Nielit STA [02-12-2018]
Question 1 |
Which register that shift complete binary number in one bit at a time and shift all the stored bits out at a time?
Parallel-in parallel-out | |
Parallel-in Serial-out | |
Serial-in parallel-out | |
Serial-in Serial-out |
Question 1 Explanation:
SIPO is the register is loaded with serial data, one bit at a time, with the stored data being available at the output in parallel form.
SIPO:
A serial-in, parallel-out shift register is similar to the serial-in, serial-out shift register in that it shifts data into internal storage elements and shifts data out at the serial-out, data-out, pin. It is different in that it makes all the internal stages available as outputs. Therefore, a serial-in, parallel-out shift register converts data from serial format to parallel format.
More Information
Serial-in to Serial-out (SISO) - the data is shifted serially “IN” and “OUT” of the register, one bit at a time in either a left or right direction under clock control.
Parallel-in to Serial-out (PISO) - the parallel data is loaded into the register simultaneously and is shifted out of the register serially one bit at a time under clock control.
Parallel-in to Parallel-out (PIPO) - the parallel data is loaded simultaneously into the register, and transferred together to their respective outputs by the same clock pulse.
SIPO:
A serial-in, parallel-out shift register is similar to the serial-in, serial-out shift register in that it shifts data into internal storage elements and shifts data out at the serial-out, data-out, pin. It is different in that it makes all the internal stages available as outputs. Therefore, a serial-in, parallel-out shift register converts data from serial format to parallel format.
More Information
Serial-in to Serial-out (SISO) - the data is shifted serially “IN” and “OUT” of the register, one bit at a time in either a left or right direction under clock control.
Parallel-in to Serial-out (PISO) - the parallel data is loaded into the register simultaneously and is shifted out of the register serially one bit at a time under clock control.
Parallel-in to Parallel-out (PIPO) - the parallel data is loaded simultaneously into the register, and transferred together to their respective outputs by the same clock pulse.
Question 2 |
Which among the following algorithm can’t be used with linked list?
Binary search | |
Linear Search | |
Insertion sort | |
Merge Sort |
Question 2 Explanation:
→ Binary search increases the traversal steps per element in linked list just to find the middle element. This makes it slow and inefficient. Whereas the binary search on an array is fast and efficient because of its ability to access any element in the array in constant time.
→ Merge sort is often preferred for sorting a linked list. The slow random-access performance of a linked list makes some other algorithms (such as quicksort) perform poorly, and others (such as heapsort) completely impossible.
→ Insertion sort & Linear search can use linked list. Note:But Binary search also can implement using linked list but it takes O(n) time complexity.
→ Merge sort is often preferred for sorting a linked list. The slow random-access performance of a linked list makes some other algorithms (such as quicksort) perform poorly, and others (such as heapsort) completely impossible.
→ Insertion sort & Linear search can use linked list. Note:But Binary search also can implement using linked list but it takes O(n) time complexity.
Question 3 |
A program P reads in 1000 integers in the range [0, 100] representing the scores of 500 students. It then prints the frequency of each score above 50. What would be the best way for P to store the frequencies?
An array of 50 numbers | |
An array of 100 numbers | |
An array of 500 numbers | |
A dynamically allocated array of 550 numbers |
Question 3 Explanation:
→ Here we are storing values above 50 and we are ignoring the scores which is less than 50.
→ Then using array of 50 numbers is the best way to store the frequencies.
→ Then using array of 50 numbers is the best way to store the frequencies.
Question 4 |
In a risk based approach the risks identified mayn’t be used to:
Determine the test technique to be employed | |
Determine the extent of testing to be carried out | |
Prioritize testing in an attempt to find critical defects as early as possible | |
Determine the cost of the project |
Question 4 Explanation:
Risk identification is the process of determining risks that could potentially prevent the program, enterprise, or investment from achieving its objectives. It includes documenting and communicating the concern.
Tasks of risk identification:
1. Determine the test technique to be employed
2. Determine the extent of testing to be carried out
3. Prioritize testing in an attempt to find critical defects as early as possible
Tasks of risk identification:
1. Determine the test technique to be employed
2. Determine the extent of testing to be carried out
3. Prioritize testing in an attempt to find critical defects as early as possible
Question 5 |
Simple network management protocol(SNMP) is a protocol that runs on:
Application layer | |
Transport layer | |
Network layer | |
Data link layer |
Question 5 Explanation:
→ Simple Network Management Protocol (SNMP) is an Internet Standard protocol for collecting and organizing information about managed devices on IP networks and for modifying that information to change device behavior. Devices that typically support SNMP include cable modems, routers, switches, servers, workstations, printers, and more.
