the characters of the alphabet are stored at its n terminal nodes.An optimal binary tree generates what is called a Huffman code
→ A topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks.
A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time.
→ Depth-first search (DFS) is an algorithm for traversing or searching tree or graph data structures. The algorithm starts at the root node (selecting some arbitrary node as the root node in the case of a graph) and explores as far as possible along each branch before backtracking.
→ The optimal binary tree, which has minimum weighted path length when the characters of the alphabet are stored at its n terminal nodes.An optimal binary tree generates what is called a Huffman code
→ A topological sort or topological ordering of a directed graph is a linear ordering of its vertices such that for every directed edge uv from vertex u to vertex v, u comes before v in the ordering. For instance, the vertices of the graph may represent tasks to be performed, and the edges may represent constraints that one task must be performed before another; in this application, a topological ordering is just a valid sequence for the tasks.
A topological ordering is possible if and only if the graph has no directed cycles, that is, if it is a directed acyclic graph (DAG). Any DAG has at least one topological ordering, and algorithms are known for constructing a topological ordering of any DAG in linear time.
Question 5 |
Consider a Hamiltonian Graph (G) with no loops and parallel edges. Which of the following is true with respect to this Graph (G) ?
(a) deg (v) ≥ n / 2 for each vertex of G
(b) |E(G)| ≥ 1 / 2 (n - 1) (n - 2) + 2 edges
(c) deg (v) + deg (w) ≥ n for every n and v not connected by an edge.
(a) deg (v) ≥ n / 2 for each vertex of G
(b) |E(G)| ≥ 1 / 2 (n - 1) (n - 2) + 2 edges
(c) deg (v) + deg (w) ≥ n for every n and v not connected by an edge.
(a) and (b) | |
(b) and (c) | |
(a) and (c) | |
(a), (b) and (c) |
Question 5 Explanation:
→ According to Dirac's theorem on Hamiltonian cycles, the statement that an n-vertex graph in which each vertex has degree at least n/2 must have a Hamiltonian cycle.
→ According to ore’s theorem,Let G be a (finite and simple) graph with n ≥ 3 vertices. We denote by deg v the degree of a vertex v in G, i.e. the number of incident edges in G to v. Then, Ore's theorem states that if deg v + deg w ≥ n for every pair of distinct non adjacent vertices v and w of G, then G is Hamiltonian.
→ A complete graph G of n vertices has n(n−1)/2 edges and a Hamiltonian cycle in G contains n edges. Therefore the number of edge-disjoint Hamiltonian cycles in G cannot exceed (n − 1)/2. When n is odd, we show there are (n − 1)/2 edge-disjoint Hamiltonian cycles.
So the statement(b) is false and statement a and c are true.
→ According to ore’s theorem,Let G be a (finite and simple) graph with n ≥ 3 vertices. We denote by deg v the degree of a vertex v in G, i.e. the number of incident edges in G to v. Then, Ore's theorem states that if deg v + deg w ≥ n for every pair of distinct non adjacent vertices v and w of G, then G is Hamiltonian.
→ A complete graph G of n vertices has n(n−1)/2 edges and a Hamiltonian cycle in G contains n edges. Therefore the number of edge-disjoint Hamiltonian cycles in G cannot exceed (n − 1)/2. When n is odd, we show there are (n − 1)/2 edge-disjoint Hamiltonian cycles.
So the statement(b) is false and statement a and c are true.
Question 6 |
Consider the following statements :
(a)Boolean expressions and logic networks correspond to labelled acyclic digraphs.
(b)Optimal boolean expressions may not correspond to simplest networks.
(c)Choosing essential blocks first in a Karnaugh map and then greedily choosing the largest remaining blocks to cover may not give an optimal expression.
Which of these statement(s) is/are correct ?
(a)Boolean expressions and logic networks correspond to labelled acyclic digraphs.
(b)Optimal boolean expressions may not correspond to simplest networks.
(c)Choosing essential blocks first in a Karnaugh map and then greedily choosing the largest remaining blocks to cover may not give an optimal expression.
Which of these statement(s) is/are correct ?
(a) only | |
(b) only | |
(a) and (b) | |
(a), (b) and (c) |
Question 6 Explanation:
→ An acyclic digraph is a directed graph containing no directed cycles, also known as a directed acyclic graph or a "DAG.",We can represent the boolean expressions and logic networks by using DAG.
