NTA UGC NET JUNE-2023 Paper-2
Question 1 |
Consider a hash table of size seven with starting index zero and a hash function(6x+3) mod 4.Assuming the hash table is initially empty.Which of the following is the content of the table when the sequence 1,3,8,10,5 is inserted into the table using closed hashing? Here "_" denotes an empty location in the table.
1,3,8,10,5,_,_
| |
3,8,1,_,10,_5
| |
_,3,8,1,_,10,5
| |
_1,3,8,10,5,_ |
Question 1 Explanation:
To insert the sequence 1, 3, 8, 10, and 5 into the hash table using closed hashing, we'll use the given hash function (6x + 3) mod 4. Here's how the table would look after each insertion:
Insert 1:
Hash value = (6 * 1 + 3) mod 4 = (6 + 3) mod 4 = 9 mod 4 = 1
Table: _, 1, _, _, _, _, _
Insert 3:
Hash value = (6 * 3 + 3) mod 4 = (18 + 3) mod 4 = 21 mod 4 = 1 (collision)
Since the slot at index 1 is already occupied, we'll perform linear probing (moving to the next slot until we find an empty one).
Table: _, 1, 3, _, _, _, _
Insert 8:
Hash value = (6 * 8 + 3) mod 4 = (48 + 3) mod 4 = 51 mod 4 = 3
Table: _, 1, 3, 8, _, _, _
Insert 10:
Hash value = (6 * 10 + 3) mod 4 = (60 + 3) mod 4 = 63 mod 4 = 3 (collision)
Linear probing again.
Table: _, 1, 3, 8, 10, _, _
Insert 5:
Hash value = (6 * 5 + 3) mod 4 = (30 + 3) mod 4 = 33 mod 4 = 1 (collision)
Linear probing.
Table: _, 1, 3, 8, 10, 5, _
So, the content of the table after inserting the sequence 1, 3, 8, 10, and 5 is:
_, 1, 3, 8, 10, 5, _
Question 2 |
The total cost of retrieving records in sorted order using an unclustered B+ tree is
(P-Average number of records per data page
N-Data pages
F-Ratio of the size of a data entry to the size of a data record)
(F*N)+P
| |
(F+P)*N
| |
F*N*P
| |
F+P/N |
Question 2 Explanation:
The total cost of retrieving records in sorted order using an unclustered B+ tree is given by:
(F + P) * N
Where:
F is the ratio of the size of a data entry to the size of a data record.
P is the average number of records per data page.
N is the number of data pages.
So, the correct answer is (F + P) * N.
Question 3 |
Which of the following statement is correct ?
1.Ackermann's function is primitive recursive
2.L={anbkcn+k:n>=0,k>=0} is regular language
3.L={anbj:n=j2} is not context free language
4.For every context sensitive language L not including LAmda, there exist some linear bounded automata M such that L != L(M))
1.Ackermann's function is primitive recursive
2.L={anbkcn+k:n>=0,k>=0} is regular language
3.L={anbj:n=j2} is not context free language
4.For every context sensitive language L not including LAmda, there exist some linear bounded automata M such that L != L(M))
1 | |
2 | |
3 | |
4 |
Question 3 Explanation:
Ackermann's function is not primitive recursive.
L=L={anbkcn+k:n>=0,k>=0} is a context-free language.
For every context-sensitive language L (not including Lambda), there exists a linear bounded automaton M such that L = L(M).
So, the correct statement is option 3.
L=L={anbkcn+k:n>=0,k>=0} is a context-free language.
For every context-sensitive language L (not including Lambda), there exists a linear bounded automaton M such that L = L(M).
So, the correct statement is option 3.
Question 4 |
What will be the output of the following code?
#include
int main(){
int a,b,c;
a=ox10;
b=o10;
c=a+b;
print("%d",c);
return 0;
}
20
| |
24
| |
Garbage
| |
Error |
Question 4 Explanation:
a is assigned the hexadecimal value 0x10, which is equivalent to 16 in decimal.
b is assigned the octal value 010, which is equivalent to 8 in decimal.
c is calculated as the sum of a and b, so c = 16 + 8, resulting in c being equal to 24.
The printf statement then prints the value of c as an integer using the %d format specifier.
As a result, the output of this corrected code is 24. The code adds the values of a and b, and it correctly displays the sum, which is 24.
Question 5 |
Which of the following concurrency control protocols ensure both conflict serializability and freedom from deadlock?