→ SNMP is a component of the Internet Protocol Suite as defined by the Internet Engineering Task Force (IETF). It consists of a set of standards for network management, including an application layer protocol, a database schema, and a set of data objects.
→ SNMP is a component of the Internet Protocol Suite as defined by the Internet Engineering Task Force (IETF). It consists of a set of standards for network management, including an application layer protocol, a database schema, and a set of data objects.
Question 6 |
In a database system, the domain integrity is not defined by:
The data type and the length | |
The NULL value rejection | |
The allowable values, through techniques like constraints or rules | |
Default value |
Question 6 Explanation:
A domain defines the possible values of an attribute. Domain Integrity rules govern these values.
In a database system, the domain integrity is defined by:
1.The data type and the length
2.The NULL value acceptance
3.The allowable values, through techniques like constraints or rules
4.The default value
In a database system, the domain integrity is defined by:
1.The data type and the length
2.The NULL value acceptance
3.The allowable values, through techniques like constraints or rules
4.The default value
Question 7 |
Transformation that moves objects without deformation is called:
Rotation | |
Scaling | |
Translation | |
Morphism |
Question 7 Explanation:
→ A translation process moves every point a constant distance in a specified direction. It can be described as a rigid motion.
→ A translation can also be interpreted as the addition of a constant vector to every point, or as shifting the origin of the coordinate system.
→ A translation can also be interpreted as the addition of a constant vector to every point, or as shifting the origin of the coordinate system.
Question 8 |
Which of the following need not necessarily be saved on a context switch between processes?
Program counter | |
IO status information | |
CPU registers | |
Translation lookaside buffer |
Question 8 Explanation:
→ Actually TLB (or) Cache memory to ensure correct program resumption.
→ With TLB (or) Cache memory we can get better performance but not mandatory.
→ Program counter, stack, I/O status information and registers must be saved on a context switch between processes.
→ With TLB (or) Cache memory we can get better performance but not mandatory.
→ Program counter, stack, I/O status information and registers must be saved on a context switch between processes.
Question 9 |
Given an random unsorted array ‘A’ in which every element is at most ‘d’ distance from is position in sorted array where d<Size(A). If we applied the insertion sort over this array, then the time complexity of algorithm is:
O(nlogd) | |
O(n2 logd) | |
O(nd) | |
O(n2d) |
Question 9 Explanation:
→ Using insertion sort worst case time complexity is O(n2).
→ They are asking to find the atmost distance from every element. So, it will take O(n2*d) from every node.
Note: Using heap sort , time complexity will be O(nlogd) and most effective than insertion sort.
→ They are asking to find the atmost distance from every element. So, it will take O(n2*d) from every node.
Note: Using heap sort , time complexity will be O(nlogd) and most effective than insertion sort.
Question 10 |
To maintain transactional integrity and database consistency DBMS will use:
Triggers | |
Cursors | |
Locks | |
Pointers |
Question 10 Explanation:
→ Locks are used to maintain transactional integrity and database consistency.
→ Concurrency control protocols can be broadly divided into two categories:
1.Lock based protocols
2.Timestamp based protocols
→ Concurrency control protocols can be broadly divided into two categories:
1.Lock based protocols
2.Timestamp based protocols
Question 11 |
The design of a class in C++ which can’t be inherited is achieved using ___ keyword before class declaration.
Final | |
Static | |
Sealed | |
Fixed |
Question 11 Explanation:
→ Final is a non-access modifier applicable only to a variable, a method or a class.
→ Final variable are used to create constant variables
→ Final methods are used to prevent method overriding
→ Final Classes are prevent inheritance
→ We make the Final class non-inheritable. When a class Derived tries to inherit from it, we get compilation error.
→ Final variable are used to create constant variables
→ Final methods are used to prevent method overriding
→ Final Classes are prevent inheritance
→ We make the Final class non-inheritable. When a class Derived tries to inherit from it, we get compilation error.
Question 12 |
CPU register to perform storage of arithmetic and logic results is called:
Instruction register | |
Program counter | |
Accumulator | |
Instruction Decoder |
Question 12 Explanation:
→ An accumulator is a register in which intermediate arithmetic and logic results are stored.