→ Karnaugh maps reduce logic functions more quickly and easily compared to Boolean algebra. By reduce we mean simplify, reducing the number of gates and inputs.
→ Karnaugh maps reduce logic functions more quickly and easily compared to Boolean algebra. By reduce we mean simplify, reducing the number of gates and inputs.
Question 7 |
Consider a full - adder with the following input values:
(a)x = 1, y = 0 and C i (carry input) = 0
(b)x = 0, y = 1 and C i = 1 Compute the values of S(sum) and C o (carry output) for the above input values.
(a)x = 1, y = 0 and C i (carry input) = 0
(b)x = 0, y = 1 and C i = 1 Compute the values of S(sum) and C o (carry output) for the above input values.
S = 1, C o = 0 and S = 0, C o = 1 | |
S = 1, C o = 0 and S = 1, C o = 1 | |
S = 1, C o = 1 and S = 1, C o = 0 | |
S0 = 1, C o = 1 and S = 1, C o = 0 |
Question 7 Explanation:

For the given x and y values, the correct option is A
Question 8 |
“If my computations are correct and I pay the electric bill, then I will run out of money. If I don’t pay the electric bill, the power will be turned off. Therefore, if I don’t run out of money and the power is still on, then my computations are incorrect.”
Convert this argument into logical notations using the variables c, b, r, p for propositions of computations, electric bills, out of money and the power respectively. (Where ¬ means NOT)
if (c Λ b)→r and ¬b→p, then (¬r Λ p)→¬c | |
if (c ∨ b)→r and ¬b→¬p, then (r Λ p)→c | |
if (c Λ b)→r and ¬p→b, then (¬r ∨ p)→¬c | |
if (c ∨ b)→r and ¬b→¬p, then (¬r Λ p)→¬c |
Question 8 Explanation:
We can represent ,
“c” for my computations are correct
“b” for I pay the electric bill.
“r” for I will run out of money
“p” for the power is on.
(c Λ b) means my computations are correct and I pay the electric bill.
(¬r Λ p) means I don’t run out of money and the power is still on.
According to the statement , the option -(A) is correct.
“c” for my computations are correct
“b” for I pay the electric bill.
“r” for I will run out of money
“p” for the power is on.
(c Λ b) means my computations are correct and I pay the electric bill.
(¬r Λ p) means I don’t run out of money and the power is still on.
According to the statement , the option -(A) is correct.
Question 9 |
Match the following:
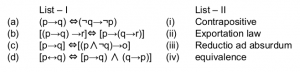
(a)-(i), (b)-(ii), (c)-(iii), (d)-(iv) | |
(a)-(ii), (b)-(iii), (c)-(i), (d)-(iv) | |
(a)-(iii), (b)-(ii), (c)-(iv), (d)-(i) | |
(a)-(iv), (b)-(ii), (c)-(iii), (d)-(i) |
Question 9 Explanation:
→ In logic, contraposition is an inference that says that a conditional statement is logically equivalent to its contrapositive. The contrapositive of the statement has its antecedent and consequent inverted and flipped: the contrapositive of P → Q is thus as ~Q → ~P.
→ The equivalence relation translates verbally into "if and only if" and is symbolized by a double-lined, double arrow pointing to the left and right (↔). If A and B represent statements, then A ↔ B means "A if and only if B."
→ The exportation rule is a rule in logic which states that "if (P and Q), then R" is equivalent to "if P then (if Q then R)".
→ The exportation rule may be formally stated as: (P ∧ Q) → R is equivalent to P → (Q →R)
→ A mode of argumentation or a form of argument in which a proposition is disproven by following its implications logically to an absurd conclusion. Arguments that use universals such as, “always”, “never”, “everyone”, “nobody”, etc., are prone to being reduced to absurd conclusions. The fallacy is in the argument that could be reduced to absurdity -- so in essence, reductio ad absurdum is a technique to expose the fallacy.
→ The equivalence relation translates verbally into "if and only if" and is symbolized by a double-lined, double arrow pointing to the left and right (↔). If A and B represent statements, then A ↔ B means "A if and only if B."