Statement I: Two phase locking
Statement II: Timestamp ordering
In the light of the above statements, choose the most appropriate answer from the options given below:
Statement I: Two phase locking
Statement II: Timestamp ordering
In the light of the above statements, choose the most appropriate answer from the options given below:
Both statement I and statement II are correct
| |
Both statement I and statement II are incorrect
| |
Statement I is correct but Statement Ii is incorrect
| |
Statement I is incorrect but Statement Ii is correct |
Question 5 Explanation:
The correct answer is "Statement I is incorrect, but Statement II is correct."
Two-phase locking (Statement I) ensures conflict serializability but does not guarantee freedom from deadlock.
Timestamp ordering (Statement II) is a protocol that ensures both conflict serializability and freedom from deadlock.
Question 6 |
At particular time of computation, the value of a counting semaphore is 7.Then 20p operations and 'x' V operations were completed on this semaphore.if the final value of semaphore is 5,x will be
15
| |
22
| |
18
| |
13 |
Question 6 Explanation:
The final value of a counting semaphore after 'p' P (wait) operations and 'v' V (signal) operations can be calculated as follows:
Final Value = Initial Value + V - P
In this case, the initial value is 7, 'p' is 20, and 'v' is x. So,
Final Value = 7 + x - 20
Given that the final value is 5, we can set up the equation:
5 = 7 + x - 20
Now, solve for 'x':
x = 5 - 7 + 20
x = 18
So, the value of 'x' is 18.
Question 7 |
Consider the following statements:
A. Dynamic metrics are collected by measurements made of a program in execution
B. Static metrics are collected by measurements made of representations of the system
C. The assessment of software quality is an objective process
D. An important part of quality assurance in the selection of standards that should apply to the software development process
Choose the correct answer from the options given below:
A. Dynamic metrics are collected by measurements made of a program in execution
B. Static metrics are collected by measurements made of representations of the system
C. The assessment of software quality is an objective process
D. An important part of quality assurance in the selection of standards that should apply to the software development process
Choose the correct answer from the options given below:
A,B,C only
| |
B,C and D only
| |
A,C and D only
| |
A,B and D only |
Question 7 Explanation:
A. Dynamic metrics are collected by measurements made of a program in execution: This statement is correct. Dynamic metrics involve measuring the behavior and performance of a software program while it is running, often by using various profiling and monitoring techniques.
B. Static metrics are collected by measurements made of representations of the system: This statement is correct. Static metrics are derived from the analysis of program representations without executing the code, such as source code or design documents.
C. The assessment of software quality is an objective process: This statement is not necessarily correct. Assessing software quality can involve both objective and subjective elements. While some aspects of quality, like adherence to coding standards, can be objectively measured, other aspects, like user satisfaction, can be more subjective.
D. An important part of quality assurance is the selection of standards that should apply to the software development process: This statement is correct. Quality assurance involves defining and implementing standards, processes, and practices to ensure that the software development process is carried out in a way that meets quality objectives.
So, the correct combination is A, B, and D
Question 8 |
Consider the following language:
L={W ε{a,b,c}*:na(ω)+nb(ω)=nc(ω)} then L is
Context free but not linear
| |
Not context free
| |
Context free and linear
| |
Linear |
Question 8 Explanation:
The language L = {w in {a, b, c}* : na(ω) + nb(ω) = nc(ω} is indeed context-free. It is not linear, but it is context-free.
Here's an example of a context-free grammar that generates this language:
S -> aSc (This rule adds one 'a' and one 'c' to the string, maintaining the balance.)
S -> bSd (This rule adds one 'b' and one 'd' to the string, maintaining the balance.)
S -> ε (This rule allows the string to be empty.)
Using this context-free grammar, you can generate strings that satisfy the condition na + nb = nc. For example:
For na = 2 and nb = 2, you can generate aacbcd.
For na = 3 and nb = 3, you can generate aabbcc.
So, the language is context-free but not linear.
Question 9 |
The following table shows the time between failures for a software:
The reliability of the system for one hour operation assuming an exponential model is
| Error number | 1 | 2 | 3 | 4 | 5 |
| Time since last failure (hour) | 6 | 4 | 8 | 5 | 6 |
The reliability of the system for one hour operation assuming an exponential model is
e -9/29
| |
e -7/29
| |
e -5/29
| |
e -3/29 |
Question 9 Explanation:
To calculate the reliability of the system for one hour of operation using an exponential model, you can use the formula:
Reliability (R) = e^(-λt)
Where:
λ (lambda) is the failure rate, which can be calculated as the reciprocal of the mean time between failures (MTBF), and
t is the time of interest, which in this case is 1 hour.