→ In a computer's central processing unit (CPU), the accumulator is a register in which intermediate arithmetic and logic results are stored. Without a register like an accumulator, it would be necessary to write the result of each calculation (addition, multiplication, shift, etc.) to main memory, perhaps only to be read right back again for use in the next operation.
→ Access to main memory is slower than access to a register like the accumulator because the technology used for the large main memory is slower (but cheaper) than that used for a register. Early electronic computer systems were often split into two groups, those with accumulators and those without.
→ In a computer's central processing unit (CPU), the accumulator is a register in which intermediate arithmetic and logic results are stored. Without a register like an accumulator, it would be necessary to write the result of each calculation (addition, multiplication, shift, etc.) to main memory, perhaps only to be read right back again for use in the next operation.
→ Access to main memory is slower than access to a register like the accumulator because the technology used for the large main memory is slower (but cheaper) than that used for a register. Early electronic computer systems were often split into two groups, those with accumulators and those without.
Question 13 |
The nature of any number i.e., positive or negative is recognized by its:
MSB | |
LSB | |
Bits | |
Nibble |
Question 13 Explanation:
This standard offers a way to code a number using 32 bits, and defines three components:
1.The plus/minus sign is represented by one bit, the highest-weighted bit (furthest to the left or MSB)
2.The exponent is encoded using 8 bits immediately after the sign
3.The mantissa (the bits after the decimal point) with the remaining 23 bits
1.The plus/minus sign is represented by one bit, the highest-weighted bit (furthest to the left or MSB)
2.The exponent is encoded using 8 bits immediately after the sign
3.The mantissa (the bits after the decimal point) with the remaining 23 bits
Question 14 |
The output of the following code is:
int main()
{
static int x[ ]={1,2,3,4,5,6,7,8}
int i;
for(i=2;i<6;++i)
x[x[i]]=x[i];
for(i=0;i<8;++i)
printf(“%d”,x[i]);
Return 0;
}
12244668 | |
11335578 | |
12335578
| |
12343676 |
Question 14 Explanation:
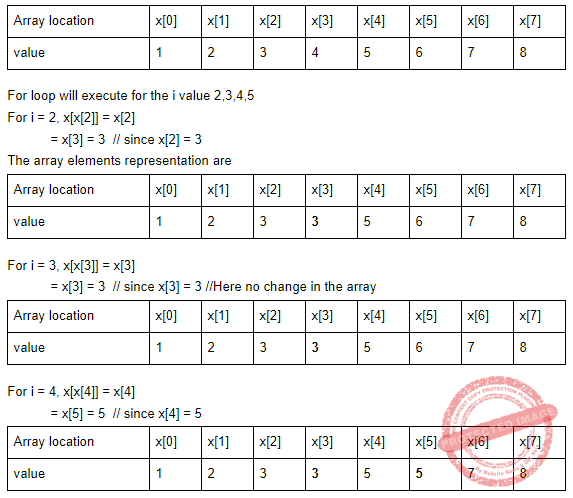
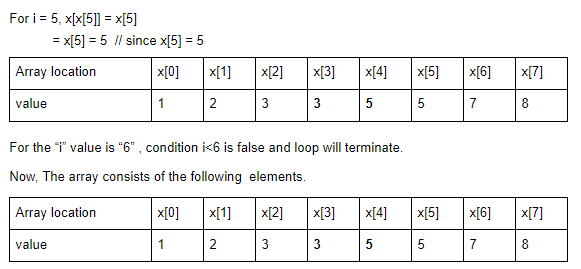
Question 15 |
Using Mid Point algorithm, the new coordinates of the point P(x,y) having slope ‘m’ and constant and ‘b’ is calculated using:
F(x,y)=mx+b-y | |
F(x,y)=mx-y+b | |
F(x,y)=mx+b | |
F(x,y)=mx-y+b-y |
Question 15 Explanation:
In order to check this, we need to consider the implicit equation:
F(x,y) = mx + b - y
For positive m at any given X,
If y is on the line, then F(x, y) = 0
If y is above the line, then F(x, y) < 0
If y is below the line, then F(x, y) > 0
F(x,y) = mx + b - y
For positive m at any given X,
If y is on the line, then F(x, y) = 0
If y is above the line, then F(x, y) < 0
If y is below the line, then F(x, y) > 0
Question 16 |
The theory of bubbled input OR gate is interchangeable with a bubbled output AND gate is demonstrated and proved by:
Karnaugh map | |
DeMorgan’s second theorem | |
The commutative law of addition | |
The associative law of multiplication |
Question 16 Explanation:

There are 16 questions to complete.