→ The exportation rule is a rule in logic which states that "if (P and Q), then R" is equivalent to "if P then (if Q then R)".
→ The exportation rule may be formally stated as: (P ∧ Q) → R is equivalent to P → (Q →R)
→ A mode of argumentation or a form of argument in which a proposition is disproven by following its implications logically to an absurd conclusion. Arguments that use universals such as, “always”, “never”, “everyone”, “nobody”, etc., are prone to being reduced to absurd conclusions. The fallacy is in the argument that could be reduced to absurdity -- so in essence, reductio ad absurdum is a technique to expose the fallacy.
Question 10 |
Consider a proposition given as :
“ x ≥ 6, if x 2 ≥ 5 and its proof as:
If x ≥ 6, then x 2 = x.x ≥ 6.6 = 36 ≥ 25
Which of the following is correct w.r.to the given proposition and its proof?
(a)The proof shows the converse of what is to be proved.
(b)The proof starts by assuming what is to be shown.
(c)The proof is correct and there is nothing wrong.
“ x ≥ 6, if x 2 ≥ 5 and its proof as:
If x ≥ 6, then x 2 = x.x ≥ 6.6 = 36 ≥ 25
Which of the following is correct w.r.to the given proposition and its proof?
(a)The proof shows the converse of what is to be proved.
(b)The proof starts by assuming what is to be shown.
(c)The proof is correct and there is nothing wrong.
(a) only | |
(c) only | |
(a) and (b) | |
(b) only |
Question 10 Explanation:
The proof which is described in the question is wrong because for a given “x” value , x 2 >=5 but in the proof they mentioned 36>=25 which is wrong.
Question 11 |
What is the output of the following program?
(Assume that the appropriate preprocessor directives are included and there is no syntax error)
main( )
{
char S[ ] = "ABCDEFGH";
printf ("%C", *(&S[3]));
printf ("%s", S+4);
printf ("%u", S);
/* Base address of S is 1000 */
}
(Assume that the appropriate preprocessor directives are included and there is no syntax error)
main( )
{
char S[ ] = "ABCDEFGH";
printf ("%C", *(&S[3]));
printf ("%s", S+4);
printf ("%u", S);
/* Base address of S is 1000 */
}
ABCDEFGH1000 | |
CDEFGH1000 | |
DDEFGHH1000 | |
DEFGH1000 |
Question 11 Explanation:
Step-1: String is stored in appropriate location is

Step-2: printf ("%C", *(&S[3]));
This statement will print character ‘D’
(&S[3]) → Will print address of index 3
*(&S[3]) → will print value in index 3. The value is nothing but ‘D’.
Step-3: printf ("%s", S+4); /* will print characters ‘EFGH’ */
Because previous S value index position is 3. Now we are performing +4 operations. It will print EFGH. we are given escape sequence is String.
Step-4: printf ("%u", S); → It will print address of S. The base address given as S is 1000.
Step-2: printf ("%C", *(&S[3]));
This statement will print character ‘D’
(&S[3]) → Will print address of index 3
*(&S[3]) → will print value in index 3. The value is nothing but ‘D’.
Step-3: printf ("%s", S+4); /* will print characters ‘EFGH’ */
Because previous S value index position is 3. Now we are performing +4 operations. It will print EFGH. we are given escape sequence is String.
Step-4: printf ("%u", S); → It will print address of S. The base address given as S is 1000.
Question 12 |
Which of the following, in C++, is inherited in a derived class from base class ?
constructor | |
destructor | |
data members | |
virtual methods |
Question 12 Explanation:
Data members in C++, is inherited in a derived class from base class.
→ When creating a class, instead of writing completely new data members and member functions, the programmer can designate that the new class should inherit the members of an existing class. This existing class is called the base class, and the new class is referred to as the derived class.
→ A derived class can access all the non-private members of its base class. Thus base-class members that should not be accessible to the member functions of derived classes should be declared private in the base class.
→ When creating a class, instead of writing completely new data members and member functions, the programmer can designate that the new class should inherit the members of an existing class. This existing class is called the base class, and the new class is referred to as the derived class.
→ A derived class can access all the non-private members of its base class. Thus base-class members that should not be accessible to the member functions of derived classes should be declared private in the base class.
There are 12 questions to complete.