First, let's calculate λ. The MTBF is the average time between failures, which can be calculated as the sum of the time since the last failure divided by the number of failures.
MTBF = (6 + 4 + 8 + 5 + 6) / 5 = 29/5 hours
Now, calculate λ:
λ = 1 / MTBF = 5 / 29 per hour
Now, calculate the reliability for 1 hour of operation:
R = e^(-λt) = e^(-(5/29) * 1) = e^(-5/29)
So, the reliability of the system for one hour of operation assuming an exponential model is approximately e^(-5/29).
Question 10 |
A processor chip is used for application in which 30% of execution time is spent on floating point addition. For the new model of the processor, the design team has come up with redesign the floating point adder to make it twice as fast.What will be possible maximum speedup by this redesign?
2.0
| |
1.06
| |
1.18
| |
2.5
|
Question 10 Explanation:
To calculate the maximum possible speedup due to the redesign of the floating-point adder, we can use Amdahl's Law. Amdahl's Law describes the potential speedup of a system based on the portion of the computation that can be improved.
Amdahl's Law formula for speedup (S) is:
S = 1 / (1 - P + (P / F))
Where:
S is the speedup factor.
P is the fraction of the execution time that benefits from the improvement.
F is the factor by which this portion is improved.
In this case, we are given that 30% of the execution time is spent on floating-point addition, and the design team has made it twice as fast, which means F = 2. P is 0.3 (30%).
So, the possible maximum speedup by this redesign is approximately 1.18. The correct answer is 1.18.
Question 11 |
Given below are two statements: one is labelled as Assertion A and the other is labelled as Reason R
Assertion A: I/O protection is ensured by a hardware trap
Reason R: I/O interrupt caused by the condition like I/O completion and device malfunction occurring within the I/O devices
In the light of the above statements, choose the correct answer from the options given below
Assertion A: I/O protection is ensured by a hardware trap
Reason R: I/O interrupt caused by the condition like I/O completion and device malfunction occurring within the I/O devices
In the light of the above statements, choose the correct answer from the options given below
Both A and R are correct and R is the correct explanation of A
| |
Both A and R are correct and R is the NOT correct explanation of A
| |
A is true but R is false
| |
A is false but R is true |
Question 12 |
If A={4n+2| n is natural number} and B={3n| n is a natural number}.
{12n2+6n | n is a natural number}
| |
{24 n-12| n is a natural number}
| |
{60n+30| n is a natural number}
| |
{12n-6| n is a natural number} |
Question 13 |
Given below are two statements: one is labelled as Assertion A and the other is labelled as Reason R
Assertion A: Validity checks real need of system users
Reason R: Completeness checks system user defined requirements
In the light of the above statements, choose the correct answer from the options given below
Assertion A: Validity checks real need of system users
Reason R: Completeness checks system user defined requirements
In the light of the above statements, choose the correct answer from the options given below
Both A and R are correct and R is the correct explanation of A
| |
Both A and R are correct and R is the NOT correct explanation of A
| |
A is true but R is false
| |
A is false but R is true |
Question 13 Explanation:
Both A and R are correct, but R is not the correct explanation of A.
Assertion A: This statement is correct. Validity checks are essential to ensure that the system meets the real needs and requirements of the system users.
Reason R: Completeness checks are indeed about verifying that the system user-defined requirements are fully captured, but this doesn't directly explain the concept of validity checks.
Both A and R are independently valid statements, but Reason R doesn't directly provide an explanation for Assertion A. So, the correct answer is:
Both A and R are correct, but R is not the correct explanation of A.
Question 14 |
Which of the following is not a solution representation in a genetic algorithm?
Binary valued
| |
Real valued
| |
Permutation
| |
Combinations |
Question 14 Explanation:
"Combinations" is not typically a direct solution representation in a genetic algorithm. In genetic algorithms, the common solution representations include:
Binary Valued: Where each gene in an individual is represented as a binary value (0 or 1).
Real Valued: Where each gene in an individual is represented as a real number, often within a specific range.
Permutation: Where the genes represent a permutation or ordering of elements. This is often used for problems like the Traveling Salesman Problem.
"Combinations" as a direct representation is not commonly used in genetic algorithms. Instead, it might be implemented using other representations like binary, real-valued, or permutation depending on the specific problem being solved.
Question 15 |
In the standard Ethernet with transmission rate of 10Mbps,assume that the length of the medium us 2500m and size of a frame is 512 bytes. The propagation speed of a signal in a cable is normally 2x108 m/s. The transmission delay and propagation delay are
25.25 microseconds and 51.2 microseconds
| |
51.2 microseconds and 12.5 microseconds
| |
10.24 microseconds and 50.12 microseconds
| |
12.5 microseconds and 51.2 microseconds |
Question 16 |
Which one of the following is Not a part of ACID properties of a database transaction?
Atomicity
| |
Consistency
| |
Isolation
| |
Deadlock-freedom
|
Question 16 Explanation:
"Deadlock-freedom" is not typically considered one of the ACID properties of a database transaction. The ACID properties include:
Atomicity: Transactions are treated as all-or-nothing units. Either all the changes are applied, or none of them are.
Consistency: A transaction should bring the database from one consistent state to another consistent state. It ensures that the integrity constraints and rules are not violated during the transaction.
Isolation: Transactions should be isolated from each other, meaning the operations within a transaction should not interfere with other concurrent transactions.
Durability: Once a transaction is committed, its changes are permanent and will survive system failures.
"Deadlock-freedom" is related to concurrency control mechanisms and techniques but is not typically considered one of the core ACID properties. It's concerned with avoiding situations where multiple transactions are waiting for each other, leading to a standstill in processing.
Question 17 |
Consider the following statements
A. C-fuzzy means cluster is supervised method of learning
B. PCA is used for dimension reduction
C. Apriori is not a supervised technique
D. When a machine learning model becomes so specially tuned to its exact input data that it fails to generalize to other similar data it is called underfitting
Choose the correct answer from the options given below
A. C-fuzzy means cluster is supervised method of learning
B. PCA is used for dimension reduction
C. Apriori is not a supervised technique
D. When a machine learning model becomes so specially tuned to its exact input data that it fails to generalize to other similar data it is called underfitting
Choose the correct answer from the options given below
A and B
| |
B and C
| |
C and D
| |
D and A
|
Question 17 Explanation:
Statement B is correct. PCA (Principal Component Analysis) is indeed used for dimension reduction in machine learning and data analysis.
Statement C is also correct. Apriori is a frequent itemset mining algorithm used in association rule learning and is not a supervised technique in machine learning.
Statements A and D are not correct:
Statement A is incorrect. "C-fuzzy" is not a standard term in machine learning, and the statement doesn't accurately describe a supervised method of learning.
Statement D is also incorrect. "Underfitting" is when a model is too simple and fails to capture the underlying patterns in data. It is the opposite of overfitting, which is when a model becomes too specialized to its training data.
Question 18 |
Given below are two statements: one is labeled as Assertion A and the other is labeled as Reason R
Assertion A: The AVL tree are more balanced as compared to Red black trees, but they may cause more rotations during insertions and deletion
Reason R: A Red Black tree with n nodes has height that is greater than 2 log2(n+1) and the AVL tree with n nodes has height less than log∅(√5(n+2))-2 (where ∅ is golden ratio)
In the light of the above statements, choose the correct answer from the options given below
Assertion A: The AVL tree are more balanced as compared to Red black trees, but they may cause more rotations during insertions and deletion
Reason R: A Red Black tree with n nodes has height that is greater than 2 log2(n+1) and the AVL tree with n nodes has height less than log∅(√5(n+2))-2 (where ∅ is golden ratio)
In the light of the above statements, choose the correct answer from the options given below
Both A and R are correct and R is the correct explanation of A
| |
Both A and R are correct and R is the NOT correct explanation of A
| |
A is true but R is false
| |
A is false but R is true
|
Question 18 Explanation:
A is true but R is false
Assertion A: This statement is correct. AVL trees are generally more balanced than Red-Black trees, which means their heights are closer to logarithmic. However, the insertion and deletion operations in AVL trees may cause more rotations compared to Red-Black trees.
Red-Black Tree Height: In a Red-Black tree, the height is guaranteed to be at most approximately 2 * log₂(n+1), where "n" is the number of nodes in the tree. It can be at most twice the height of a balanced tree, which is log₂(n+1). So, the statement correctly indicates that the height is "greater than 2 * log₂(n+1)."
AVL Tree Height: In an AVL tree, the height is guaranteed to be at most log∅(√5(n+2)) - 2, where "n" is the number of nodes in the tree. The golden ratio (∅) is approximately 1.618. So, the height of an AVL tree is less than log∅(√5(n+2)) - 2.
Question 19 |
Suppose a circular queue of capacity (n - 1) elements is implemented with an array of n elements. Assume that the insertion and deletion operations are carried out using REAR and FRONT as array index variables, respectively. Initially, REAR = FRONT = 0. The conditions to detect queue full and queue empty are
EMPTY: REAR == FRONT , FULL: (REAR+1) mod n == FRONT
| |
EMPTY: (FRONT+1) mod n == REAR,FULL: (REAR+1) mod n == FRONT
| |
EMPTY: (REAR+1) mod n == FRONT,FULL: REAR == FRONT
| |
EMPTY: REAR == FRONT,FULL: (FRONT+1) mod n == REAR empty
|
Question 19 Explanation:
The correct conditions are:
EMPTY: REAR == FRONT, FULL: (REAR + 1) mod n == FRONT
Question 20 |
Consider the rectangle with vertices (0,0),(0,2),(3,0),(3,2).There is a scaling of 2 towards the x-axis and 3 towards the y-axis. The new coordinates of the rectangle are
(0,0)(6,0)(0,4)(6,4)
| |
(0,0)(6,0)(0,4)(3,2)
| |
(0,0)(6,0)(0,6)(6,6)
| |
(0,0)(4,0)(0,6)(4,6) |
Question 20 Explanation:
To scale a rectangle by a factor of 2 along the x-axis and 3 along the y-axis, you can apply the scaling factor to each vertex individually. The scaling operation multiplies the x-coordinate by 2 and the y-coordinate by 3 for each vertex.
Given the original vertices of the rectangle:
(0, 0)
(0, 2)
(3, 0)
(3, 2)
After scaling, the new coordinates are:
(0 * 2, 0 * 3) = (0, 0)
(0 * 2, 2 * 3) = (0, 6)
(3 * 2, 0 * 3) = (6, 0)
(3 * 2, 2 * 3) = (6, 6)
So, the correct new coordinates of the rectangle after scaling are:
(0, 0) (0, 6) (6, 0) (6, 6)
The option that matches these coordinates is:
(0, 0) (0, 6) (6, 0) (6, 6)
Question 21 |
Consider the following finite automata F1 that accepts a language L
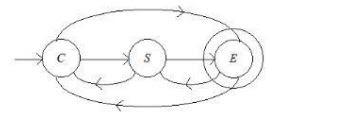
Let F2 be a finite automata which is obtained by reversal of F1.ten which of the following is correct?
Let F2 be a finite automata which is obtained by reversal of F1.ten which of the following is correct?
L(F1) ≠ L(F2)
| |
L(F1)=L(F2)
| |
L(F1) ≤ L(F2)
| |
L(F1) ≥ L(F2) |
Question 21 Explanation:
When a finite automaton F1 is reversed to obtain F2, the language accepted by F2 is the reverse of the language accepted by F1. In other words, if F1 accepts language L, then F2 accepts the language L reversed (the reverse of all strings in L)
Question 22 |
Consider the following statements about heap sort algorithm
A.The MAX-HEAPIFY procedure which runs in O lg(n) time, is the key to maintaining the max heap property
B. The BUILD-MAX-HEAP procedure which runs in O lg(n) time,produces max-heap from an unordered input array
C. The MAX-HEAP-INSERT, which runs in O(lg n) time, implements the insertion operation
D.The HEAP-INCREASE-KEY procedure runs in O(nlg n) time, to set the key of new node of its correct value
Choose the correct answer from the options given below
A.The MAX-HEAPIFY procedure which runs in O lg(n) time, is the key to maintaining the max heap property
B. The BUILD-MAX-HEAP procedure which runs in O lg(n) time,produces max-heap from an unordered input array
C. The MAX-HEAP-INSERT, which runs in O(lg n) time, implements the insertion operation
D.The HEAP-INCREASE-KEY procedure runs in O(nlg n) time, to set the key of new node of its correct value
Choose the correct answer from the options given below
A,B only
| |
A,C only
| |
B,D only
| |
A,B,C,D
|
Question 22 Explanation:
A. The statement "The MAX-HEAPIFY procedure which runs in O(log n) time, is the key to maintaining the max heap property" is correct.
B. The statement "The BUILD-MAX-HEAP procedure which runs in O(log n) time, produces a max-heap from an unordered input array" is incorrect. BUILD-MAX-HEAP typically runs in O(n) time, not O(log n) time. It's used to create a max-heap from an unordered array.
C. The statement "The MAX-HEAP-INSERT, which runs in O(log n) time, implements the insertion operation" is correct. MAX-HEAP-INSERT is used for inserting elements into a max-heap and typically runs in O(log n) time.
D. The statement "The HEAP-INCREASE-KEY procedure runs in O(n log n) time, to set the key of a new node to its correct value" is incorrect. HEAP-INCREASE-KEY usually runs in O(log n) time, not O(n log n) time.
So, the correct statements are A and C
Question 23 |
Given below are two statements:
Statement I: Fuzzifier is a part of a fuzzy system
Statement Ii: Inference engine is a part of fuzzy system
In the ligt of the above statements, choose the most appropriate answer from the options given below
Statement I: Fuzzifier is a part of a fuzzy system
Statement Ii: Inference engine is a part of fuzzy system
In the ligt of the above statements, choose the most appropriate answer from the options given below
Both statement I and Statement II are correct
| |
Both statement I and Statement II are incorrect
| |
Statement I is correct but Statement II is incorrect
| |
Statement I is incorrect but Statement II is correct |
Question 23 Explanation:
Statement I correctly identifies that a "fuzzifier" is a component of a fuzzy system. A fuzzifier is responsible for converting crisp (non-fuzzy) inputs into fuzzy sets.
Statement II is also correct because an "inference engine" is a crucial component of a fuzzy system. It's responsible for making decisions and performing reasoning based on fuzzy logic rules and inputs.
Both statements are accurate, and there is no conflict between them.
Question 24 |
Given below are two statements:
Statement I: If f and g are two functions and f=O(g) but g!=o(f), we say that the growth rate of g is smaller than that of f.
Statement Ii: The class of all decision problems decided by a TM in exponential time, that is O(2k), k being a constant
In the light of the above statements, choose the most appropriate answer from the options given below
Statement I: If f and g are two functions and f=O(g) but g!=o(f), we say that the growth rate of g is smaller than that of f.
Statement Ii: The class of all decision problems decided by a TM in exponential time, that is O(2k), k being a constant
In the light of the above statements, choose the most appropriate answer from the options given below
Both statement I and Statement II are correct
| |
Both statement I and Statement II are incorrect
| |
Statement I is correct but Statement II is incorrect
| |
Statement I is incorrect but Statement II is correct |
Question 25 |
Let R(A,B,C,D) be a relational schema with the following function dependencies
A->B,B->C
C->D and D->B
The decomposition of R into (A,B)(B,C)(B,D)
A->B,B->C
C->D and D->B
The decomposition of R into (A,B)(B,C)(B,D)
gives a lossless join, and is dependency preserving
| |
gives lossless join,but is not dependency preserving
| |
does not give a lossless join, but is dependency preserving
| |
does not give a lossless join, but is not dependency preserving
|
Question 25 Explanation:
The decomposition of a relational schema R into smaller schemas can be analyzed for lossless join and dependency preservation using the properties of functional dependencies. Let's break down the given functional dependencies:
A -> B
B -> C
C -> D
D -> B
Now, let's consider the decomposition of R into (A, B), (B, C), and (B, D).
Lossless Join:
For the decomposition to be lossless join, we need to check if the natural join of the decomposed schemas can reconstruct the original relation R.
(A, B) ∩ (B, C) = (B)
(B, C) ∩ (B, D) = (B)
Both intersections include the attribute B. So, joining (A, B), (B, C), and (B, D) together would reconstruct all attributes of R. Therefore, the decomposition gives a lossless join.
Dependency Preservation:
For the decomposition to be dependency preserving, it should be checked if all the original functional dependencies can be inferred from the functional dependencies in the decomposed schemas.
In (A, B):
A -> B (from the original dependencies)
In (B, C):
B -> C (from the original dependencies)
In (B, D):
D -> B (from the original dependencies)
All original functional dependencies can be inferred from the functional dependencies in the decomposed schemas. Therefore, the decomposition is dependency preserving.
So, the correct answer is:
The decomposition gives a lossless join and is dependency preserving.
There are 25 questions to complete.